最新发布的 NVIDIA CUDA Toolkit 12.2 引入了一系列重要的新功能,对编程模型进行了修改,并增强了对硬件功能的支持,加速了 CUDA 应用程序的发展。
现在,通过 通用可用性 来获取 NVIDIA 的 CUDA Toolkit 12.2,其中包括许多新功能,包括主要功能和次要功能。
以下文章概述了许多关键功能,包括:
- NVIDIA Hopper( H100 ) GPU 支持。
- Hopper GPU 早期访问 NVIDIA 机密计算( CC )。
- 异构内存管理( HMM )支持。
- 延迟加载默认设置。
- CUDA 多进程服务( MPS )的应用程序优先级。
- NVIDIA Nsight Compute 和 NVIDIA Nsight Systems 开发工具更新。
作为 加速计算,NVIDIA 为解决世界上最严峻的计算挑战创造了解决方案。加速计算需要全栈优化,从芯片架构、系统和加速库,到安全和网络连接,这一切都始于 CUDA 工具包。
观看以下 CUDA Toolkit12.2 YouTube 首映式网络研讨会。
Hopper GPU 支架
新的 H100 现在,所有 GPU 的编程模型增强都支持 GPU 架构的功能,包括新的 PTX 指令以及通过更高级别的 C 和 C++ API 进行的公开。其中一个例子是 Hopper Confidential Computing(请参阅下文了解更多信息),它提供了 Hopper GPU 架构独有的早期访问部署。
Hopper 的机密计算
Confidential Computing 早期访问软件版本拥有完整的软件堆栈,针对单个 H100 GPU 的直通模式,提供用于加密和身份验证的单个会话密钥,以及基本的 NVIDIA 开发工具使用。用户代码和数据按照 AES-GCM 标准进行加密和验证。
