我们被卡住了。真的卡住了。随着艰难的交付截止日期的临近,我们的团队需要弄清楚如何在几个小时内处理数万亿销售点交易记录的复杂提取转换负载( ETL )工作。这项工作的结果将为一系列下游机器学习( ML )模型提供信息,这些模型将为全球零售商做出关键的零售分类分配决策。这些模型需要在真实的事务数据上进行测试和验证。
然而,到目前为止,还没有一个 ETL 作业完成。每次测试运行都需要几天的处理时间,所有测试都必须在完成前终止。
使用 NVIDIA RAPIDS Accelerator for Apache CPU ,与在 Spark 上使用 Spark 的传统方法相比,我们观察到运行时间显著加快,并节省了额外的成本。让我们后退一点。
摆脱困境:全球零售商的 ETL
凯捷的人工智能与分析实践是一个数据科学团队,提供定制的、平台无关的和语言无关的解决方案,这些解决方案涵盖了数据科学的全部范畴,从数据工程到数据科学,再到机器学习工程和 MLOps 。我们拥有一支拥有丰富技术经验和知识的团队,其中包括 100 多名北美数据科学顾问,以及 1600 多名全球数据科学家。
对于该项目,我们的任务是为一家国际零售商提供端到端的解决方案,包括以下可交付成果:
- 创建基础 ETL
- 构建一系列 ML 模
- 创建优化引擎
- 设计基于网络的用户界面,以可视化和解释所有数据科学和数据工程工作
这项工作最终为每个零售店提供了一个最佳的零售分类分配解决方案。使该项目更加复杂的是,在我们开始引入光环效应(例如跨部门的交互效应)后,状态空间爆炸。例如,如果我们将货架空间分配给水果,这对与将货架空间进一步分配给蔬菜相关的 KPI 有什么影响,我们如何共同优化这些交互效应?
但是,如果没有基本的 ETL , ML 、优化或前端都无关紧要。所以我们被卡住了。我们在 Azure 云环境中使用 Databricks 和 Spark SQL 进行操作,即使在那时,我们也没有在下游模型要求的时间内观察到我们需要的结果。
在紧迫感的刺激下,我们探索了可能使我们能够显著加快 ETL 过程的潜在变化。
加速 ETL
代码的编写效率低吗?它是否最大限度地提高了计算速度?它必须被重构吗?
我们重写了几次代码,并测试了各种集群配置,结果只是观察到了边际收益。然而,由于成本限制,我们扩大规模的选择有限,没有一个能提供我们取得重大收益所需的马力。还记得为期末考试临时抱佛脚的时候吗?当时时间有点紧,你肚子里的坑一分钟比一分钟深?我们很快就没有选择和时间了。我们需要帮助。现在
在 Databricks Runtime 9 . 1 LTS 中, Databrickss 发布了一个名为 Photon 的原生矢量化查询引擎。 Photon 是一个 C ++运行时环境,与传统的 Java 运行时环境相比,它可以运行得更快,并且更可配置。数周来, Databricks 支持帮助我们为 ETL 应用程序配置 Photon 运行时。
我们还联系了 NVIDIA 的合作伙伴,他们最近更新了 RAPIDS 加速软件库套件。基于 CUDA -X AI , RAPIDS 完全在 GPU 上执行数据科学和分析管道,其 API 看起来和感觉都像最流行的开源库。它们包括一个与 Spark 的查询计划器集成的插件,以加快 Spark jobs 的速度。
在接下来的一个月里,在 Databricks 和 NVIDIA 的支持下,我们并行开发了这两种解决方案,将之前无法维持的运行时间降至两小时以下,速度惊人!
这是我们需要达到的下游 ML 和优化模型的目标速度。压力消除了,仅仅是因为比我们使用 RAPIDS 提前几天解决了 Photon 的 ETL 问题, Databricks Photon 解决方案就投入了生产。
从围绕 ETL 过程的紧迫截止日期的焦虑中走出来后,我们收集了我们的想法和结果,并进行了事后分析。哪种解决方案实施得最快?哪种解决方案提供了最快的 ETL ?最便宜的 ETL ?我们将为类似的未来项目实施哪种解决方案?
实验结果
为了评估我们的假设,我们创建了一组实验。我们使用两种方法在 Azure 上进行了这些实验:
- Databricks Photon 将在第三代 Intel Xeon Platinum 8370C (冰湖) CPU 上以超线程配置运行。这就是最终为客户投入生产的产品。
- RAPIDS Apache 加速器 Spark 将在 NVIDIA GPU 上运行。
我们将使用两个不同的数据集在两者上运行相同的 ETL 作业。数据集是 5 列和 10 列混合的数字和非结构化(文本)数据,每列有 2000 万行,分别为 156 和 565 TB 。在基础设施支出限制允许的情况下,最大限度地增加了工人人数。每个单独的实验进行三次。
实验参数汇总在表 1 中。
| 工人类 | 驱动程序类 | 工人人数 | 站台 | 列数 | 数据大小 |
| 标准_ NC6s _ v3 | 标准_ NC6s _ v3 | 12 | RAPIDS | 10 | 565 |
| 标准_ E20s _ v5 | 标准_ E16s _ v5 | 6 | PHOTON | 10 | 565 |
| 标准_ NC6s _ v3 | 标准_ NC6s _ v3 | 16 | RAPIDS | 10 | 565 |
| 标准_ NC6s _ v3 | 标准_ NC6s _ v3 | 14 | RAPIDS | 10 | 565 |
| 标准_ NC6s _ v3 | 标准_ NC6s _ v3 | 14 | RAPIDS | 5 | 157 |
| 标准_ E20s _ v5 | 标准_ E16s _ v5 | 6 | PHOTON | 5 | 148 |
我们研究了运行时的纯速度。实验结果表明,工人类型、驾驶员类型、工人、数据集大小、平台、数据列和数据集大小的所有不同组合的运行时间都非常一致,平均每次运行 4 分 37 秒,最小和最大运行时间分别为 4 分 28 秒和 4 分 54 秒。
我们有一个 DBU /小时的基础设施支出限制,因此,每个测试集群的不同工人也有限制。作为回应,我们开发了一种复合指标,能够对结果进行最平衡的评估,我们将其命名为每分钟调整 DBU ( ADBU )。 DBU 是 Databricks 单元,是计算成本的专有 Databrickss 单元。 ADBU 计算如下:
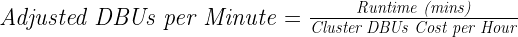
总的来说,考虑到云平台成本,与在 Photon 运行时运行 Spark 相比,我们观察到使用 RAPIDS Accelerator for Apache Spark ADBU 减少了 6% 。这意味着我们可以使用 RAPIDS 以更低的成本实现类似的运行时间。
注意事项
其他考虑因素包括实现的容易性和重写代码的必要性,这两者对于 RAPIDS 和 Photon 来说都是相似的。第一次实施这两种方法都不适合胆小的人。
完成一次后,我们非常确信,我们可以在几个小时内为每个任务复制所需的集群配置任务。此外, RAPIDS 和 Photon 都不需要我们重构 Spark SQL 代码,这节省了大量时间。
该实验的局限性是复制次数少,工人和驱动程序类型的数量有限,以及工人组合的数量,所有这些都是由于基础设施成本的限制。
接下来是什么?
最后,将 Databricks 与 RAPIDS AcceleratorforApache Spark 相结合,有助于扩展我们的数据工程工具包的广度,并展示了 GPU 上 ETL 处理的新的可行范例。
想要了解更多信息,请访问 RAPIDS 加速器 for Apache Spark。