
Speech AI is the ability of intelligent systems to communicate with users using a voice-based interface, which has become ubiquitous in everyday life. People regularly interact with smart home devices, in-car assistants, and phones through speech. Speech interface quality has improved leaps and bounds in recent years, making them a much more pleasant, practical, and natural experience than just a decade ago.
Components of intelligent systems with a speech AI interface include the following:
- Automatic speech recognition (ASR): Converts audio signals into text.
- A fulfillment engine: Analyzes the text, identifies the user’s intent, and fulfills it.
- Text-to-speech (TTS): Converts the textual elements of the response into high-quality and natural speech
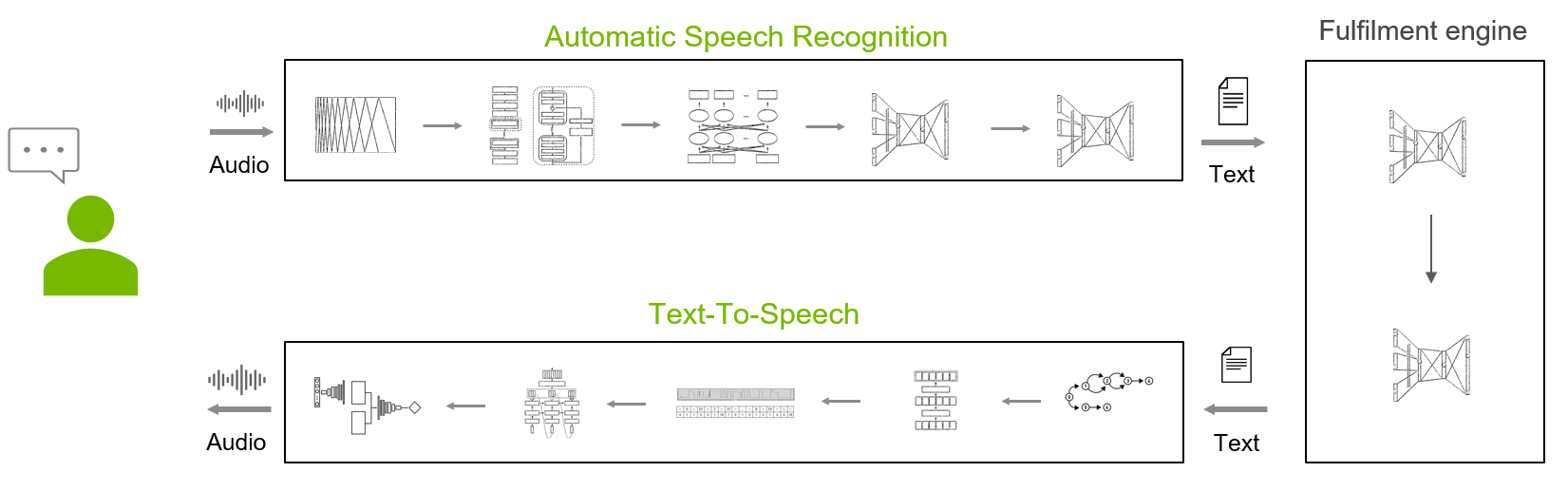
ASR is the first component of any speech AI system and plays a critical role. Any error made early in the ASR phase is then compounded by issues in the subsequent intent analysis and fulfillment phase.
There are over 6500 spoken languages in use today, and most of them don’t have commercial ASR products. ASR service providers cover a few dozen at most. NVIDIA Riva currently covers five languages (English, Spanish, German, Mandarin, and Russian), with more scheduled for upcoming releases.
While this set is still small, Riva provides ready-to-use workflow, tools, and guidance for you to bring up an ASR service for a new language quickly, systematically, and easily. In this post, we present the workflow, tools, and best practices that the NVIDIA engineering team employed to make new world-class Riva ASR services. Start the journey!
