随着新一代产品的推出, NVIDIA GPU 的性能也变得越来越强大。这种提升通常有两种形式。每个流多处理器 (SM) (GPU 的主力) 都可以更快地执行指令,而内存系统可以以越来越快的速度向 SM 传输数据。
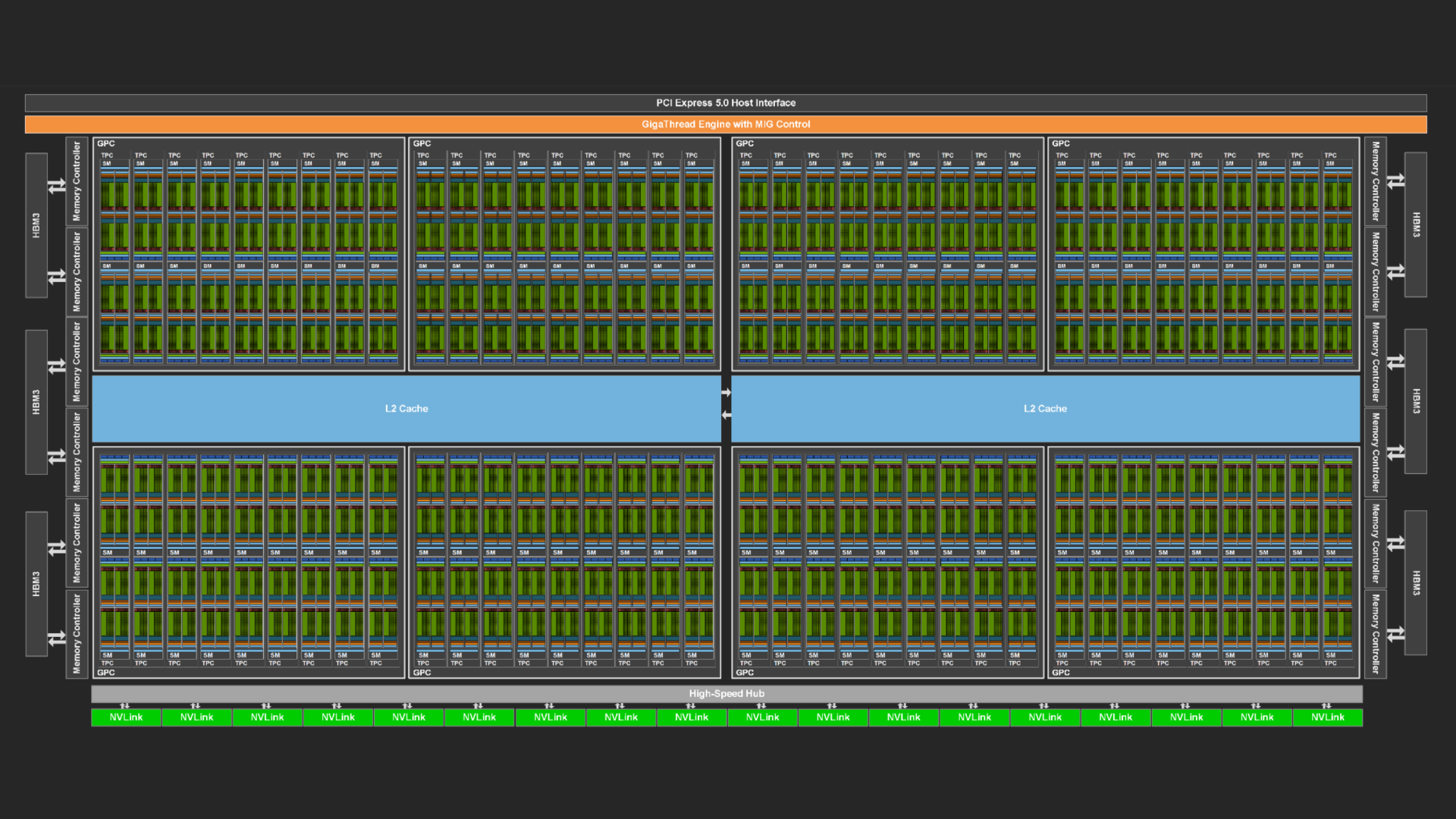
与此同时,SM 的数量通常也会随着每一代的增加而增加,这增加了 GPU 可以支持的计算并发量。例如, NVIDIA Volta、 NVIDIA Ampere 和 NVIDIA Hopper GPU 分别支持 80、108 和 132 个 SM。
在某些情况下,不断增长的并发可能会带来一个挑战。在 GPU 上运行的工作负载必须公开相应的并发级别,才能使 GPU 资源得到充分利用。为此,一种常见的方法是使用多个流向 GPU 发送独立的任务,或者类似地,使用 CUDA 的多进程服务。
本文介绍了一种确定这些方法是否成功占用 GPU 的方法。
在 Santa Clara,我们遇到了一个问题,
我们的 NVIDIA Nsight Systems 性能分析工具可用于确定称为核函数的工作块是否在 GPU 上执行。流通常包含一系列依次运行的核函数。每个流可以在其自己的 Nsight Systems 时间轴上查看,从而揭示不同流中的核函数之间的重叠。例如,图 1 中的标记为“Stream 15”到“Stream 22”的行展示了重叠的核函数。

或者,所有流都可以显示在单个时间轴上,这样可以全面了解 GPU 在执行工作负载期间的使用频率 (图 1,行标记为“所有流”)。
标准 Nsight Systems 时间轴无法立即显示 GPU 的 SM 数量。您可以在弹出视图中突出显示特定内核并检查其属性,包括每个线程块中的线程数、网格大小 (属于内核的线程块总数),甚至理论占用率 (一个 SM 上可以容纳的线程块的最大数量)。
您可以通过这些属性计算执行内核所需的 SM 数量。如果该数量不是 GPU 上 SM 总数的整数倍,则可以将任何剩余的 SM (内核的“tail”) 分配给一个或多个其他内核的线程块。
通过使用多个流 (本文的重点) 启用不同内核的并发执行。要概述整个多流工作负载平均使用 GPU 的情况,就需要在所有流的 Nsight Systems 时间轴中拼凑出并发内核的尾部。可以利用 Nsight Systems 的一些特殊功能来快速轻松地完成这个原本不重要的过程。
通过 GPU 指标采样来抢险
工作负载或其特定部分的 Nsight Systems 报告可以标准化的 SQLite 数据库文件形式提取数据。此 SQLite 文件也可以作为工作负载统计数据的副产品,并使用 Linux 命令 `nsys stats` (在本文中重点介绍 Linux 操作系统,但也可以在 Windows 上获得类似的结果) 来汇总。
在 CUDA 工具包 11.4 中引入 Nsight Systems 版本 2021.2.4 后,可以将特殊标志传递给工作负载分析命令,以帮助实现预期目标:
nsys profile --gpu-metrics-device=N
在这个标志中,N 代表要采样的多 GPU 节点中 GPU 的序列号。如果您使用的是单个 GPU,则 N 等于 0。
设置此标志后,Nsight Systems 将在默认频率 10 KHz 或用户指定的采样频率下记录正在使用的所有 SM 的百分比(SM 有源)。此数量可以在其自己的时间轴上查看。
