
Speech AI is the technology that makes it possible to communicate with computer systems using your voice. Commanding an in-car assistant or handling a smart home device? An AI-enabled voice interface helps you interact with devices without having to type or tap on a screen.

The field of speech AI is relatively new. But as voice interaction matures and expands to new devices and platforms, it’s important for developers to keep up with the evolving terminology.
In this explainer, I present key concepts from the world of speech AI, describe where it is situated in the bigger universe of AI, and discuss how it relates to other fields of science and technology.
Foundational concepts
You might have heard of, or even be familiar with these technologies but for the sake of completeness, here are the basics:
- Artificial intelligence (AI) refers to the broad discipline of creating intelligent machines that either match or exceed human-level cognitive abilities.
- Machine learning (ML) is a subfield of AI that involves creating methods and systems that learn how to carry out specific tasks using past data.
- Deep learning (DL) is a family of ML methods based on artificial neural networks with many layers and usually trained with massive amounts of data.
How are speech AI systems related to AI, ML, and DL?
Speech AI is the use of AI for voice-based technologies. Core components of a speech AI system include:
- An automatic speech recognition (ASR) system, also known as speech-to-text, speech recognition, or voice recognition. This converts the speech audio signal into text.
- A text-to-speech (TTS) system, also known as speech synthesis. This turns a text into a verbal, audio form.
