
Successfully deploying an automatic speech recognition (ASR) application can be a frustrating experience. For example, it is difficult for an ASR system to correctly identify words while maintaining low latency, considering the many different dialects and pronunciations that exist.

Whether you are using a commercial or open-source solution, there are many challenges to consider when building an ASR application.
In this post, I highlight major pain points that developers face when adding ASR capabilities to applications. I share how to approach and overcome these challenges, using NVIDIA Riva speech AI SDK as an example.
Challenges of building ASR applications
Here are a few challenges present in the creation of any ASR system:
- High accuracy
- Low latency
- Compute resource allocation
- Flexible deployment and scalability
- Customization
- Monitoring and tracking
High accuracy
One key metric to measure speech recognition accuracy is the word error rate (WER). WER is defined as the ratio of total incorrect and missing words identified during transcription and the sum of the total number of words present in the labeled transcripts.
Several reasons cause transcription errors in ASR models leading to misinterpretations of information:
- Quality of the training dataset
- Different dialects and pronunciations
- Accents and variations in speech
- Custom or domain-specific words and acronyms
- Contextual relationship of words
- Differentiating phonetically similar sentences
Due to these factors, it is difficult to build a robust ASR model with a low WER score.
Low latency
A conversational AI application is an end-end pipeline composed of speech AI and natural language processing (NLP).
For any conversational AI application, response time plays a critical factor to make any natural conversations. It would not be practical to converse with a bot if a customer only receives a response after 1 minute of waiting time.
It has been observed that any conversation AI application should deliver a latency of less than 300 msec. So, it becomes critical to make sure that speech AI model latency is far below the 300 msec limit to be integrated into an end-end pipeline for real-time conversational AI applications.
Many factors affect the overall latency of the ASR model:
- Model size: Large and complex models have better accuracy but require a lot of computation power and add to the latency compared to smaller models; that is, the inference cost is high.
- Hardware: Edge deployment of such complex models further adds to the complexity of latency requirements.
- Network bandwidth: Sufficient bandwidth is needed for streaming audio content and transcripts, especially in the case of cloud-based deployment.
Compute resource allocation
Optimizing the ASR model and its resource utilizations applies to all AI models and is not only specific to the ASR model. However, it is a critical factor that impacts overall latency as well as the compute cost to run any AI application.
The whole point of optimizing a model is to reduce the inference cost both at compute level as well as the latency level. But all models available online for a particular architecture are not created equally and do not have the same code quality. They also have dramatic differences in performance.
Also, not all of them respond in the same way to knowledge distillation, pruning, quantization, and other optimization techniques to result in improved inference performance without impacting the accuracy results.
Flexible deployment and scalability
Creating an accurate and efficient model is only a small fraction of any real-time AI application. The required surrounding infrastructure is vast and complex. For example, deployment infrastructure should include:
- Streaming support
- Resource management service
- Servicing infrastructure
- Analytics tool support
- Monitoring service
Creating a custom end-end optimized deployment pipeline that supports the required latency requirement for any ASR application is challenging because it requires optimization and acceleration at each pipeline stage.
Based on the number of audio streams that must be supported at a given instance, your speech recognition application should be able to auto-scale the application deployment to provide acceptable performance.
Customization
Getting a model to work out-of-the-box is always the goal. However, the performance of currently available models depends on the dataset used during its training phase. Models typically work great for the use case they’ve already been exposed to, but the same model’s performance may degrade as soon as it is deployed in different domain applications.
Specifically, in the case of ASR, the model’s performance depends on accent or language and variations in speech. You should be able to customize models based on the application use case.
For instance, speech recognition models being deployed in healthcare– or financial-related applications require support for domain-specific vocabulary. This vocabulary differs from what is normally used during ASR model training.
To support regional languages for ASR, you need a complete set of training pipelines to easily customize the model and efficiently handle different dialects.
Monitoring and tracking
Real-time monitoring and tracking help in getting instant insights, alerts, and notifications so that you can take timely corrective actions. This helps in tracking the resource consumption as per the incoming traffic so that the corresponding application can be auto-scaled. Quota limits can also be set to minimize the infrastructure cost without impacting the overall throughput.
Capturing all these stats requires integrating multiple libraries to capture performance at various stages of the ASR pipeline.
Examples of how the Riva SDK addresses ASR challenges
Advanced SDKs can be used to conveniently add a voice interface to your applications. In this post, I demonstrate how a GPU-accelerated SDK like Riva can be applied to solve these challenges when building speech recognition applications.
High accuracy and compute optimization
You can use pretrained Riva speech models in NGC that can be fine-tuned with TAO Toolkit on a custom data set, further accelerating domain-specific model development by 10x.