图 2 展示了特写示例以及整个应用程序的概述。**源代码可见**。这有助于更深入地了解 GPU 的使用情况,但需要打开 Nsight Systems 的图形用户界面。


最适合此任务的分析工具是 `nsys stats`,但仅使用此命令将仅显示 CPU 和 GPU 活动的摘要,这可能不足以提供有价值的信息。更详细的分析需要额外的说明。
然而,通过数据库查询语言 (SQL) 结构化查询语言,可以从 Nsight Systems 报告衍生的 SQLite 文件中提取所需的所有内容。SQLite 文件在逻辑上被结构化为表的集合,并可以使用简单的 SQL 命令提取任何表列。与正在使用的 SM 百分比对应的列为 SM Active。
形式上,报告的数量是 SM 活动的平均值。50%可能意味着所有 SM 在 50%的时间内都处于活动状态,或 50%的 SM 在 100%的时间内处于活动状态,或者介于两者之间的任何情况,但实际上,我们先前的定义优先。
如果您不熟悉 SQL,请利用 Nsight Systems 版本 2023.4 中引入的 DataService 功能。它提供了一个方便的 Python 接口,用于查询所收集报告中嵌入的 SQLite 数据库。以下脚本使用 DataService 提取工作负载 SM 活动百分比列表,并导出几个有用的数量。
import sys
import json
import pandas as pd
from nsys_recipe import data_service, log
from nsys_recipe.data_service import DataService
# To run this script, be sure to add the Nsight Systems package directory to your PYTHONPATH, similar to this:
# export PYTHONPATH=/opt/nvidia/nsight-systems/2023.4.1/target-linux-x64/python/packages
def compute_utilization(filename, freq=10000):
service=DataService(filename)
table_column_dict = {
"GPU_METRICS": ["typeId", "metricId", "value"],
"TARGET_INFO_GPU_METRICS": ["metricName", "metricId"],
"META_DATA_CAPTURE": ["name", "value"]
}
hints={"format":"sqlite"}
df_dict = service.read_tables(table_column_dict, hints=hints)
df = df_dict.get("GPU_METRICS", None)
if df is None:
print(f"{filename} does not contain GPU metric data.")
return
tgtinfo_df = df_dict.get("TARGET_INFO_GPU_METRICS", None)
if tgtinfo_df is None:
print(f"{filename} does not contain TARGET_INFO_GPU_METRICS table.")
return