Speech AI is a subfield within conversational AI, drawing its techniques primarily from the fields of DL and ML. The relationship between AI, ML, DL, and speech AI can be represented by the Venn diagram in Figure 1.
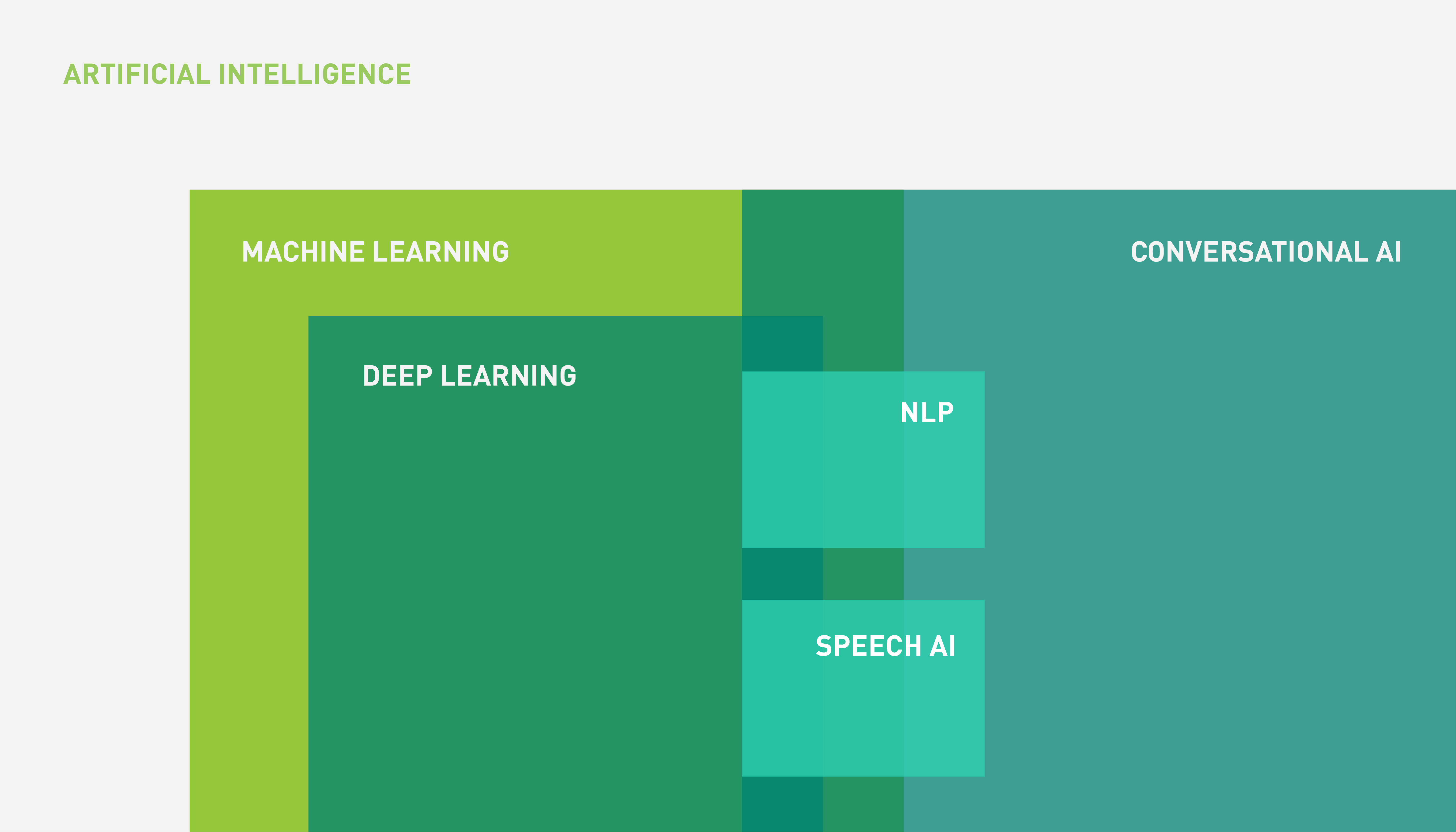
Figure 1 shows that conversational AI is the larger universe of language-based applications, of which not all include a voice component (speech).
Here’s how speech AI technologies work side by side with other tools and techniques to form a complete conversational AI system.
Conversational AI
Conversational AI is the discipline that involves designing intelligent systems capable of interacting with human users through natural language in a conversational fashion. Commercial examples include home assistants and chatbots (for example, an insurance claim chatbot or travel agent chatbot).
There can be multiple modalities for conversation, including audio, text, and sign language but when the input and output are spoken natural language, you have a voice-based conversational AI system (Figure 2).
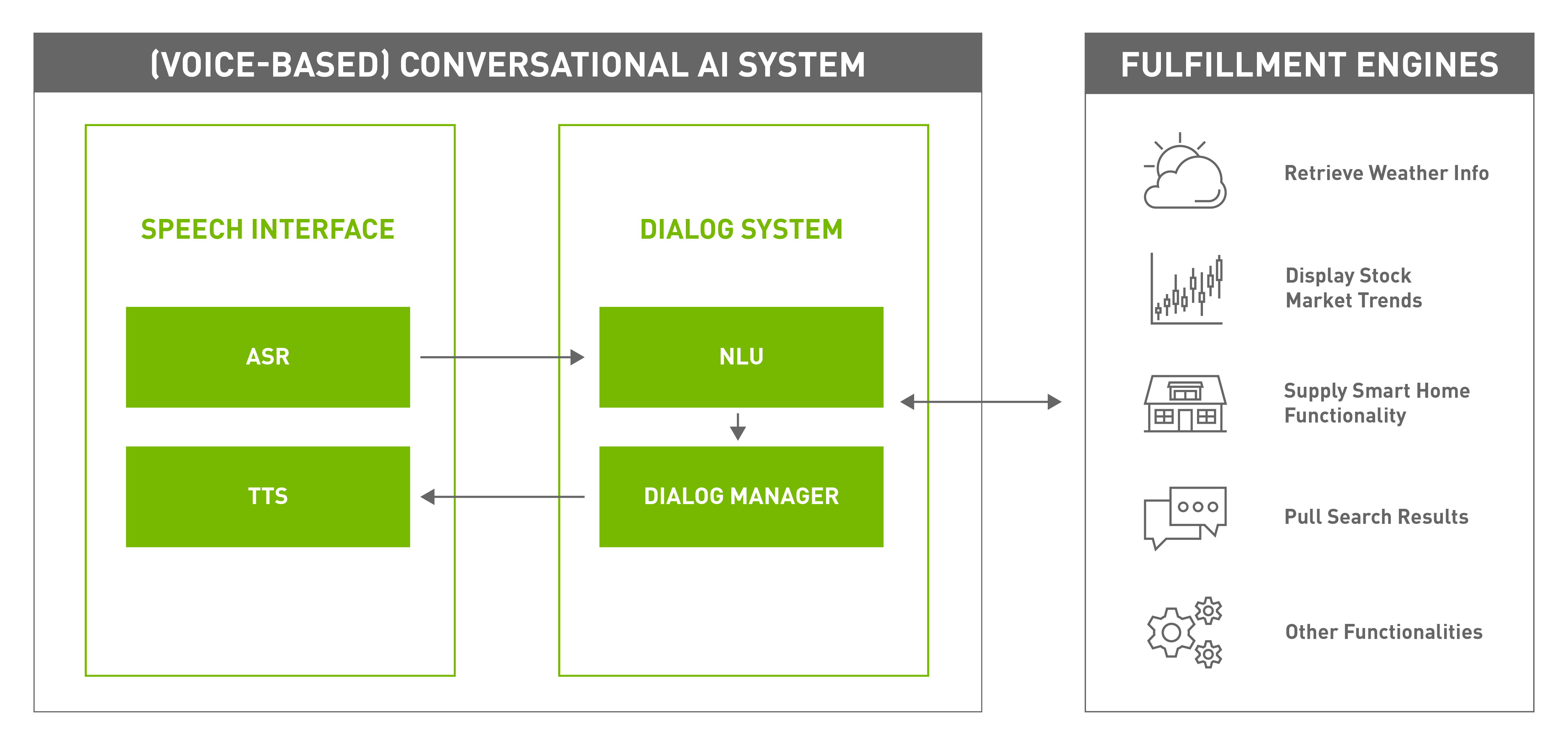
The components of a typical voice-based conversational AI system include the following:
- Speech interface
- Dialog system
- Fulfillment engine
Speech interface
A speech interface, enabled by speech AI technologies, enables the system to interact with users through a spoken natural-language format.
Dialog system
A dialog system manages the conversation with the user while interacting with external fulfillment systems to satisfy the user’s needs. It consists of two components:
- A natural language understanding (NLU) module parses the text and identifies relevant information, such as the intent of the user, and any relevant parameter to that intent. For example, if the user is requesting, “What’s the weather tomorrow morning?”, then “weather information” is the intent, while time is a relevant parameter to extract from the request, which is “tomorrow morning” in this case.
- NLU is part of natural language processing (NLP), a subfield of linguistics and artificial intelligence concerned with computational methods to process and analyze natural language data.
- A dialog manager monitors the state of the conversation and decides which action to take next. The dialog manager takes information from the NLU module, remembers the context, and fulfills the user’s request.
Fulfillment engines
The fulfillment engines execute the tasks that are functional to the conversational AI system, for instance: retrieving weather information, reading news, booking tickets, providing stock market information, answering trivia Q&A and much more.
In general, they are not considered part of the conversational AI system, but work closely together to satisfy the user’s needs.
Speech AI concepts
In this section, we dive into concepts specific to speech AI: automatic speech recognition and text-to-speech.
Automatic speech recognition
A typical deep learning-based ASR pipeline includes five main components (Figure 3).
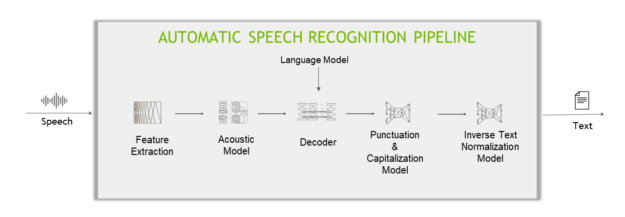
Feature extractor
A feature extractor segments the audio signal into fixed-length blocks (aka. time step) and then converts the blocks from the temporal domain to the frequency domain.
Acoustic model
This machine learning model (usually a multi-layer deep neural network) predicts the probabilities over characters at each time step of the audio data.
