
Artificial intelligence (AI) has transformed synthesized speech from monotone robocalls and decades-old GPS navigation systems to the polished tone of virtual assistants in smartphones and smart speakers.
It has never been so easy for organizations to use customized state-of-the-art speech AI technology for their specific industries and domains.
Speech AI is being used to power virtual assistants, scale call centers, humanize digital avatars, enhance AR experiences, and provide a frictionless medical experience for patients by automating clinical note-taking.
According to Gartner Research, customers will prefer using speech interfaces to initiate 70% of self-service customer interactions (up from 40% in 2019) by 2023. The demand for personalized and automated experiences only continues to grow.
In this post, I discuss speech AI, how it works, the benefits of voice recognition technology, and examples of speech AI use cases.

What is speech AI, and what are the benefits?
Speech AI uses AI for voice-based technologies: automatic speech recognition (ASR), also known as speech-to-text, and text-to-speech (TTS). Examples include automatic live captioning in virtual meetings and adding voice-based interfaces to virtual assistants.
Similarly, language-based applications such as chatbots, text analytics, and digital assistants use speech AI as part of larger applications or systems, alongside natural language processing (NLP). For more information, see the Conversational AI glossary.

There are many benefits of speech AI:
- High availability: Speech AI applications can respond to customer calls during and outside of human agent hours, allowing contact centers to operate more efficiently.
- Real-time insights: Real-time transcripts are dictated and used as inputs for customer-focused business analyses such as sentiment analysis, customer experience analysis, and fraud detection.
- Instant scalability: During peak seasons, speech AI applications can automatically scale to handle tens of thousands of requests from customers.
- Enhanced experiences: Speech AI improves customer satisfaction by reducing holding times, quickly resolving customer queries, and providing human-like interactions with customizable voice interfaces.
- Digital accessibility: From speech-to-text to text-to-speech applications, speech AI tools are helping those with reading and hearing impairments to learn from generated spoken audio and written text.
Who is using speech AI and how?
Today, speech AI is revolutionizing the world’s largest industries such as finance, telecommunications, and unified communication as a service (UCaaS).

Companies starting out with deep-learning, speech-based technologies and mature companies augmenting existing speech-based conversational AI platforms benefit from speech AI.
Here are some specific examples of speech AI driving efficiencies and business outcomes.
Call center transcription
About 10 million call center agents are answering 2 billion phone calls daily worldwide. Call center use cases include all of the following:
- Trend analysis
- Regulatory compliance
- Real-time security or fraud analysis
- Real-time sentiment analysis
- Real-time translation
For example, automatic speech recognition transcribes live conversations between customers and call center agents for text analysis, which is then used to provide agents with real-time recommendations for quickly resolving customer queries.
Clinical note taking
In healthcare, speech AI applications improve patient access to medical professionals and claims representatives. ASR automates note-taking during patient-physician conversations and information extraction for claims agents.
Virtual assistants
Virtual assistants are found in every industry enhancing user experience. ASR is used to transcribe an audio query for a virtual assistant. Then, text-to-speech generates the virtual assistant’s synthetic voice. Besides humanizing transactional situations, virtual assistants also help the visually impaired interact with non-braille texts, the vocally challenged to communicate with individuals, and children to learn how to read.
How does speech AI work?
Speech AI uses automatic speech recognition and text-to-speech technology to provide a voice interface for conversational applications. A typical speech AI pipeline consists of data preprocessing stages, neural network model training, and post-processing.
In this section, I discuss these stages in both ASR and TTS pipelines.