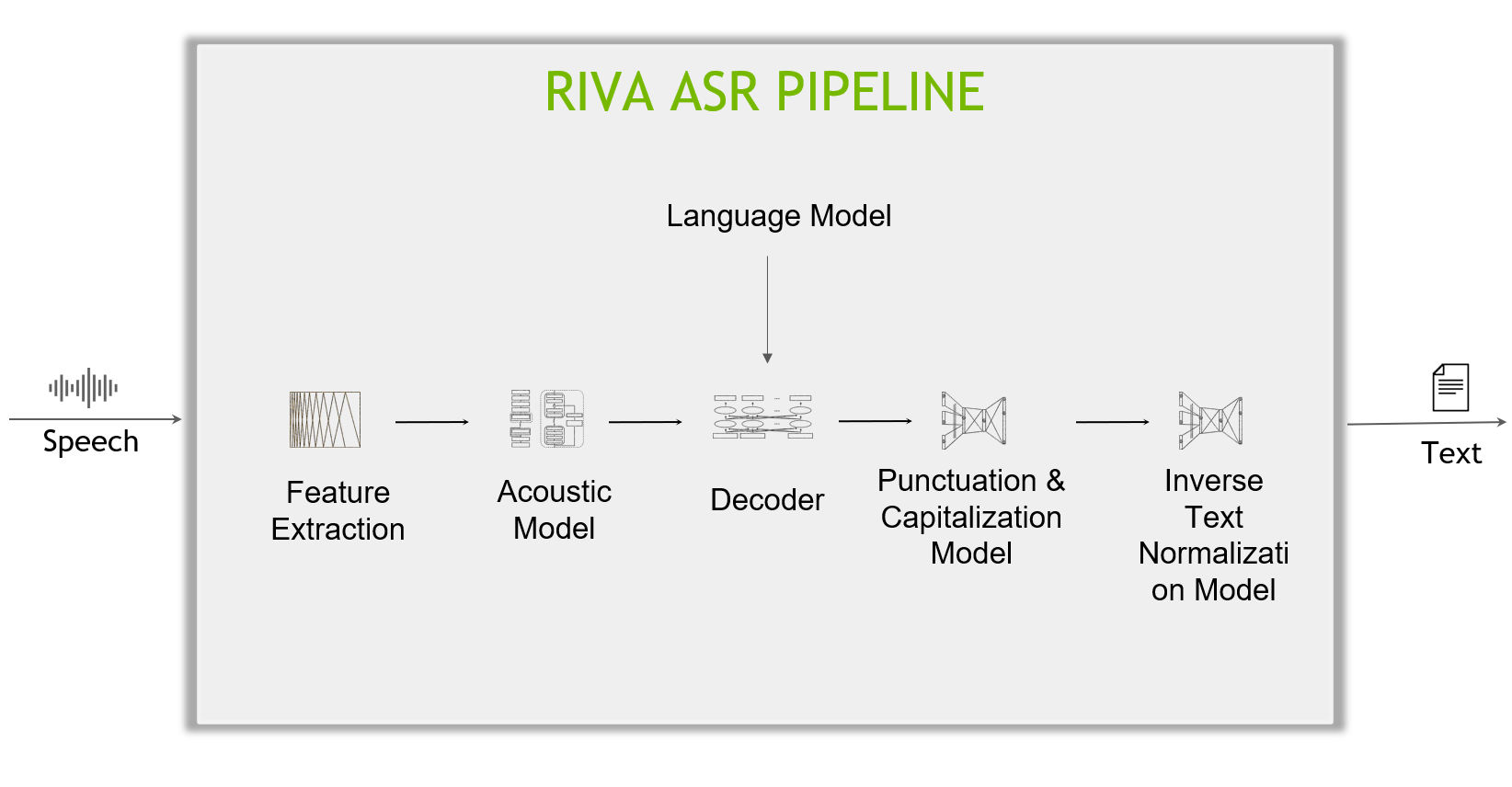
The anatomy of a Riva ASR pipeline
Take a deeper look into the inner working of a Riva ASR pipeline, which includes the following main components:
- Feature extractor: Raw temporal audio signals first pass through a feature extraction block, which segments the data into fixed-length blocks (for example, of 80 ms each), then converts the blocks from the temporal domain to the frequency domain (spectrogram).
- Acoustic model: Spectrogram data is then fed into an acoustic model, which outputs probabilities over characters (or more generally, text tokens) at each time step.
