
嵌入式数据类型是一种表示列式数据中分层关系的便捷方式。它们经常用于 提取、转换、加载(ETL)在商业智能领域的工作负载、推荐系统、网络安全、地理空间和其他应用中。
例如,列表类型可用于轻松地将多个事务附加到用户,而无需创建新的查找表。结构类型可用于在同一列中附加灵活的元数据和许多键值对。在 Web 和移动应用程序中,嵌套类型将原始 JSON 对象表示为数据列中的元素,从而使这些数据能头输入到 机器学习(ML)训练管线。许多数据科学应用都依赖于嵌套类型来对复杂的数据输入进行建模、管理和处理。
在 RAPIDS 中,libcudf 是一套用于列式数据处理的 CUDA C++ 库,旨在加速数据科学库的性能。RAPIDS libcudf 基于 Apache Arrow 内存格式,支持 GPU 加速的数据读取器、写入器、关系代数函数和列转换操作。
除了数字和字符串等基本数据类型外,libcudf 还支持嵌套数据类型,例如可变长度列表、结构体以及列表和结构体类型的任意嵌套组合。在 23.02 到 23.12 的版本中,RAPIDS libcudf 扩展了对算法中嵌套数据类型的支持,包括聚合、连接和排序。
本文展示了使用嵌套数据类型进行数据处理的过程,介绍了实现嵌入式数据处理的“行运算符”,并探讨了嵌入式数据类型对性能的影响。
使用嵌套类型进行数据处理
数据库管理中的一个常见工作流程是监控和管理重复数据。RAPIDS libcudf 现在包含一个C++ nested_types 示例,它将 JSON 数据读取为 libcudf 表,计算第一列中每个不同元素的计数,将计数加入原始表,并将数据写回 JSON。libcudf 的公共 API 使得数据处理应用程序能够轻松处理数字或字符串等平面类型,以及结构体和列表等嵌套类型。
我们的 C++ nested_types 示例使用 libcudf JSON 读取器将列式格式的嵌套数据提取为表对象。加速的 JSON 读取器也可供 C++ 开发者使用。JSON 提供了一种人类可读的方式来创建和检查嵌套列。要了解在 Python 层中使用 JSON 读取器的模式,请参阅 使用 RAPIDS 进行 GPU 加速的 JSON 数据处理。
我们read_json函数,C++ nested_types示例接受filepath并返回table_with_metadata对象:
cudf::io::table_with_metadata read_json(std::string filepath)
{
auto source_info = cudf::io::source_info(filepath);
auto builder = cudf::io::json_reader_options::builder(source_info).lines(true);
auto options = builder.build();
return cudf::io::read_json(options);
}
将 JSON 数据读取并解析为表对象后,第一个处理步骤是计数聚合,以跟踪每个不同元素的出现次数。count_aggregate示例中的函数会填充聚合请求,执行聚合函数,然后构建输出表:
std::unique_ptr<cudf::table> count_aggregate(cudf::table_view tbl)
{
// Get count for each key
auto keys = cudf::table_view{{tbl.column(0)}};
auto val = cudf::make_numeric_column(cudf::data_type{cudf::type_id::INT32}, keys.num_rows());
cudf::groupby::groupby grpby_obj(keys);
std::vector<cudf::groupby::aggregation_request> requests;
requests.emplace_back(cudf::groupby::aggregation_request());
auto agg = cudf::make_count_aggregation<cudf::groupby_aggregation>();
requests[0].aggregations.push_back(std::move(agg));
requests[0].values = *val;
auto agg_results = grpby_obj.aggregate(requests);
auto result_key = std::move(agg_results.first);
auto result_val = std::move(agg_results.second[0].results[0]);
auto left_cols = result_key->release();