All NGC models are optimized and sped up for GPU deployment to achieve better recognition accuracy. These models are also fully supported by NVIDIA TensorRT optimization. Riva’s high-performance inference is powered by TensorRT optimizations and served using the NVIDIA Triton Inference Server to optimize the overall compute requirement and, in turn, improve the server throughput
For example, here are a few ASR models on NGC that are further optimized as part of the Riva pipeline for better performance:
Continued optimizations across the entire stack of Riva—from models and software to hardware—has delivered 12x the gain compared to the previous generation.
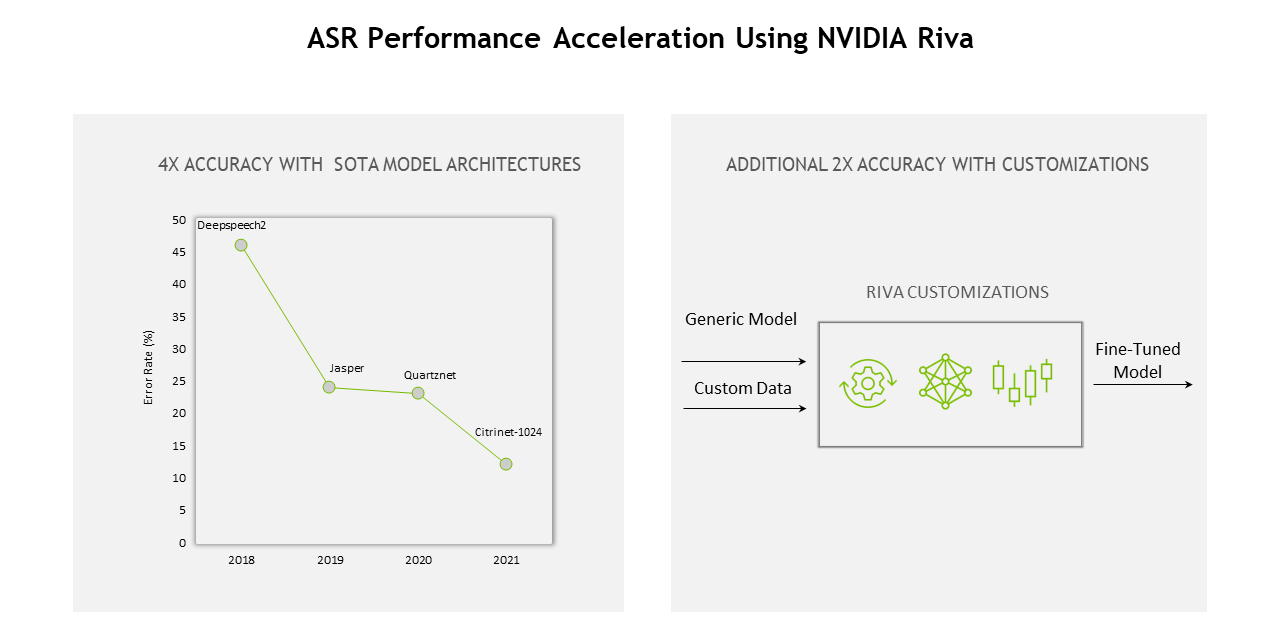
Low latency
Latencies and throughput measurements for streaming and offline configurations are reported under the ASR performance section of Riva documentation.
In “streaming low latency” Riva ASR model deployment mode, the average latency (ms) is far less than 50 ms for most of the cases. Using such ASR models, it becomes easier to create a real-time conversational AI pipeline and still achieve the <300 msec latency requirement.
Flexible deployment and scaling
Deploying your speech recognition application on any platform with ease requires full support. The Riva SDK provides flexibility at each step from fine-tuning models on domain-specific datasets to customizing pipelines. It can also be deployed in the cloud, on-premises, edge, and embedded devices.
To support scaling, Riva is fully containerized and can scale to hundreds and thousands of parallel streams. Riva is also included in the NGC Helm repository, which is a chart designed to automate for push-button deployment to a Kubernetes cluster.
For more information about deployment best practices, see the Autoscaling Riva Deployment with Kubernetes for Conversational AI in Production on-demand GTC session.