- Decoder and language model: A decoder converts this matrix of probabilities into a sequence of characters (or text tokens), which form words and sentences. A language model can give a sentence score indicating the likelihood of a sentence appearing in its training corpus. An advanced decoder can inspect multiple hypotheses (sentences) while combining the acoustic model score and the language model score and searching for the hypothesis with the highest combined score.
- Punctuation and capitalization (P&C): The text produced by the decoder comes without punctuation and capitalization, which is the job of the Punctuation and Capitalization model.
- Inverse text normalization (ITN): Finally, ITN rules are applied to transform the text in verbal format into a desired written format, for example, “ten o’clock” to “10:00”, or “ten dollars” to “$10”.
Riva ASR workflow for a new language
Like solving other AI and machine learning problems, creating a new ASR service from scratch is a capital-intensive task involving data, computation, and expertise. Riva significantly reduces these barriers.
With Riva, making a new ASR service for a new language requires, at the minimum, collecting data and training a new acoustic model. The feature extractor and the decoder are readily provided.
The language model is optional but is often found to improve the accuracy of the pipeline up to a few percent and is often well worth the effort. P&C and ITN further improve the text readability for easier human consumption or further processing tasks.
The Riva new language workflow is divided into the following major phases:
- Data collection
- Data preparation
- Training and validation
- Riva deployment
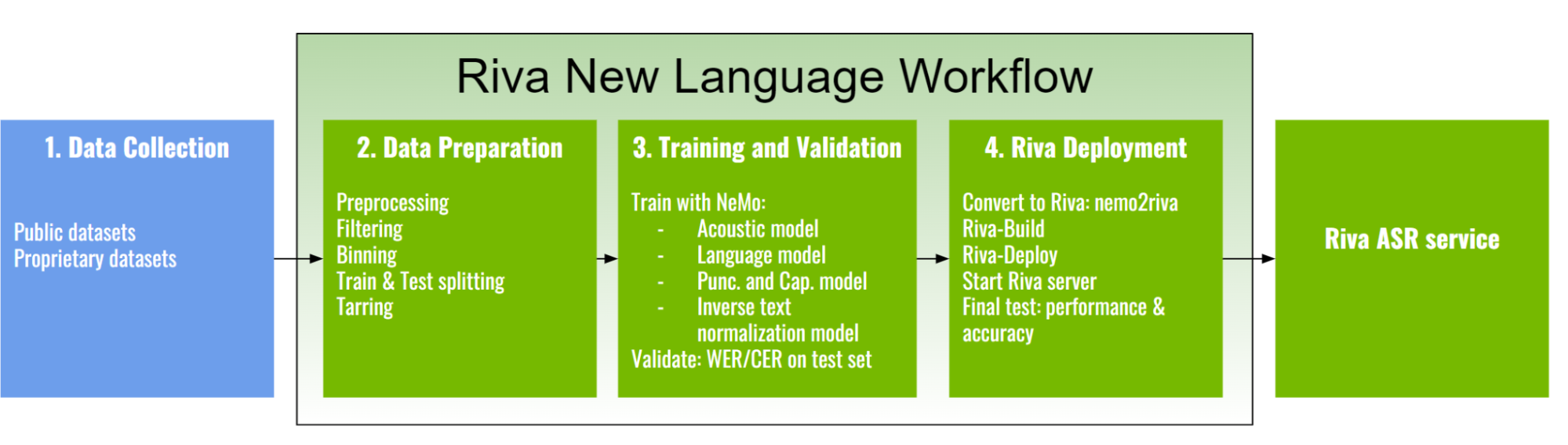
In the next sections, we discuss the details of each stage.
Phase 1: Data collection
When adapting Riva to a whole new language, a large amount of high-quality transcribed audio data is critical for training high-quality acoustic models. Where applicable, there are several significant sources of public datasets that you can readily leverage:
- Mozilla Common Voice (MCV)
- Multilingual LibriSpeech (MLS)
- Voxpopuli
To train Riva world-class models, we also acquired proprietary datasets. The amount of data for Riva production models ranges from ~1,700–16,700 hours.
Phase 2: Data preparation
The data preparation phase carries out the steps required to convert the diverse raw audio datasets into a uniform format efficiently digestable by the NVIDIA NeMo toolkit, which is used for training.
