
随着生成式 AI 模型的持续创新,生成式 AI 在计算应用方面取得了巨大进步,从而大幅增强人类能力。这些模型包括 生成式 AI 模型,例如 大型语言模型 (LLM),用于创作营销文案、编写代码、渲染图像、作曲和生成视频等。随着新模型的不断出现,所需的计算量也随之增加。
生成式 AI 的计算强度要求芯片、系统和软件要卓越。MLPerf 推理是一个基准套件,用于衡量多个热门深度学习用例的推理性能。最新版本 MLPerf Inference v4.0 加入两个新工作负载,代表了热门的现代生成式 AI 用例。其中一个是基于最大的 Meta Lama 2 系列大型语言模型 (LLM) 的 LLM 基准测试,以及另一个是基于 Stable Diffusion XL 稳定漫反射的。
NVIDIA 加速计算平台利用 NVIDIA H200 Tensor Core GPU。其 TensorRT-LLM 软件在 NVIDIA H100 Tensor Core GPU 上加速了 GPT-J LLM 的推理。NVIDIA Hopper 架构的 GPU 在数据中心类别的所有 MLPerf 推理工作负载中提供了更高的性能。此外,NVIDIA 在 MLPerf 推理的开放分区中提交了一些内容,展示了其模型和算法的创新。
在本文中,我们将介绍这些创记录的生成式 AI 推理性能成就背后的众多全栈技术。
TensorRT-LLM 将 LLM 推理性能提升近三倍
基于 LLM 的服务 (例如聊天机器人) 必须快速响应用户查询并具有成本效益,这需要高推理吞吐量。生产推理解决方案必须能够同时为具有低延迟和高吞吐量的先进 LLM 提供服务。
TensorRT-LLM 是一个高性能开源软件库,可在 NVIDIA GPU 上运行最新的 LLM 时提供先进的性能。
MLPerf Inference v4.0 包括两项 LLM 测试。第一项是上一轮 MLPerf 中引入的 GPT-J,第二项是新添加的 Lama 2 70B 基准测试。使用 TensorRT-LLM 的 H100 Tensor Core GPU 在离线和服务器场景中在 GPT – J 上分别实现了 2.4 倍和 2.9 倍的加速。与上一轮提交的测试相比。TensorRT – LLM 也是 NVIDIA 平台在 Lama 2 70B 测试中的出色性能的核心。
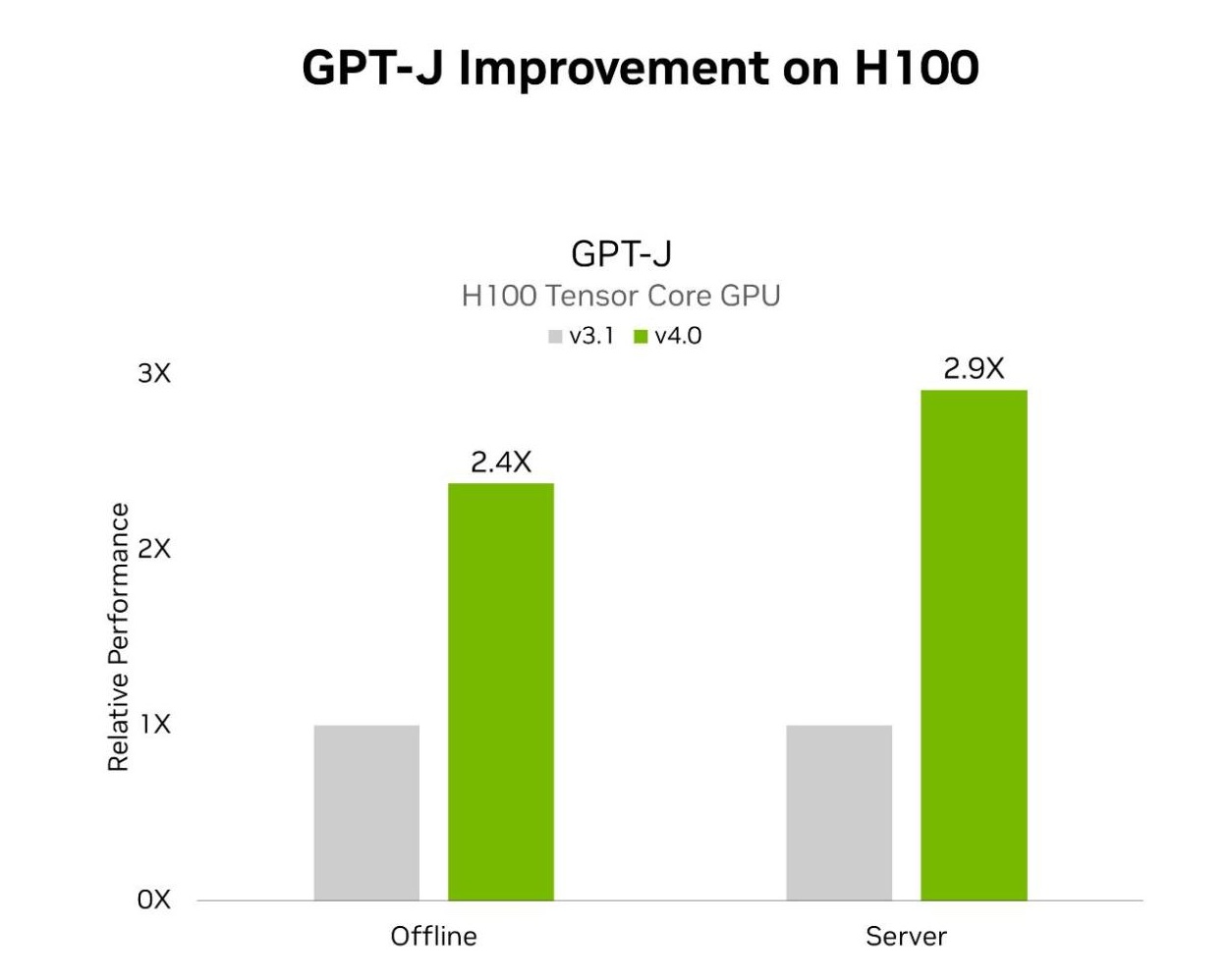