metadata_df = df_dict.get("META_DATA_CAPTURE", None)
if metadata_df is not None:
if "GPU_METRICS_OPTIONS:SAMPLING_FREQUENCY" in metadata_df['name'].values:
report_freq = metadata_df.loc[ metadata_df['name']=='GPU_METRICS_OPTIONS:SAMPLING_FREQUENCY']['value'].iat[0]
if isinstance(report_freq, (int,float)):
freq = report_freq
print("Setting GPU Metric sample frequency to value in report file. new frequency=",freq)
possible_smactive=['SMs Active', 'SM Active', 'SM Active [Throughput %]']
smactive_name_mask = tgtinfo_df['metricName'].isin(possible_smactive)
smactive_row = tgtinfo_df[smactive_name_mask]
smactive_name = smactive_row['metricName'].iat[0]
smactive_id = tgtinfo_df.loc[tgtinfo_df['metricName']==smactive_name,'metricId'].iat[0]
smactive_df = df.loc[ df['metricId'] == smactive_id ]
usage = smactive_df['value'].sum()
count = len(smactive_df['value'])
count_nonzero = len(smactive_df.loc[smactive_df['value']!=0])
avg_gross_util = usage/count
avg_net_util = usage/count_nonzero
effective_util = usage/freq/100
print(f"Avg gross GPU utilization:\t%lf %%" % avg_gross_util)
print(f"Avg net GPU utilization:\t%lf %%" % avg_net_util)
print(f"Effective GPU utilization time:\t%lf s" % effective_util)
return metadata_df
if __name__ == '__main__':
if len(sys.argv)==2:
compute_utilization(sys.argv[1])
elif len(sys.argv)==3:
compute_utilization(sys.argv[1], freq=float(sys.argv[2]))
如果将所有百分比的总和(Sp)以及样本数量(Ns)相除,则得到在整个工作负载期间使用的所有 SM 的平均百分比。这种平均百分比被称为GPU 总利用率。