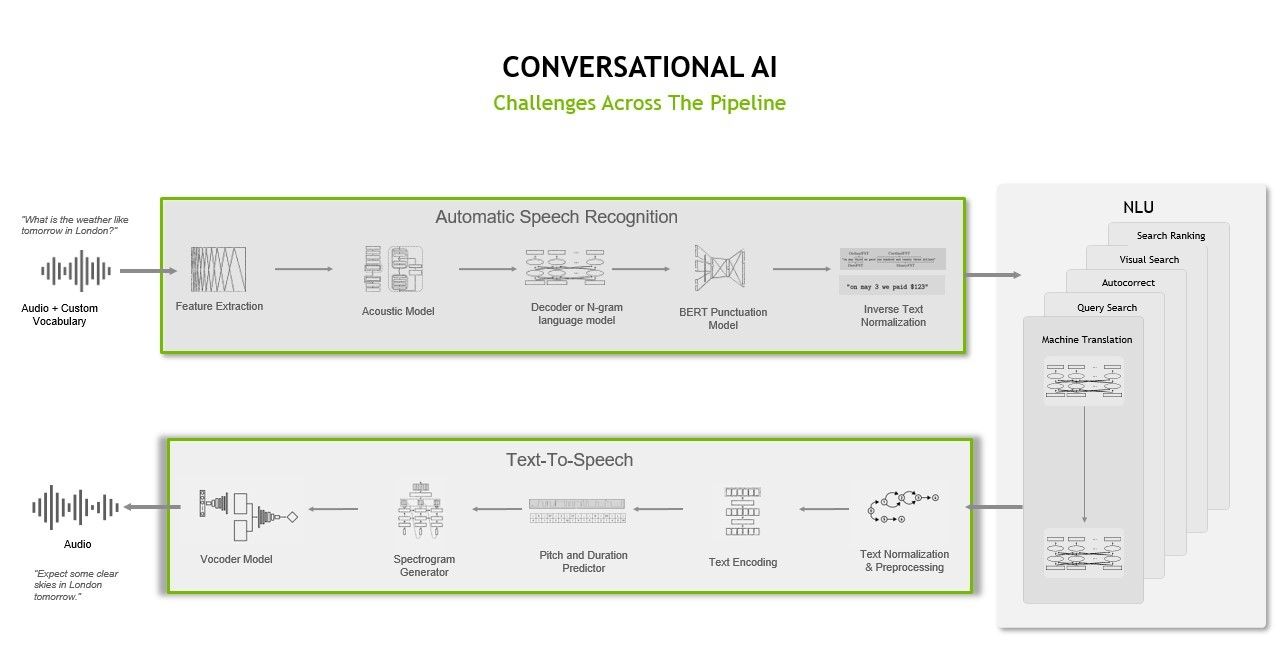
Automatic speech recognition
For machines to hear and speak with humans, they need a common medium for translating sound into code. How can a device or an application “see” the world through sound?
An ASR pipeline processes and transcribes a given raw audio file containing speech into corresponding text while minimizing a metric known as the word error rate (WER).
WER is used to measure and compare performance between types of speech recognition systems and algorithms. It is calculated by the number of errors divided by the number of words in the clip being transcribed.
ASR pipelines must accomplish a series of tasks, including feature extraction, acoustic modeling, as well as language modeling.
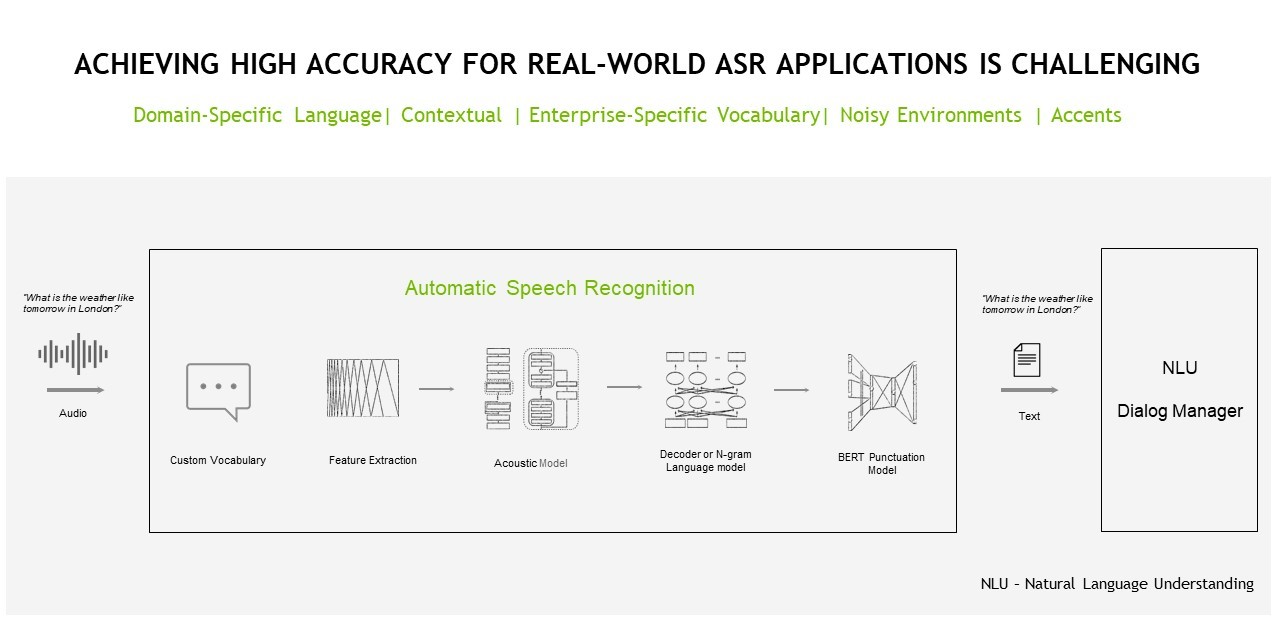
The feature extraction task involves converting raw analog audio signals into spectrograms, which are visual charts that represent the loudness of a signal over time at various frequencies and resemble heat maps. Part of the transformation process involves traditional signal preprocessing techniques like standardization and windowing.
Acoustic modeling is then used to model the relationship between the audio signal and the phonetic units in the language. It maps an audio segment to the most likely distinct unit of speech and corresponding characters.
The final task in an ASR pipeline involves language modeling. A language model adds contextual representation and corrects the acoustic model’s mistakes. In other words, when you have the characters from the acoustic model, you can convert these characters to sequences of words, which can be further processed into phrases and sentences.