MLPerf Inference v3.1 和 v4.0 数据中心结果于 2024 年 3 月 27 日从 www.mlperf.org 的条目 3.1-0107 和 4.0-0060 中检索。MLPerf 名称和徽标是 MLCommons 协会在美国和其他国家地区注册的注册和未注册商标。所有权利保留。严禁未经授权使用。有关更多信息,请参阅 www.mlcommons.org。
以下是 TensorRT-LLM 的一些关键功能,这些功能实现了出色的性能结果:
- **机上序列批处理** 在 LLM 推理期间提高 GPU 利用率的策略,通过更好地交错推理请求以及在完成处理并插入新请求后立即分批逐出请求。
- 分页 KV 缓存 通过将 KV 缓存分成非连续内存块并将其存储在其中,并按需分配和移除内存块,以及在注意力计算期间动态访问内存块,从而提高内存消耗和利用率。
- **量化并行** 支持使用 NCCL 在 GPU 和节点之间拆分权重进行通信,以实现大规模高效推理。
- 量化支持 FP8 量化,它利用 NVIDIA Hopper 架构的第四代 Tensor Core 来减少模型大小并提高性能。
- XQA 内核 以高性能实现注意力机制,支持 MHA、MQA 和 GQA,以及波束搜索,从而在给定的延迟预算内显著提高吞吐量。
有关 TensorRT-LLM 功能的更多详细信息,请参阅此博文:TensorRT-LLM 如何加速 LLM 推理。
H200 Tensor Core GPU 强效助力 LLM 推理
H200 基于 Hopper 架构,是全球首款使用业内最先进 HBM3e 显存的 GPU.H200 采用 141 GB 的 HBM3e,显存带宽为 4.8 TB/s,与 H100 相比,GPU 显存增加了近 1.8 倍,GPU 显存带宽增加了 1.4 倍。
通过将更大、更快速的显存和新的定制散热解决方案相结合,与本轮提交的 H100 相比,H200 GPU 在 Lama 2 70B 基准测试中实现了巨大的性能提升。
HBM3e 实现更高性能
与 H100 相比,H200 的升级 GPU 显存在两个重要方面有助于在处理 Lama 2 70B 工作负载时释放更多性能。
在 MLPerf Lama 2 70B 基准测试中,它无需进行张量并行或管线并行执行,以获得最佳性能。这减少了通信开销并提高了推理吞吐量。
其次,与 H100 相比,H200 GPU 具有更高的显存带宽,缓解了工作负载中显存带宽受限部分的瓶颈,并提高了 Tensor Core 的利用率。这提高了推理吞吐量。
定制冷却设计进一步提升性能