- Data preprocessing
- Data cleaning/filtering
- Binning
- Train and test splitting
- Tarring
Data preprocessing
Data preprocessing is required to convert the audio or text data input into a readable format for your machine-learning algorithms.
Audio data
Audio data acquired from various sources is inherently heterogeneous (file format, sample rate, bit depth, number of audio channels, and so on). As a preprocessing step, you build a separate data ingestion pipeline for each source and convert the audio data to a common format:
- WAV file format
- Bit depth of 16 bits
- Sample rate of 16 kHz
- Single audio channel
Dataset ingestion scripts are used to convert the various datasets into the standard manifest format.
Text data
Text cleaning removes characters that are not part of the language alphabet. For example, we observed and removed some Chinese characters in the public dataset for German collected from MCV, MLS, and Voxpopuli.
Text normalization converts text from a written form into its verbalized form. It is used as a preprocessing step for preprocessing ASR training transcripts.
Next, you build a text tokenizer. There are two popular encoding choices for acoustic models that are almost identical: character encoding and subword encoding. The primary difference is that a subword encoding model accepts a subword-tokenized text corpus and emits subword tokens in its decoding step. Research and practice have shown that subword encoding helps improve the accuracy of acoustic models.
Data cleaning and filtering
This step is carried out to filter out some outlying samples in the datasets. As the simplest procedure, samples that are too long, too short, or empty are filtered out.
In addition, you can also filter out samples that are considered ‘noisy.’ This would include samples having a high word error rate (WER) or character error rate (CER) with regard to a previously trained ASR model.
A manual inspection of these noisy samples can also reveal problematic issues with some samples, such as the transcription not matching the audio.
Binning
For training ASR models, audio with different lengths may be grouped into a batch, with padding to make them all the same length. The extra padding is a significant source of computation waste.
Splitting the training samples into buckets with different lengths and sampling from the same bucket for each batch increases the computation efficiency. It may result in a training speedup of more than 2x.
Train and test splitting
This step is a staple of any deep learning and machine learning development pipeline, to ensure that the model is learning to generalize without overfitting the training data. For the test set, use additionally curated data that isn’t from the same source as the training datasets, such as YouTube and TED talks.
Tarring
Suppose the experiments run on a cluster with datasets stored on a distributed file system. In that case, you will likely want to avoid constantly reading multiple small files and will tar the audio files instead.
Phase 3: Training and validation
An ASR pipeline includes the following models:
- Acoustic model: Maps raw audio input to probabilities over text tokens at each time step. This matrix of probabilities is fed into a decoder that converts probabilities into a sequence of text tokens.
- (Optional) Language model: Used in the decoding phase of the acoustic model output.
- (Optional) P&C model: Formats the raw transcript, augmenting with punctuation and capitalization.
- (Optional) ITN model: Produces a desired written format from a spoken format.
Acoustic model
The acoustic models are the most important part of an ASR service. They are the most resource-intensive models, requiring a large amount of data to train on powerful GPU servers or clusters. They also have the largest impact on the overall ASR quality.
Some acoustic models supported by Riva are QuartzNet, CitriNet, Jasper, and Conformer.
Cross-language transfer learning is especially helpful when training new models for low-resource languages. But even when a substantial amount of data is available, cross-language transfer learning can help boost performance further. It is based on the idea that phoneme representation can be shared across different languages.
When carrying out transfer learning, you must use a lower learning rate compared to training from scratch. When training models such as Conformer and CitriNet, we have also found that using large batch sizes in the [256, 2048] range helps stabilize the training loss.
All Riva ASR models in production other than English were trained with cross-language transfer learning from an English base model that was trained with the most audio hours.

Language model
A language model can give a score indicating the likelihood of a sentence appearing in its training corpus. For example, a model trained on an English corpus judges “Recognize speech” as more likely than “Wreck a nice peach.” It also judges “Ich bin ein Schüler” as quite unlikely, as that is a French sentence.
The transcripts predicted by the acoustic model can be further improved using a language model in conjunction with a beam search decoding. In our experiments, we generally observe an additional 1-2% of WER reduction by using a simple n-gram model.
