Large language models such as Megatron and GPT-3 are transforming AI. We are excited about applications that can take advantage of these models to create better conversational AI. One main problem that generative language models have in conversational AI applications is their lack of controllability and consistency with real-world facts. In this work, we try to address this by making our large language models both controllable and consistent with an external knowledge base. Scaling language models provides increased fluency, controllability, and consistency.
Several attempts have been made to mitigate the consistency and controllability issues. Guan et al. (2020) introduced common sense knowledge through fine tuning to address consistency. However, this naive approach lacks interpretability and flexibility of deciding when and what to incorporate from an external knowledge base.
Controlling text generation has been a desirable functionality for many practical applications. Recently, different methods have been developed to control generation, such as the use of control codes prepended to the model input and conditioning it on the prior conversations of a target actor. However, these controlling conditions are predefined and limited in their capability. They lack control granularity such as at the sentence or sub-document level.
We addressed these shortcomings by allowing the dynamic incorporation of external knowledge into pretrained language models as well as control for text generation. We took advantage of our Megatron project, which aims to train the biggest transformer language models at the speed of light efficiency on GPU clusters. We propose a novel generation framework, Megatron-CNTRL, that makes our large Megatron language models controllable as well as consistent using an external knowledge base.
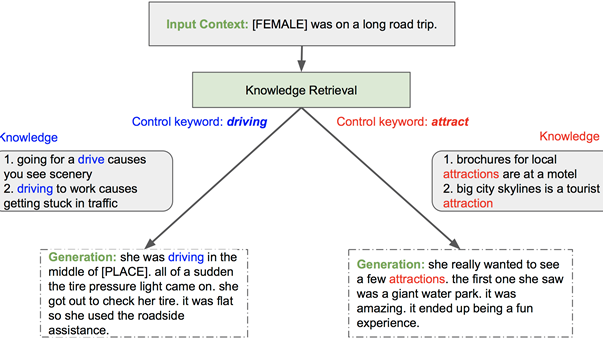
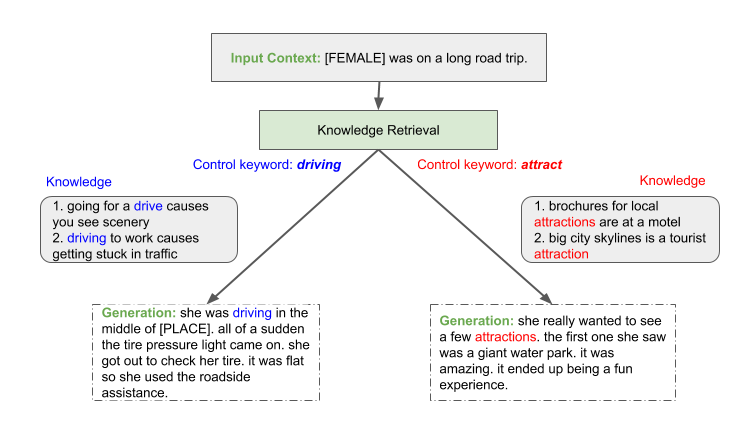
Using human evaluators through Mechanical Turk, we show that scaling language models provides increased fluency, controllability, and consistency, yielding more realistic generations. As a result, up to 91.5% of the generated stories are successfully controlled by the new keywords, and up to 93.0% of them are evaluated as consistent on ROC story datasets. We expect this trend to continue, motivating continued investment in training larger models for conversational AI. Figure 1 shows an example of the generative process.
Megatron-CNTRL framework
In the problem setup, we complete a story using the first sentence as input. We augment the generation process with an external knowledge base and develop a methodology that can guide and control the story generation. Figure 2 shows that the framework consists of the following connected steps:
- Given the story context, a keyword predictor model first predicts a set of keywords for the next sentence yet to be generated.
- A knowledge retriever then takes the generated keywords and queries an external knowledge base where each knowledge triple is converted into natural language “knowledge sentences” using templates.
- A contextual knowledge ranker then ranks the external knowledge sentences based on their relevance to the story context.
