NVIDIA TensorRT™ is a high-performance deep learning inference optimizer and runtime that delivers low latency, high-throughput inference for deep learning applications. NVIDIA released TensorRT last year with the goal of accelerating deep learning inference for production deployment.
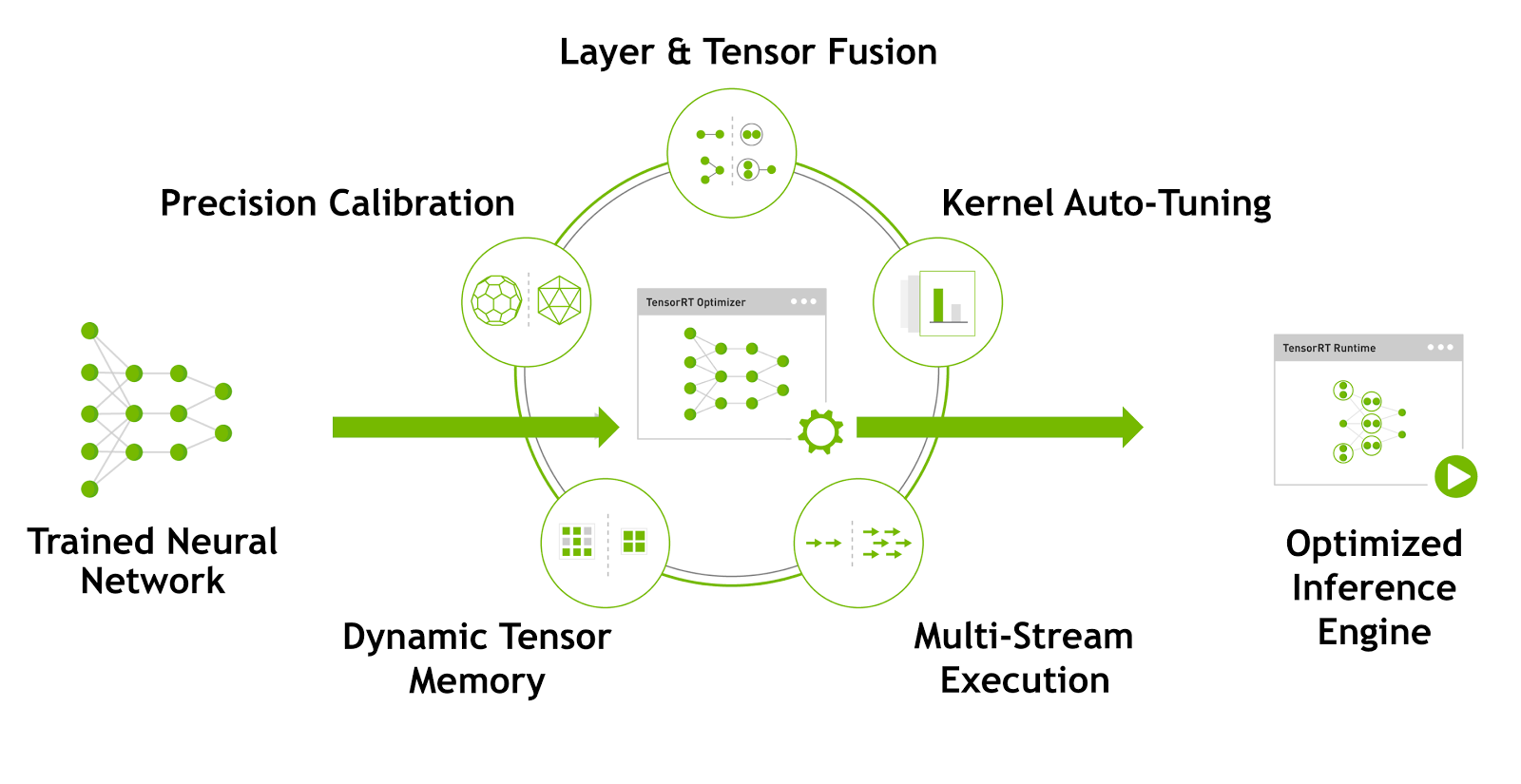 A new NVIDIA Developer Blog post introduces TensorRT 3, which improves performance over previous versions and adds new features that make it easier to use. Key highlights of TensorRT 3 include:
A new NVIDIA Developer Blog post introduces TensorRT 3, which improves performance over previous versions and adds new features that make it easier to use. Key highlights of TensorRT 3 include:
- TensorFlow Model Importer: a convenient API to import, optimize and generate inference runtime engines from TensorFlow trained models;
- Python API: an easy to use use Python interface for improved productivity;
- Volta Tensor Core Support: delivers up to 3.7x faster inference performance on Tesla V100 vs. Tesla P100 GPUs.
The post takes a deep dive into the TensorRT workflow using a code example. It covers importing trained models into TensorRT, optimizing them and generating runtime inference engines which can be serialized to disk for deployment. It also shows how to load serialized runtime engines and run fast and efficient inference in production applications. The post is accompanied by complete example Python notebooks.
Read more >