Customization
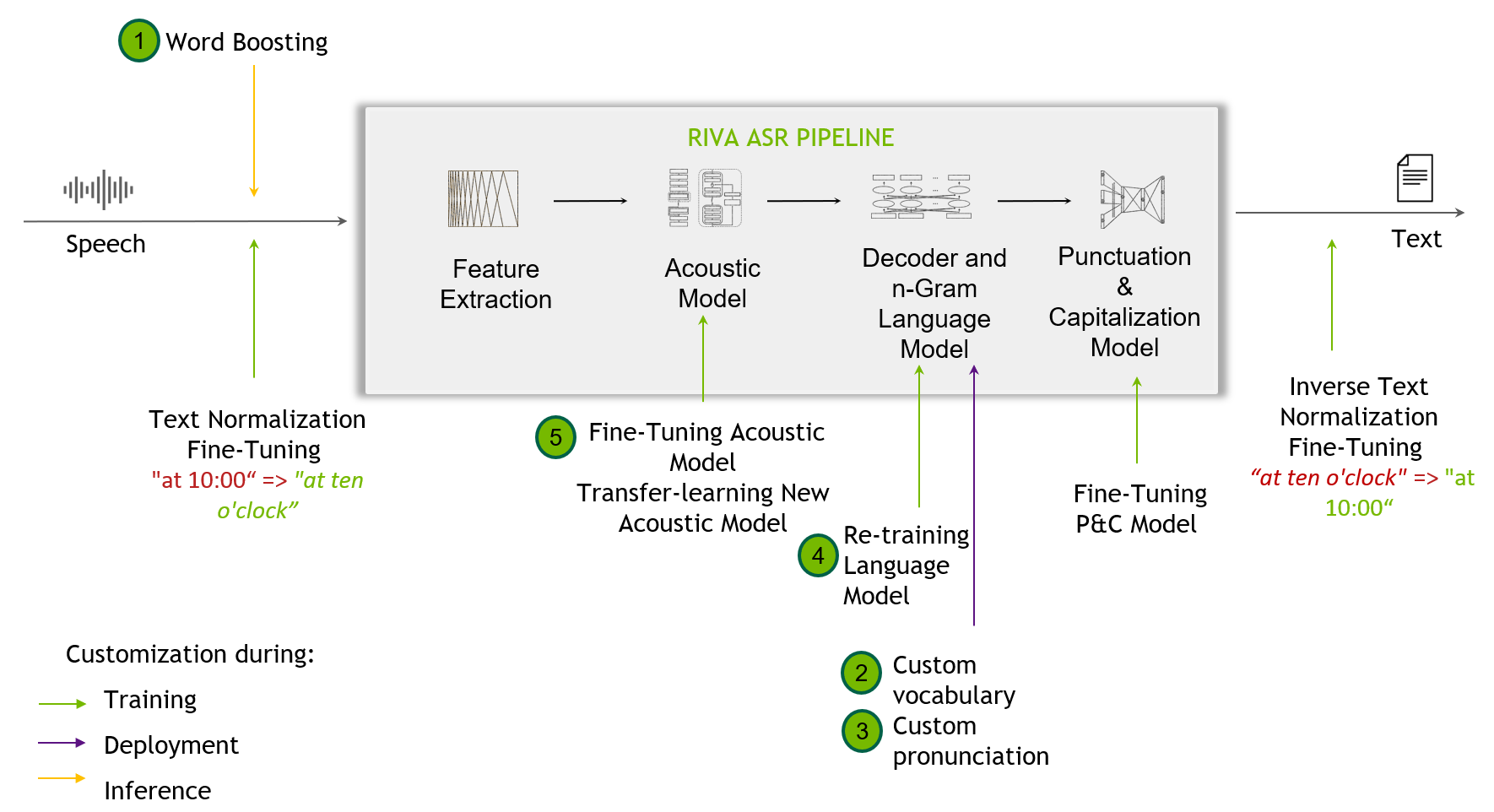
Customization techniques are helpful when out-of-the-box Riva models fall short dealing with challenging scenarios not seen in the training data. This might include recognizing narrow domain terminologies, new accents, or noisy environments.
SDKs like Riva support customization, starting from the word-boosting level, and provision for the end user to custom train their acoustic models.
Riva speech skills also provide high-quality, pretrained models across a variety of languages. For more information about all the models for supported languages, see the Language Support section.
Monitoring and tracking
In Riva, underlying Triton Inference Server metrics are available to the end users to use, based on the customization and dashboard creation. These metrics are only available by accessing the endpoint.
NVIDIA Triton provides Prometheus metrics, as well as indicating GPU and request statistics. This helps in monitoring and tracking the production deployment setup.
Key takeaways
This post provides you with a high-level overview of common pain points that arise when developing AI applications with ASR capabilities. Being aware of the factors impacting your ASR application’s overall performance helps you streamline and improve the end-to-end development process.
We also shared a few functionalities of Riva that can help mitigate these problems to an extent and even provide customizability tips for ASR applications to support your domain-specific use case.
For more information, see the following resources:
- Learn how your organization can scale ASR system performance with the free ebook, End-to-End Speech AI Pipelines.
- Ready for a hands-on lab? Use pretrained models and quickly try out ASR customization techniques, such as word boosting, with the free lab, Customizing ASR with NVIDIA Riva.