- Finally, a generator takes the story context, as well as the top-ranked knowledge sentences as input, and generates the next sentence in the story. The output sentence is appended to the story context and steps 1-4 are repeated.
This formulation naturally allows controllability by replacing the keyword generation process with manual external keywords.
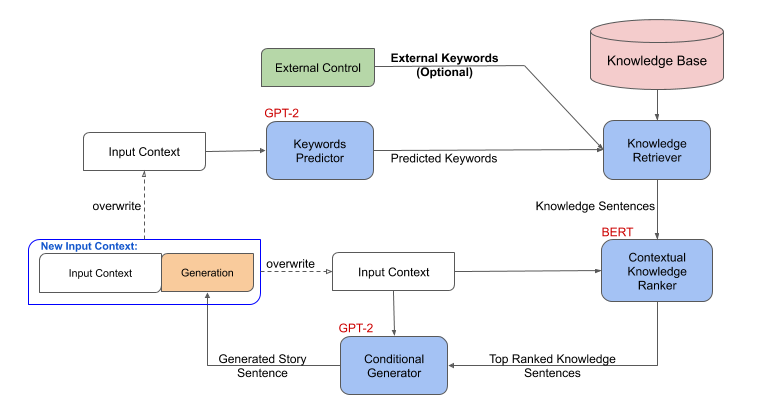
We model keyword generation as a sequence-to-sequence problem, which takes story context as input and output a sequence of keywords. We use the Megatron model (GPT-2–based) for keyword generation. The knowledge retriever is a simple model that matches keywords with a knowledge base. For the contextual knowledge ranker, we first build pseudo-labels to find the most relevant knowledge for the story context with a sentence embedding called USE. We then train a ranker from the Megatron model (BERT-based) to rank the knowledge filtered by knowledge retriever. The top-ranked knowledge is then appended to the end of the story context as the input to another conditional generator from the Megatron models to generate the next story sentence.
Experimental setup
We used the ROC story dataset for our experiments. It consists of 98,161 stories, where each story contains five sentences. Following Guan et al. (2020), for each sentence, delexicalization is performed by replacing all the names and entities in stories with special placeholders. Given the first sentence of each story, our model’s task is to generate the rest of the story. For the external knowledge base, we used ConceptNet, which consists of 600k knowledge triples. We used Megatron-LM for the pretrained BERT and GPT-2 models to initialize the contextual knowledge ranker and generative models, respectively. Both the keyword predictor and the conditional sentence generator follow the same settings.
Quality evaluation
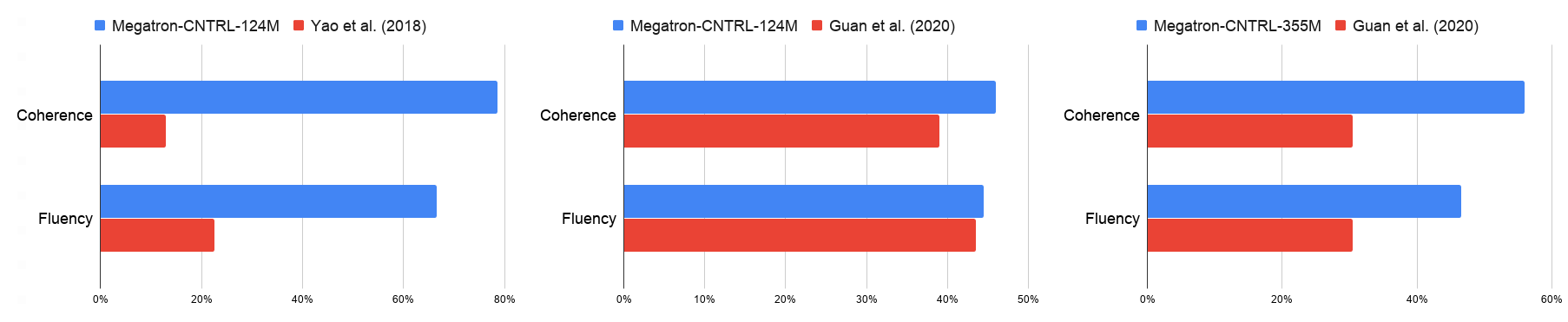
We evaluated the quality of the generated stories with automatic metrics of perplexity, story repetition, and distinct 4-gram, as well as human evaluations of consistency, coherence, and fluency. Comparing the Megatron-CNTRL-124M model to Yao et al. (2018) in Table 1 and Figure 3, we achieved much higher distinct 4-grams, coherence, fluency, and consistency scores, which shows the benefit of large, pretrained transformer models. Comparing Megatron-CNTRL-124M to Guan et al. (2020) (not controllable), which also uses a GPT-2 based model of the same size as shown in Table 1, we note that our model has significantly better coherence (+7.0%) and consistency (+7.5%). We attribute this to the use of the retrieved knowledge. By explicitly providing facts pertinent to the next sentence, the conditional generative model can focus on just generating text.