left_cols.push_back(std::move(result_val));
// Join on keys to get
return std::make_unique<cudf::table>(std::move(left_cols));
}
掌握计数数据后,下一个处理步骤会将这些数据与原始表连接起来,并添加这些信息,以便为下游分析中基于计数的过滤和根本原因调查提供信息。join_count函数,C++ nested_types示例接受两个table_view将对象与它们的第一列连接起来,然后构建输出表:
std::unique_ptr<cudf::table> join_count(cudf::table_view left, cudf::table_view right)
{
auto [left_indices, right_indices] =
cudf::inner_join(cudf::table_view{{left.column(0)}}, cudf::table_view{{right.column(0)}});
auto new_left = cudf::gather(left, cudf::device_span<int const>{*left_indices});
auto new_right = cudf::gather(right, cudf::device_span<int const>{*right_indices});
auto left_cols = new_left->release();
auto right_cols = new_right->release();
left_cols.push_back(std::move(right_cols[1]));
return std::make_unique<cudf::table>(std::move(left_cols));
}
最后一个数据处理步骤根据第一列中的元素对表格进行排序。排序有助于提供确定性排序,从而促进分区和合并等下游步骤。sort_keysC++nested_types 示例中的函数接受table_view计算索引,sorted_order然后根据以下顺序收集表格:
std::unique_ptr<cudf::table> sort_keys(cudf::table_view tbl)
{
auto sort_order = cudf::sorted_order(cudf::table_view{{tbl.column(0)}});
return cudf::gather(tbl, *sort_order);
}
最后,使用 GPU 加速的 JSON 写入器将已处理的数据序列化回磁盘,该写入器使用来自read_json以保留输入数据中的嵌套结构键名。write_json函数,C++ nested_types示例接受table_view, table_metadata以及filepath:
void write_json(cudf::table_view tbl, cudf::io::table_metadata metadata, std::string filepath)
{
auto sink_info = cudf::io::sink_info(filepath);
auto builder = cudf::io::json_writer_options::builder(sink_info, tbl).lines(true);
builder.metadata(metadata);
auto options = builder.build();
cudf::io::write_json(options);
}
总而言之,C++ nested_types示例对第一列中的每个不同元素进行计数,将这些值连接到原始表,然后对第一列上的表进行排序。请注意,此示例中的代码没有任何部分特定于嵌套类型。事实上,此示例与 libcudf 中任何支持的数据类型(平面或嵌入式)兼容,展示了 libcudf 嵌入式类型支持的强大功能和灵活性。
libcudf 行运算符简介
在幕后,libcudf 使用几个关键的“行运算符”支持等式比较、不等式比较和元素哈希。这些行运算符在算法吞吐量 libcudf 中重复使用,并能够将数据类型支持与其他算法细节分离。
以基于哈希的聚合为例,在构建和探索哈希表时使用哈希运算符和等式运算符。对于基于排序的聚合,Lexicographic Operator 识别一个元素小于另一个元素,并且是任何排序算法的关键组件。新的行运算符在 libcudf 中的关系代数函数中解锁对嵌套类型的支持。
对于平面类型(例如数字和字符串),行运算符会处理每个元素的值和空状态。字符串类型通过将可变数量的字符与每个元素关联起来的整数偏移增加了复杂性。对于结构类型,行运算符会处理结构父级的空状态以及每个子列的值和空状态。