不需要任何特定的 H100 SKU 、驱动程序或工具包下载。 H100 GPU 的机密计算需要支持基于虚拟机( VM )的 TEE 技术的 CPU ,如 AMD SEV-SNP 和 Intel TDX 。
阅读 Protecting Sensitive Data and AI Models with Confidential Computing 文章,重点介绍了 OEM 合作伙伴运送 CC 兼容的服务器。
下图比较了在 CC 打开和关闭时使用 VM 时的数据流。
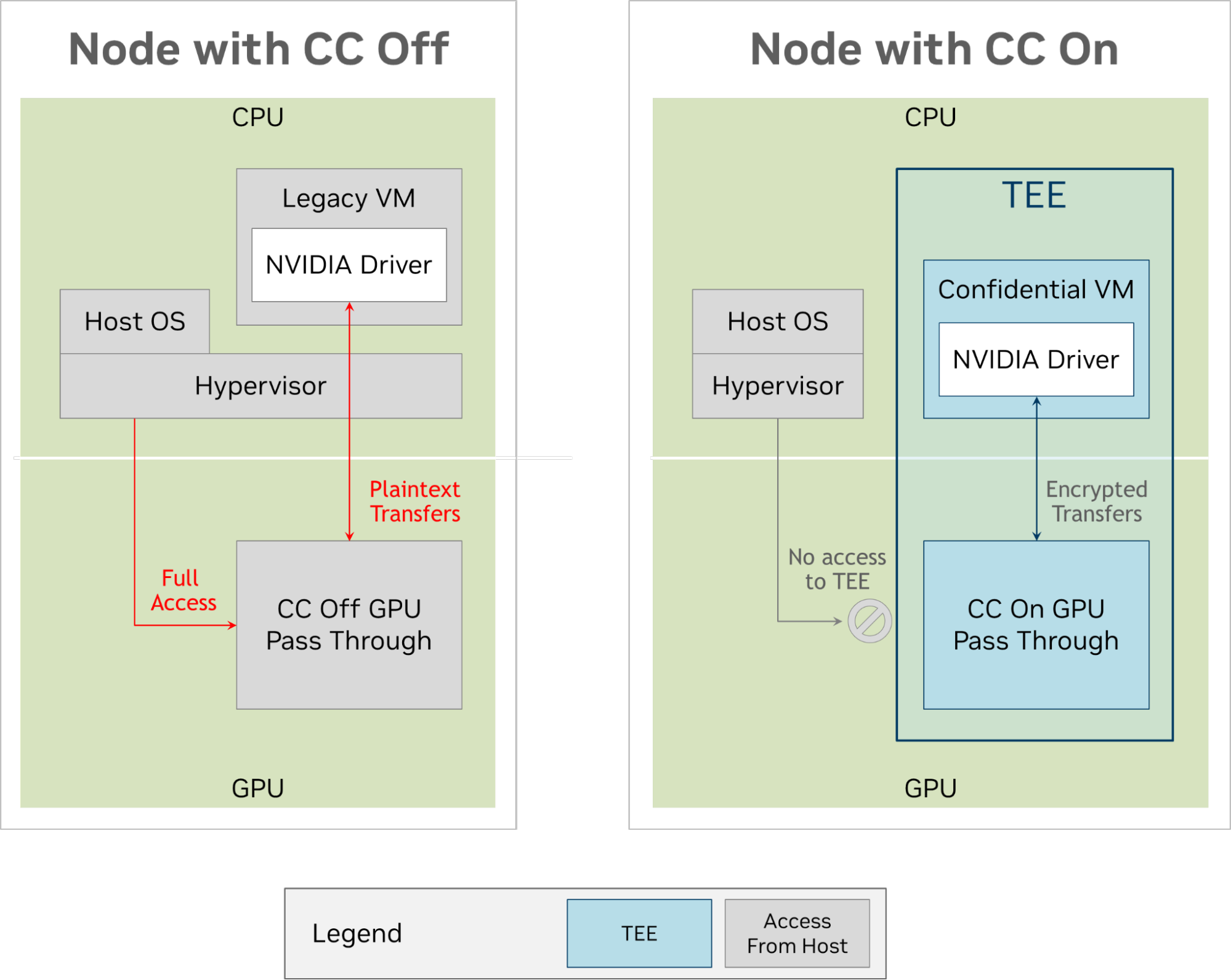
在图 1 中,左侧设置了一个传统的虚拟机。在此模式下,系统管理程序分配一个 H100 GPU (未启用 CC 模式)。虽然系统管理程序被隔离并受到恶意虚拟机的保护,但情况并非如此:系统管理程序可以访问整个虚拟机空间,也可以直接访问 GPU 。
图 1 的右侧显示了相同的环境,但在一台具有机密计算能力的机器上。 CPU 体系结构将现在保密的虚拟机( CVM )与系统管理程序隔离,使其无法再访问其内存页。 H100 也被配置为禁用所有外部访问,除了它和 CVM 之间的路径。 CVM 和 H100 对 PCIe 总线上的传输进行了加密和签名,防止了带有总线分析器的攻击者利用或静默地破坏数据。
在使用早期访问版本的同时,采用良好做法,仅测试合成数据和非专有人工智能模型。安全审查、性能增强和审计尚未最终确定。
Hopper 机密计算目前不包括加密密钥轮换。要了解更多信息,请参阅帖子 什么是机密计算?