| Name | Perplexity | Story repetition | Distinct 4-gram | Consistency (human eval) |
| GPT-2-124M | 6.98 | 27.2 | 74.1 | 69.5 |
| Yao et al. 2018 | NA | 13.3 | 63.7 | 49.0 |
| Guan et al. 2020 | 7.04 | 22.1 | 77.1 | 67.0 |
| Megatron-CNTRL-124M | 9.37 | 20.0 | 80.1 | 74.5 |
| Megatron-CNTRL-8B | 6.21 | 21.2 | 82.8 | 93.0 |
As the model size increases from 124M to 355M, 774M, 2B, and 8B, we observed consistent improvements over perplexity, distinct, consistency, coherence, and fluency. This shows that scaling the model size further almost always improves the quality of generation. For consistency, our best model at 8B parameters achieves a score of 93%, which means that 93% of the generated stories are annotated as logically consistent.
Controllability evaluation
We evaluated the controllability of the model by first changing the keywords to their antonyms and then asking the annotators whether the generated stories changed according to the new keywords. The results in Table 2 show that 77.5% of the generation from Megatron-CNTRL-124M-ANT (which is the controlled version by changing keywords to their antonyms) are controlled by the new keywords. Scaling the generation model from 124M to 8B, we observe the controllability score rise to 91.5%, which shows that the large models significantly help with the controllability.
| Name | Controllability |
| Megatron-CNTRL-124M-ANT | 77.50% |
| Megatron-CNTRL-8B-ANT | 91.50% |
Samples of controllable generations
In the following examples, we demonstrate the capability of Megatron-CNTRL. We show controllability at different granular levels of generation. Given a sentence, Megatron-CNTRL proposes control keywords. The user can use them or can provide external control keywords of their choice. This process continues till the end of the entire story generation.
Example 1: We provide the sentence “[FEMALE] was on a road trip.” and the control keyword “driving” at the beginning. From this input, Megatron-CNTRL generates “she was driving down the road” conditioned on “driving”. Then the model predicts the new keywords “sudden” and “pulled, check” for the next two steps and generates the corresponding story sentences. Before generating the last sentence, we again provide the external control keyword “help”. We observe that the generated sentence, “it was smoking badly and needed help” follows the control keyword well.
Example 2: We give the same input sentence as in Example 1: “[FEMALE] was on a road trip.”, but a different control keyword “excited” at the beginning. Megatron-CNTRL therefore generates a new story sentence based on “excited”: “she is excited because she was finally seeing [FEMALE]”. After generating the full story, we see that the new example now illustrates a terrifying story about a huge black bear. It is more captivating than the one in Example 1 due to the emotional experience introduced by the external emotional control keywords.
Conclusion
Our work demonstrates the benefits of combining large, pretrained models with an external knowledge base and controllability of the generation. Our future work will be making the knowledge retriever learnable and introduce structure-level control for longer generations.
For more information, see our paper, Megatron-CNTRL: Controllable Story Generation with External Knowledge using Large-Scale Language Models and the related GTC Fall session.
