
In the fast-evolving landscape of generative AI, the demand for accelerated inference speed remains a pressing concern. With the exponential growth in model size and complexity, the need to swiftly produce results to serve numerous users simultaneously continues to grow. The NVIDIA platform stands at the forefront of this endeavor, delivering perpetual performance leaps through innovations across the full technology stack—chips, systems, software, and algorithms.
NVIDIA is expanding its inference offerings with NVIDIA TensorRT Model Optimizer, a comprehensive library of state-of-the-art post-training and training-in-the-loop model optimization techniques. These techniques include quantization and sparsity to reduce model complexity, enabling downstream inference libraries like NVIDIA TensorRT-LLM to more efficiently optimize the inference speed of deep learning models.
Part of the NVIDIA TensorRT ecosystem, NVIDIA TensorRT Model Optimizer (referred to as Model Optimizer) is available on popular architectures, including NVIDIA Hopper, NVIDIA Ampere, and NVIDIA Ada Lovelace.
Model Optimizer generates simulated quantized checkpoints for PyTorch and ONNX models. These quantized checkpoints are ready for seamless deployment to TensorRT-LLM or TensorRT, with support for other popular deployment frameworks forthcoming. The Model Optimizer Python APIs enable developers to stack different model optimization techniques to accelerate inference on top of existing runtime and compiler optimizations in TensorRT.

Quantization techniques
Post-training quantization (PTQ) is one of the most popular model compression methods to reduce memory footprint and accelerate inference. While some other quantization toolkits only support weight-only quantization or basic techniques, Model Optimizer provides advanced calibration algorithms including INT8 SmoothQuant and INT4 AWQ (Activation-aware Weight Quantization). If you’re using FP8 or lower precisions such as INT8 or INT4 in TensorRT-LLM, you’re already leveraging Model Optimizer’s PTQ under the hood.
Over the past year, Model Optimizer’s PTQ has already empowered countless TensorRT-LLM users to achieve notable inference speedups for LLMs while preserving model accuracy. Leveraging INT4 AWQ, a Falcon 180B can fit onto a single NVIDIA H200 GPU. Figure 1 demonstrates the inference speedup users can achieve with Model Optimizer PTQ on a Llama 3 model.

Latency measured without inflight batching. Speedup is normalized to the GPU count
Without quantization, diffusion models can take up to a second to generate an image, even on a NVIDIA A100 Tensor Core GPU, impacting the end user’s experience. The leading 8-bit (INT8 and FP8) post-training quantization from Model Optimizer has been used under the hood of TensorRT’s diffusion deployment pipeline and Stable Diffusion XL NIM to speed up image generation.
In MLPerf Inference v4.0, Model Optimizer further supercharged TensorRT to set the bar for Stable Diffusion XL performance higher than all alternative approaches. This 8-bit quantization feature has enabled many generative AI companies to deliver user experiences with faster inference with preserved model quality.
To see an end-to-end example for both FP8 and INT8, visit NVIDIA/TensorRT-Model-Optimizer and NVIDIA/TensorRT on GitHub. Depending on the size of the calibration dataset, the calibration process for diffusion models usually takes just a few minutes. For FP8, we observed a 1.45x speedup on RTX 6000 Ada and 1.35x on a L40S without FP8 MHA. Table 1 shows a supplementary benchmark of INT8 and FP8 quantization.
| GPU | INT8 latency (ms) | FP8 latency (ms) | Speedup (INT8 vs FP16) | Speedup (FP8 vs FP16) |
| RTX 6000 Ada | 2,479 | 2,441 | 1.43x | 1.45x |
| RTX 4090 | 2,058 | 2,161 | 1.20x | 1.14x |
| L40S | 2,339 | 2,168 | 1.25x | 1.35x |
Configuration: Stable Diffusion XL 1.0 base model. Image resolution=1024×1024; 30 steps. TensorRT v9.3. Batch size=1