Decoder and language model
A decoder converts the matrix of probabilities given by the acoustic model into a sequence of characters, which in turn make words and sentences.
A language model (LM) can give a score indicating the likelihood of a sentence appearing in its training corpus. For example, an LM trained on an English corpus will judge “Recognize speech” as more likely than “Wreck a nice peach,” while also judging “Je suis un étudiant” as quite unlikely (for that being a French sentence).
When coupled with an LM, a decoder would be able to correct what it “hears” (“I’ve got rose beef for lunch”) to what makes more common sense (“I’ve got roast beef for lunch”), for the LM will give a higher score for the latter sentence than the former.
Punctuation and capitalization model
The punctuation and capitalization model adds punctuations and capitalizes the decoder-produced text.
Inverse text normalization model
Lastly, inverse text normalization (ITN) rules are applied to transform the text in verbal format into a desired written format, for example, “ten o’clock” to “10:00,” or “ten dollars” to “$10”.
Other ASR concepts
Word error rate (WER) and character error rate (CER) are typical performance metrics of ASR systems.
WER is the number of errors divided by the total number of spoken words. For example, if there are five errors in a total of 50 spoken words, the WER would be 25%.
CER operates similarly except on characters instead of words. Languages like Japanese and Mandarin do not have “words” separated by a specific marker or delimiter (like spaces for English).
For more information about domain-specific challenges such as handling dialects, see Solving Automatic Speech Recognition Deployment Challenges.
Text-to-speech (TTS)
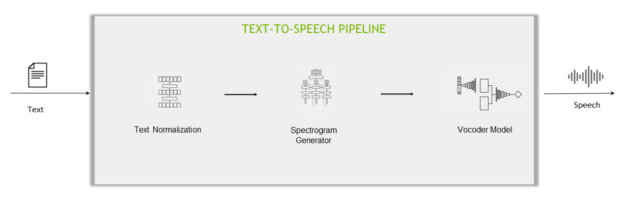
The Text-to-speech step is commonly achieved using two different approaches:
- A two-stage pipeline: Two separate networks are trained separately for converting speech-to-text: the spectrogram generator network and the vocoder network.
- An end-to-end pipeline: Uses one model to generate audio straight from text.
The components of a two-state pipeline are:
- Text normalization model: Transforms the text in written format into a verbal format, for example, “10:00” to “ten o’clock”, “$10” to “ten dollars”. This is the opposite process of ITN.
- Spectrogram generator network: The first stage of the TTS pipeline uses a neural network to generate a spectrogram from text.
- Vocoder network: The second stage of the TTS pipeline takes the spectrogram from the spectrogram generator network as an input and generates a natural-sounding speech.
Speech Synthesis Markup Language
Other TTS concepts include Speech Synthesis Markup Language (SSML), which is an XML-based markup language that lets you specify how input text is converted into synthesized speech. Your configuration can make the generated synthetic speech more expressive using parameters such as pitch, pronunciation, speaking rate, and volume.
Common SSML tags include the following:
- Prosody is used to customize the pitch, speaking rate, and volume of the generated speech.
- Phoneme is used to override manually the pronunciation of words in the generated synthetic voice.
Mean opinion score
To assess the quality of TTS engines, Mean opinion score (MOS) is frequently used. Originating from the telecommunications field, MOS is defined as the arithmetic mean over ratings given by human evaluators for a provided stimulus in a subjective quality evaluation test.
For example, a common TTS evaluation setup would be a group of people listening to generated samples and giving each sample a score from 0 to 5. MOS is then calculated as the average score of overall evaluators and test samples.
How to get started with speech AI
Speech AI has nowadays become mainstream and an integral part of consumers’ everyday life. Businesses are discovering new ways of bringing added value to their products by incorporating speech AI capabilities.
The best way to gain expertise in speech AI is to experience it. For more information about how to build and deploy real-time speech AI pipelines for your conversational AI application, see the free Building Speech AI Applications ebook (registration required).