异构内存管理
该版本还引入了异构内存管理( HMM )。该技术扩展了对统一虚拟内存的支持,从而在主机内存和加速器设备之间无缝共享数据,而无需由 CUDA 分配或管理内存。这使得将应用程序移植到 CUDA 或使用外部框架和 API 变得更加容易。
目前, HMM 仅在 Linux 上受支持,并且需要最新的内核( 6 . 1 . 24 +或 6 . 2 . 11 +)以及使用 NVIDIA GPU 开放内核模块驱动程序。
第一个版本存在一些限制,以下内容尚不支持:
- GPU 对文件备份内存的原子操作。
- Arm CPU 。
- HMM 上的 HugeTLBfs 页面。
- 这个
fork()试图在父进程和子进程之间共享 GPU 可访问内存时的系统调用。
HMM 还没有完全优化,可能比使用cudaMalloc(),cudaMallocManaged(),或其他现有的 CUDA 内存管理 API 。
懒加载
NVIDIA 最初在 CUDA 11.7 中引入了一项功能,作为一种选择加入,延迟加载现在在带有 R535 驱动程序及更高版本的 Linux 上默认启用。通过根据需要仅加载 CUDA 内核和库函数,延迟加载可以显著减少主机和设备内存占用。复杂的库通常包含数千个不同的内核和变体。这带来了可观的节省。
延迟加载由用户控制,并且只更改默认值。您可以通过在启动应用程序之前设置环境变量来禁用 Linux 上的功能:
CUDA_MODULE_LOADING=EAGER 虽然在 Windows 中禁用当前不可用,但您可以在 Windows 中启用它,方法是在启动前设置环境变量:
CUDA_MODULE_LOADING=LAZYCUDA MPS 的应用程序优先级
当使用 CUDA MPS 运行应用程序时,每个应用程序通常被编码为系统中存在的唯一应用程序。因此,其单独的流优先级可以假定没有系统级争用。然而,在实践中,用户通常希望在全局范围内提高或降低某些流程的优先级。
为了帮助解决这一需求,现在可以为 CUDA MPS 提供运行时的每个客户端的粗粒度优先级映射。这使得在 MPS 下运行的多个进程能够在不更改应用程序代码的情况下,在多个进程之间以粗粒度级别仲裁优先级。
一个名为CUDA_MPS_CLIENT_PRIORITY接受两个值:NORMAL priority, 0,和 BELOW_NORMAL priority, 1.
例如,给定两个客户端,潜在配置如下:
| 客户端 1 环境 | 客户端 2 环境 |
|---|---|
export CUDA_MPS_CLIENT_PRIORITY=0 // NORMAL |
export CUDA_MPS_CLIENT_PRIORITY=1 // BELOW NORMAL |
值得注意的是,这并没有在 GPU 调度器中引入优先级抢先调度或硬实时处理。它确实向调度器提供了关于哪些内核应该在何时排队的附加信息。
Nsight 开发工具
Nsight Developer Tools包含在 CUDA 工具包中,可以帮助调试和评估 CUDA 应用程序的性能。这些用于 GPU 开发的工具已经与 H100 体系结构兼容。此外,Nsight Systems 现在还支持 NVIDIA Grace CPU 体系结构,用于全系统性能评测。