Historically, this series of tasks was performed using a generative approach that required using a language model, pronunciation model, and acoustic model to translate pronunciations to audio waveforms. Then, either a Gaussian mixture model or hidden Markov model would be used to try to find the words that most likely match the sounds from the audio waveform.
This statistical approach was less accurate and more intensive in both time and effort to implement and deploy. This was especially true when trying to ensure that each time step of the audio data matched the correct output of characters.
However, end-to-end deep learning models, like connectionist temporal classification (CTC) models and sequence-to-sequence models with attention, can generate the transcript directly from the audio signal and with a lower WER.
In other words, deep learning-based models like Jasper, QuartzNet, and Citrinet enable companies to create less expensive, more powerful, and more accurate speech AI applications.
Text-to-speech
A TTS or speech synthesis pipeline is responsible for converting text into natural-sounding speech that is artificially produced with human-like intonation and clear articulation.
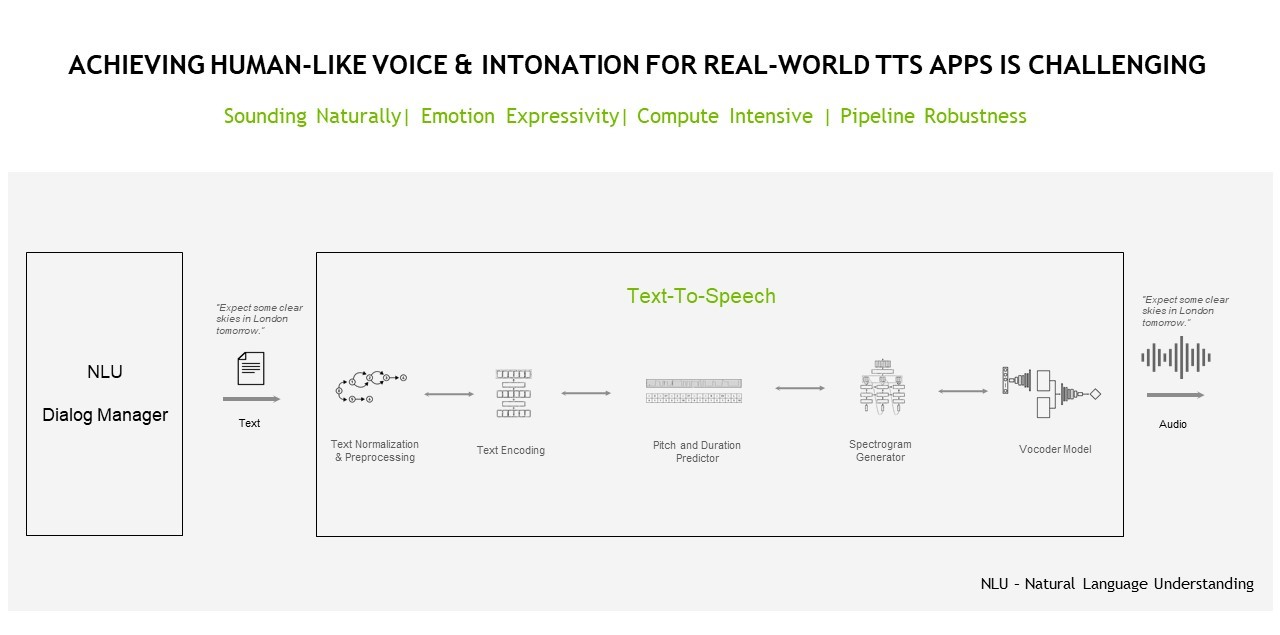
TTS pipelines potentially must accomplish a number of different tasks, including text analysis, linguistic analysis, and waveform generation.