可变长度列表类型增加了另一层复杂性,其中行运算符负责层次结构,包括每个嵌套级别的空状态、列表深度和列表长度。如果层次结构匹配,则列表运算符会考虑每个叶元素的值和空状态。在行运算符中,哈希和等式更简单,因为它们可以以任何顺序处理每个元素的数据。但是,对于包含列表的类型,字典比较必须产生一致的排序,因此需要对空状态、层次结构和值进行顺序解析。
libcudf lexicographic 运算符中列表类型的处理灵感来源于 Parquet 格式中使用的 Dremel 编码算法。在 Dremel 编码中,列表列通过三个数据流来表示:一个 定义 流用于记录空状态和嵌套深度,一个 重复 流用于记录列表长度,以及一个 值 流用于记录叶值。这种编码提供了一个平面数据结构,相较于 Arrow 中的递归变量长度列表表示,它能更高效地进行处理。
Dremel 对列表进行编码的一个限制是,值流仅支持平面类型。为了扩展对包含结构的列表的支持,预处理步骤将嵌入式结构列替换为与每个结构元素的秩对应的整数列。此递归预处理步骤扩展了词库运算符类型支持,以在数据类型中包含列表和结构的任意组合。
数据类型如何影响性能
我们的 C++ nested_types 示例与 libcudf 中所有受支持的数据类型兼容。通过示例中的命令行界面,您可以轻松地比较性能。以下性能数据基于示例中实现的计时收集,并使用 NVIDIA DGX H100 硬件。
列的数据类型会影响示例的整体运行时间,因为更复杂的数据类型会增加基于排序的处理步骤的运行时间(图 1)。在一系列数据类型中,结果显示计数聚合步骤的运行时间为 2-5 毫秒,内部连接步骤的运行时间为 10-25 毫秒。这两个步骤都使用基于哈希的实现,并依赖于哈希和等式行运算符。
但是,排序步骤表明,对于包含字符串或列表的可变大小的类型,运行时间已增加到 60-90 毫秒。排序步骤依赖于更复杂的词汇表行运算符。虽然基于哈希的算法作为数据类型的函数显示相对一致的运行时间,但基于排序的算法显示可变大小的类型的运行时间更长。
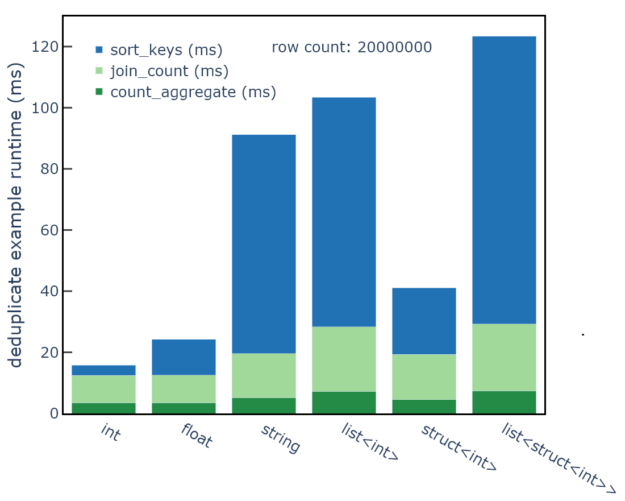
count_aggregate, join_count以及sort_keys其中包含 85%的不同元素和 2000 万行数据,行数和套料深度也会影响示例的性能,因为行数越多,数据类型越简单,数据处理吞吐量越高。图 2 显示count_aggregate性能C++ nested_types例如,吞吐量通常会随着行数从 10 万行增加到 2000 万行而增加。标记为`8`的数据类型有 8 个级别的嵌套深度。int和float是指 64 位类型。
请注意,输入数据使用带有一个子级的结构,并使用长度为 1 的列表。性能数据显示峰值吞吐量约为 45 GB/s 的基元类型、峰值吞吐量约为 30 GB/s 的单嵌套类型,以及峰值吞吐量约为 10-25 GB/s 的深度嵌套类型。结构级别产生的开销比列表级别低,而混合结构/列表嵌套会产生最大的开销。
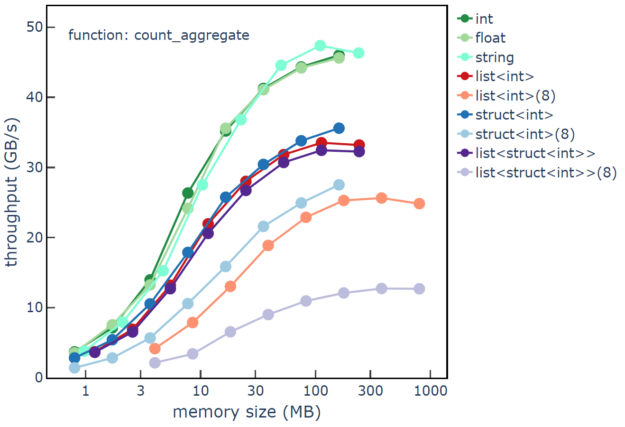
count_aggregate示例函数。每行显示从 10 万行扫描到 2000 万行的效果最后,列表元素的长度也会影响性能,由于比较器中提前退出,列表元素的长度越长,吞吐量越高。图 3 显示了列表长度对数据处理吞吐量的影响list<int>列表长度从 1 到 16 的列。随着列表长度的增加,整数叶总数和总显存大小也会增加,并且偏移数据的行数和总大小保持不变。
图 3 中的数据使用随机排序的叶值,因此比较器通常只需要检查每个列表的第一个元素。从 1 到 16 的长度中收集的性能数据显示,count_aggregate并且吞吐量提高了 4 倍,sort_keysstep.数据使用 1000 万行、64 位整数叶元素、85%不同的叶值,以及每个表中保持不变的列表长度。
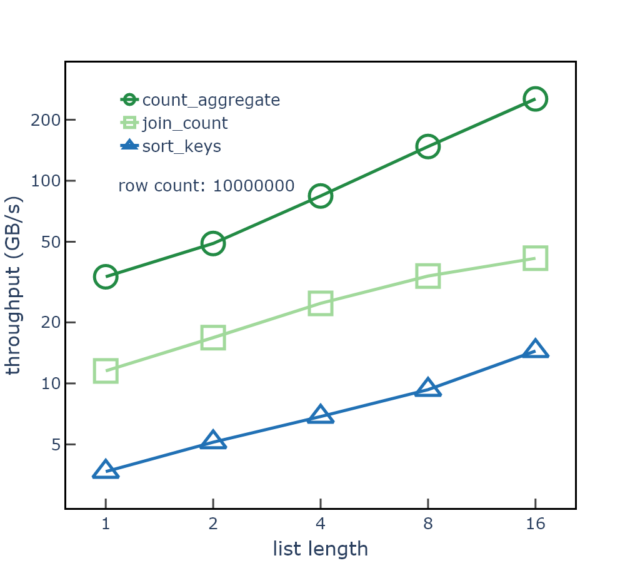
count_aggregate, join_count以及sort_keys具有不同列表长度的单嵌套列表类型的步骤总结
RAPIDS libcudf 为处理嵌套数据类型提供了功能强大、灵活且加速的工具。聚合、连接和排序等关系代数算法针对任何受支持的嵌套数据类型进行了调整和优化,甚至包括深度嵌套和混合列表以及结构嵌套数据类型。
开始使用 RAPIDS libcudf,您可以构建并运行一些示例。要了解更多关于 CUDA 加速数据帧的信息,请参考cuDF 文档和rapidsai/cudf GitHub 仓库。为了便于测试和部署,您也可以使用RAPIDS Docker 容器,它提供了正式发布和夜间构建版本。如果您已经在使用 cuDF,可以尝试运行新的 C++ nested_types 示例,访问rapidsai/cudf/tree/HEAD/cpp/examples/nested_types 在 GitHub 上查看。
致谢
感谢 Devavret Makkar、Jake Hemstad 以及 RAPIDS 团队的其他成员为这项工作做出的贡献。