When coupled with an LM, a decoder would be able to correct what it “hears” (e.g. “Let’s light an insense stick”) to what makes more common sense (i.e. “Let’s light an incense stick”), for the LM will give a higher score for the latter sentence than the former.
Training data: We create a training set by combining all the transcript text in our ASR set, normalizing, cleaning, and then tokenizing using the same tokenizer used for ASR transcript preprocessing mentioned above. The language models supported by Riva are n-gram models, which can be trained with the Kenlm toolkit.
Punctuation and capitalization model
The Punctuation and Capitalization model consists of the pre-trained Bidirectional Encoder Representations from Transformers (BERT) followed by two token classification heads. One classification head is responsible for the punctuation task, and the other one handles the capitalization task.
Inverse text normalization model
We leverage the NeMo text inverse normalization module for the task. NeMo ITN is based on weighted finite-state transducer (WFST) grammars. The tool uses Pynini to construct WFSTs, and the created grammars can be exported and integrated into Sparrowhawk (an open-source version of the Kestrel TTS text normalization system) for production.
Phase 4: Riva deployment
Once all the models have been trained, it’s time to deploy them to Riva for serving.
Bring your own models
Given the final .nemo models that you have trained so far, here are the steps and tools that are required to deploy on Riva:
- The Riva Quickstart scripts provide the
nemo2rivaconversion tool, and scripts (riva_init.sh,riva_start.sh, andriva_start_client.sh) to download theservicemaker,riva-speech-server, andriva-speech-clientDocker images. - Build
.rivaassets usingnemo2rivacommand in theservicemakercontainer. - Build RMIR assets using the
riva-buildtool in theservicemakercontainer. - Deploy the model in
.rmirformat withriva-deploy. - Start the server with
riva-start.sh.
After the server successfully starts up, you can query the service to measure accuracy, latency, and throughput.
Riva pretrained models on NGC
Alternatively, you can make use of Riva pretrained models published on NGC. These models can be deployed as-is or served as a starting point for fine-tuning and further development.
Case study: German
For German, there are several significant sources of public datasets that you can readily access:
- Mozilla Common Voice (MCV) corpus 7.0, DE subset: 571 hours
- Multilingual LibriSpeech (MLS), DE subset: 1,918 hours
- Voxpopuli, DE subset: 214 hours
In addition, we acquired proprietary data for a total of 3,500 hours of training data!
We started the training of the final model from a NeMo DE Conformer-CTC large model (trained on MCV7.0 for 567 hours, MLS for 1,524 hours, and VoxPopuli for 214 hours), which itself was trained using an English Conformer model as initialization (Figure 5).

All Riva German assets are published on NGC (including .nemo, .riva, .tlt, and .rmir assets). You can use these models as starting points for your development.
Acoustic models
- Citrinet ASR German:
- Conformer ASR German
ITN model
NGC provides an OpenFST finite state archive (.far) for use within the open-source Sparrowhawk normalization engine and Riva.
Language model
4-gram language models trained with Kneser-Ney smoothing using KenLM are available from NGC. This directory also contains the decoder dictionary used by the Flashlight decoder.
P&C model
NGC provides a Riva P&C model for German.
Case study: Hindi
For Hindi, you can readily access the Hindi-Labelled ULCA-asr-dataset-corpus public dataset:
- Newsonair (791 hours)
- Swayamprabha (80 hours)
- Multiple sources (1,627 hours)
We started the training of the Hindi Conformer-CTC medium model from a NeMo En Conformer-CTC medium model as initialization. The Hindi model’s encoder is initialized with the English model’s encoder weights and the decoder is initialized from scratch (Figure 6).

Getting started and bring your own languages
The NVIDIA Riva speech AI ecosystem (including NVIDIA TAO and NVIDIA NeMo) offers comprehensive workflows and tools for new languages, making it a systematic approach to bringing your own language onboard.
Whether you are fine-tuning an existing language model for a domain-specific application or implementing one for a brand-new dialect with little or lots of data, Riva offers those capabilities.
For more information about how NVIDIA Riva ASR engineering teams bring up a new language, see the Riva new language tutorial series and apply it to your own project.