TensorRT-LLM 中的广泛优化与 H200 的升级显存相结合,意味着 H200 上的 Lama 2 70B 执行受到计算性能的限制,而不会受到显存带宽或通信瓶颈的限制。
由于 NVIDIA HGX H200 与 NVIDIA HGX H100 兼容,因此它为系统制造商提供了认证系统的能力,以更快地将产品推向市场。正如 NVIDIA MLPerf 在本轮提交的结果所表明的那样,H200 在与 H100 相同的 700 W 热设计功耗 (TDP) 下,可提供高达 28%的 Lama 2 70B 推理性能。
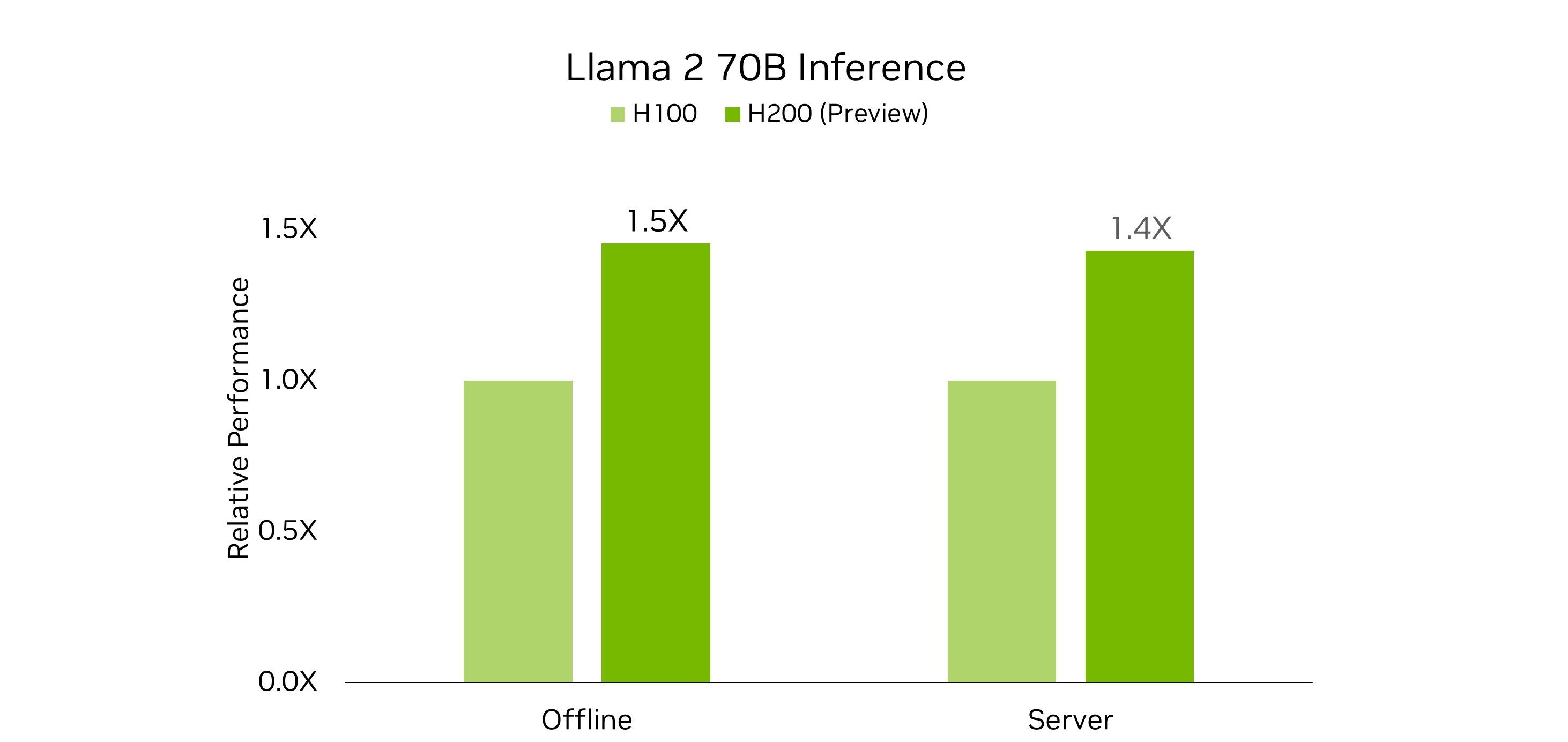
MLPerf Inference v4.0 数据中心结果检索自 mlperf.org,于 2024 年 3 月 27 日发布。结果来自 4.0-0062 和 4.0-0068。MLPerf 的名称和徽标为 MLCommons Association 在美国和其他国家/地区的注册商标和未注册商标。所有权利保留。未经授权使用受禁止。有关更多信息,请参阅 mlcommons.org。
借助 NVIDIA MGX,系统组装商可以通过定制冷却设计为客户提供更多价值,从而实现更高的 GPU 散热。在这一轮中, NVIDIA 还提交了使用 H200 的定制散热设计,使 GPU 能够在更高的 1000 W TDP 下运行。在运行 Lama 2 70B 基准测试时,这将使服务器和离线场景中的性能分别提高 11%和 12%,与 H100 相比,总加速分别提高 43%和 45%。
为 Stable Diffusion XL 设置性能标准
Stable Diffusion XL 稳定漫反射是以下内容组成的文本转图像生成 AI 模型:
- 两个 CLIP 模型,用于将提示文本转换为嵌入。
- 由残差块 (ResBlocks) 和转换器组成的 UNet 模型,可在较低分辨率的隐空间对图像进行迭代降噪。
- 变分自动编码器 (VAE),可将隐空间图像解码为分辨率为 1024 × 1024 的 RGB 图像输出。
在 MLPerf Inference v4.0 中,Stable Diffusion XL 用于文本转图像测试,根据提供的文本提示生成图像。
采用 TensorRT 软件的 NVIDIA GPU 在 MLPerf Inference v4.0 文本转图像测试中提供了更高的性能。8-GPU NVIDIA HGX H200 系统 (GPU 配置为 700W TDP) 在服务器和离线场景中分别实现了 13.8 条查询/秒和 13.7 个样本/秒的性能。