During the text analysis stage, raw text (with symbols, abbreviations, and so on) is converted into full words and sentences, expanding abbreviations, and analyzing expressions. The output is passed into linguistic analysis for refining intonation, duration, and otherwise understanding grammatical structure. As a result, a spectrogram or mel-spectrogram is produced to be converted into continuous human-like audio.
The preceding approach that I walked through is a typical two-step process requiring a synthesis network and a vocoder network. These are two separate networks trained for the subsequent purposes of generating a spectrogram from text (using a Tacotron architecture or FastPitch) and generating audio from the spectrogram or other intermediate representation (like WaveGlow or HiFiGAN).
As well as the two-stage approach, another possible implementation of a TTS pipeline involves using an end-to-end deep learning model that uses a single model to generate audio straight from the text. The neural network is trained directly from text-audio pairs without depending on intermediate representations.
The end-to-end approach decreases complexity as it reduces error propagation between networks, mitigates the need for separate training pipelines, and minimizes the cost of manual annotation of duration information.
Traditional TTS approaches also tend to result in more robotic and unnatural-sounding voices that affect user engagement, particularly with consumer-facing applications and services.
Challenges in building a speech AI system
Successful speech AI applications must enable the following functionality.
Access to state-of-the-art models
Creating highly trained and accurate deep learning models from scratch is costly and time-consuming.
By providing access to cutting-edge models as soon as they’re published, even data and resource-constrained companies can use highly accurate, pretrained models and transfer learning in their products and services out-of-the-box.
High accuracy
To be deployed globally or to any industry or domain, models must be customized to account for multiple languages (a fraction of the 6,500 spoken languages in the world), dialects, accents, and contexts. Some domains use specific terminology and technical jargon.
Real-time performance
Pipelines consisting of multiple deep learning models must run inferences in milliseconds for real-time interactivity, precisely far less than 300 ms, as most users start to notice lags and communication breakdowns around 100 ms, preceding which conversations or experiences begin to feel unnatural.
Flexible and scalable deployment
Companies require different deployment patterns and may even require a mix of cloud, on-premises, and edge deployment. Successful systems support scaling to hundreds of thousands of concurrent users with fluctuating demand.
Data ownership and privacy
Companies should be able to implement the appropriate security practices for their industries and domains, such as safe data processing on-premises or in an organization’s cloud. For example, healthcare companies abiding by HIPAA or other regulations may be required to restrict access to data and data processing.
The future of speech AI
Thanks to advancements in computing infrastructure, speech AI algorithms, increased demand for remote services, and exciting new use cases in existing and emerging industries, there is now a robust ecosystem and infrastructure for speech AI-based products and services.
As powerful as the current applications of speech AI are in driving business outcomes, the next generation of speech AI applications must be equipped to handle multi-language, multi-domain, and multi-user conversations.
Organizations that can successfully integrate speech AI technology into their core operations will be well-equipped to scale their services and offerings for use cases yet to be listed.
Learn how your organization can deploy speech AI by checking out the free ebook, Building Speech AI Applications.