Nsight Systems 是一个跟踪和分析平台硬件指标的工具,如 CPU 和 GPU 之间的交互,以及统一时间线上的 CUDA 应用程序、 API 和库。CUDA Toolkit 12.2 中提供的 2023.2 版本引入了 Python 回溯采样功能。
GPU 加速的Python 正在改变人工智能工作负载。通过对 Python 代码的定期采样,Nsight Systems 的时间线可以更深入地了解重构中涉及的算法,以最大限度地利用 GPU。Python 采样结合了多节点分析和网络度量收集,有助于优化数据中心规模的计算。想要了解更多关于 如何使用 Nsight Systems 加速数据中心和 HPC 性能分析 的信息,请点击此处。
Nsight Compute提供了对在 GPU 上运行的 CUDA 内核的详细性能评估和分析。2023.2 版本在摘要页面上添加了一个新的检测到的性能问题的排序列表,包括估计的加速以纠正问题。此列表旨在帮助用户避免在不必要的问题上花费时间,从而为性能调优提供指导。
添加的另一个关键功能是源页面上源行级别的性能规则标记。以前,检测到的内置性能规则问题仅显示在详细信息页面上。现在,问题在源页面上用警告图标进行标记。性能指标确定位置。
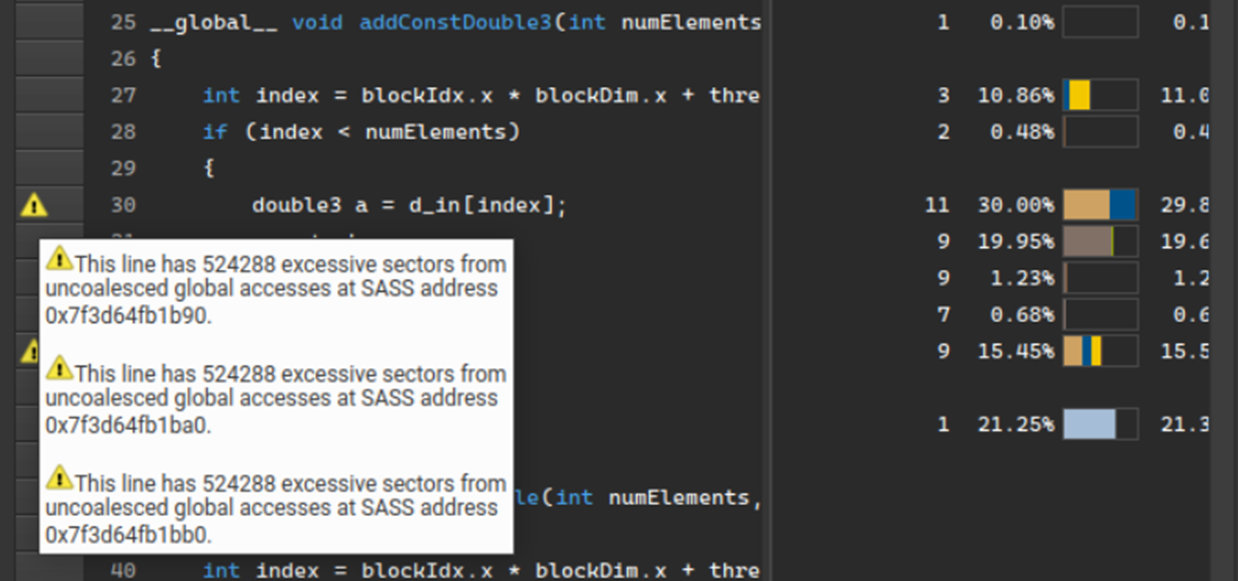
这些新功能扩展了高级摘要视图和低级源代码视图的引导分析,进一步改进了 Nsight Compute 性能评测和分析功能。
CUDA Toolkit 12 . 2 还为您提供最新的调试工具。其中包括:
- NVIDIA Compute Sanitizer 用于检查功能的正确性。
- CUDA-GDB 用于命令行 CPU 和 GPU 的调试。
- NVIDIA Nsight Visual Studio Code Edition可用于集成 CUDA 调试的 IDE。
了解如何使用 Compute Sanitizer 调试 CUDA 代码。
总结
最新发布的 CUDA Toolkit 引入了一些新功能,这些功能对提升 CUDA 应用程序至关重要,为加速计算应用程序奠定了基础。从芯片架构来看,NVIDIA DGX Cloud 和 NVIDIA DGX SuperPOD 平台、AI Enterprise software 和图书馆,以及实现安全和 accelerated network 连接的 CUDA 工具包,提供了无与伦比的全栈优化。NVIDIA DGX Cloud、NVIDIA DGX SuperPOD、AI Enterprise software 和 accelerated network。
还有任何问题吗?立即注册,加入我们的 CUDA 专家行列,参加 2023 年 7 月 26 日举行的特别 AMA,涵盖 CUDA 12 中的所有内容:https://nvda.ws/3XEcy2m。
有关详细信息,请参阅以下内容:
- NVIDIA CUDA 工具包
- CUDA 工具包 12.2 版本发布说明
- NVIDIA Hopper 架构
- CUDA 兼容性
- NVIDIA 发布开源 GPU 内核模块
- GPU 加速库
- NVIDIA Nsight Compute 以及 NVIDIA Nsight Systems