这可能正是所需的结果,但通常工作负载包含一些完全没有启动内核的部分。例如,数据从主机 CPU 复制到 GPU 时。通过自动监控采样点的 SM 使用百分比是否大于零(让该样本数 Nsnz)和计算 Sp/Nsnz 在可测量的内核执行期间提供 SM 的平均使用百分比。我们将其称为 *GPU 净利用率*。
最后,对于特定工作负载或部分工作负载,计算在压缩所有样本后 GPU 的有效使用时间可能很有用。例如,如果样本显示在 5 秒内 SM 利用率为 40%,则 GPU 的有效利用率为 0.4 × 5 秒 = 2 秒。可以将此时间与执行相关内核的 Nsight Systems 时间轴的持续时间进行比较。让该持续时间代表深度学习,并让有效 GPU 利用率的总和代表 Sdt/Dt,其中 Sdt 是相关窗口中的 SM 利用率,而 Dt 是窗口的持续时间。
举个例子
以下场景展示了这三个量的效用,并将其应用于逼真的工作负载 (图 4)。
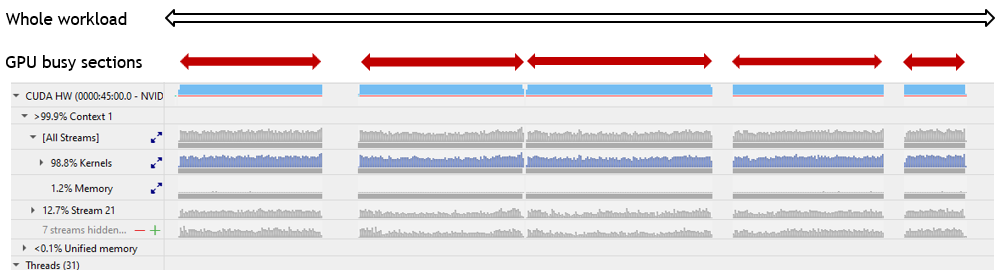
数量 Sp/Ns 表示在整个工作负载中使用 SM 的平均百分比,由图 4 中的开放、黑色和双头箭头表示,包括在没有 SM 活动时围绕密集的蓝色内核执行块的六个周期。对于此工作负载,该百分比为 70%。
数量 Sdt/时间 = 100 表示在 GPU 繁忙时间使用 SM 的平均百分比,由图 4 中的实心、红色双头箭头表示。这包括五个繁忙窗口中的短嵌入式部分,当时暂时没有执行核函数(在表示整个工作负载的图的比例上不可见)。对于此工作负载,该百分比为 77%。
数量 Sp/Nsnz 表示在 Nsight Systems 确定至少有一个 SM 处于忙碌状态时使用的 SM 的平均百分比。此百分比忽略了五个 GPU 忙碌期间没有 SM 活动的任何短嵌入式周期。对于此工作负载,该百分比为 79%,
未来
NVIDIA 分析工具持续添加新功能。例如,最近的 NVIDIA 分析工具开发版本引入了新的谱,使分析集群级应用程序和性能回归研究变得更轻松。
NVIDIA 正在关注通过流行的 Python 脚本语言提供对 Nsight System GPU 性能详细信息的访问,以消除学习 C 或 SQL 等其他语言的需求。Nsight Systems 功能的其他近期新增功能包括:统计分析 和 专家系统分析。
结束语
对此示例工作负载的分析表明,在某些时间段内,SM 完全不使用,但总体 SM 空闲时间有限。
在 SM 繁忙窗口期间,GPU 相当饱和,特别是考虑到网格和线程块的大小差异很大,一些网格仅包含单个线程块,因此只能占用单个 SM.因此,构成工作负载的多个流能够很好地提高 GPU 利用率。
我们毫不费力地得出了这一见解。用于确定本文中提到的三个利用率指标的 Python 脚本假设用户为旧版 Nsight Systems 获取的输入报告明确提供采样频率,允许此类版本采用 10 KHz 的默认值,或者可以从较新版本 Nsight Systems 的输入报告中提取样本频率。
SM 利用率高并不意味着 SM 得到了高效利用。由于各种原因,在 SM 上执行的内核可能会出现严重甚至极端停滞。SM 利用率高的唯一事实是,大多数 GPU 的 SM 在大多数时候都处于活动状态,这是获得良好性能的前提。
有关更多信息,请参阅以下资源:
- CUDA 工具包 提供用于加速计算的工具和框架。
- 立即开始使用 Nsight Systems
- 立即开始使用 Nsight 计算。
- 深入了解并提出问题 CUDA 开发者论坛,以获得专业建议和解决方案。