Enabling ultra-low precision inference for next-generation platforms
The recently announced NVIDIA Blackwell platform powers a new era of computing with 4-bit floating point AI inference capabilities. Model Optimizer plays a pivotal role in enabling 4-bit inference while upholding model quality. When moving toward 4-bit inference, post-training quantization typically results in a nontrivial accuracy drop.
To address this, Model Optimizer provides Quantization Aware Training (QAT) for developers to fully unlock inference speed up with 4-bit without compromising accuracy. By computing scaling factors during training and incorporating simulated quantization loss into the fine-tuning process, QAT makes the neural network more resilient to quantization.
The Model Optimizer QAT workflow is designed to integrate with leading training frameworks, including NVIDIA NeMo, Megatron-LM, and Hugging Face Trainer API. This provides developers with the option to harness the capabilities of the NVIDIA platform across a variety of frameworks. If you’d like to get started with QAT before the NVIDIA Blackwell platform is available, follow the INT4 QAT example with the Hugging Face Trainer API.
Our study shows that QAT can achieve better performance than PTQ at low precisions, even if QAT is only applied at the supervised fine-tuning (SFT) stage instead of the pretraining stage. This implies that QAT can be applied with a low training cost, enabling generative AI applications that are sensitive to accuracy drop to preserve accuracy even at ultra-low precisions where both weight and activations are 4-bit in the near future.
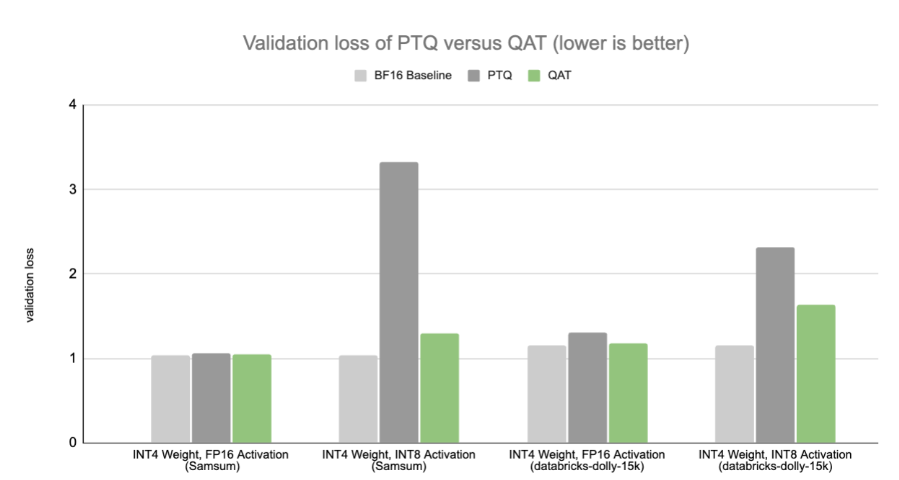
The baseline is fine-tuned on the target dataset. Note that we use INT4 to demonstrate QAT in this benchmark. The 4-bit results will become available with the general release of the NVIDIA Blackwell platform
Model compression with sparsity
Deep learning models are traditionally dense and over-parameterized. This drives the need for another family of model optimization techniques. Sparsity further reduces the size of models by selectively encouraging zero values in model parameters that can then be discarded from storage or computations.
The Model Optimizer post-training sparsity provides an additional 1.62x speedup at batch size 32 on top of FP8 quantization for Llama 2 70B. This used one NVIDIA H100 GPU with the proprietary NVIDIA 2:4 sparsity introduced in the NVIDIA Ampere architecture. To learn more, see Accelerating Inference with Sparsity Using the NVIDIA Ampere Architecture and NVIDIA TensorRT.
In MLPerf Inference v4.0, TensorRT-LLM uses the Model Optimizer post-training sparsity to compress Llama 2 70B by 37%. This enables the model and the KV cache to fit into the GPU memory of a single H100 GPU, with tensor parallelism degree reduced from two to one. In this particular summarization task in MLPerf, Model Optimizer preserves the quality of the sparsified model, meeting the 99.9% accuracy target on Rouge scores set by the MLPerf closed division.
| Model | Batch_size | Inference speedup (compared to the FP8 dense model with the same batch size) |
Sparsified Llama 2 70B | 32 | 1.62x |
| 64 | 1.52x | |
| 128 | 1.35x | |
| 896 | 1.30x |
FP8: TP=1, PP=1 for all sparsified models. The dense model needs TP=2 due to larger weight sizes
While there is almost no accuracy degradation in the MLPerf setting, in most cases, it’s a common practice to combine sparsity with fine-tuning to preserve model quality. Model Optimizer offers APIs for sparsity-aware fine-tuning that are compatible with popular parallelism techniques including FSDP. Figure 4 shows that using SparseGPT with fine-tuning can minimize loss degradation.

Composable model optimization APIs
Applying different optimization techniques, such as quantization and sparsity, on a model traditionally requires a nontrivial multistage approach. To address this pain point, Model Optimizer offers composable APIs for developers to stack multiple optimization steps. The code snippet in Figure 5 demonstrates how to combine sparsity and quantization with the Model Optimizer composable APIs.

Additionally, Model Optimizer comes with a variety of useful features such as one-line APIs to retrieve model state information and fully restore model modifications for any experiments that require full reproducibility.
Get started
NVIDIA TensorRT Model Optimizer is now available for installation on NVIDIA PyPI as nvidia-modelopt. To access example scripts and recipes for inference optimization, visit NVIDIA/TensorRT-Model-Optimizer on GitHub. For more details, see the TensorRT Model Optimizer documentation.
Acknowledgments
A special thanks to the dedicated engineers behind the development of TensorRT Model Optimizer including Asma Kuriparambil Thekkumpate, Kai Xu, Lucas Liebenwein, Zhiyu Cheng, Riyad Islam, Ajinkya Rasane, Jingyu Xin, Wei-Ming Chen, Shengliang Xu, Meng Xin, Ye Yu, Chen-han Yu, Keval Morabia, Asha Anoosheh, and James Shen. (Order does not reflect contribution level.)