L40S 是性能超强的通用 NVIDIA GPU,专为 AI 计算、图形和媒体加速领域的突破性多工作负载性能而设计。Stable Diffusion XL 提交使用配备 8 个 L40S GPU 的系统,在服务器和离线场景中分别展示了 4.9 条查询/秒和 5 个样本/秒的性能。

NVIDIA 提出了一种创新方法,将 UNet 中的 ResBlock 和 Transformer 部分量化为 INT8 精度。在 ResBlocks 中,卷积层被量化为 INT8,而在 Transformer 中,查询键值块和前馈网络线性层被量化为 INT8. 仅从前八个降噪步骤 (共 20 个) 中收集 INT8 绝对最大值。SmoothQuant 用于量化线性层的激活,克服了将激活量化为 INT8 的挑战,同时保持原始准确性。
与不属于 NVIDIA MLPerf 提交内容的 FP16 基准相比,这项工作将 H100 GPU 的性能提升了 20%。
此外,TensorRT 支持扩散模型的 FP8 量化,这将提高性能和图像质量并即将推出。
开放式划分创新
除了在 MLPerf Inference 的封闭分区中提交出色性能外, NVIDIA 还在开放分区中提交了几项提交内容。根据 MLCommons,开放分区“旨在促进创新,并允许使用不同的模型或重新训练。”
在这一轮中, NVIDIA 提交了公开分割结果,这些结果利用了 TensorRT 中的各种模型优化功能 (例如稀疏化、剪枝和缓存)。这些结果用于 Lama 2 70B、GPT-J 和 Stable Diffusion XL 工作负载,在保持高精度的同时展示了出色的性能。以下小节概述了为这些提交提供支持的创新。
采用结构化稀疏技术的 Llama 2 70B
基于 H100 GPU 的 NVIDIA 开放分割提交展示了使用 结构化稀疏 Hopper Tensor Core 的能力。模型的所有注意力和 MLP 块的结构化稀疏,并且该过程在训练完成后完成,无需对模型进行任何微调。
这种稀疏模型具有两个主要优势。首先,模型本身缩小了 37%.缩小后的模型和 KVCache 可以完全适应 H100 的 GPU 显存,从而无需张量并行性。
接下来,使用 2:4 的稀疏 GEMM 内核提高了计算吞吐量,并更高效地利用内存带宽。与 NVIDIA 封闭除法提交相比,离线场景中相同 H100 系统的总体吞吐量高出 33%.通过这些加速,稀疏模型仍然达到了 MLPerf 封闭除法设置的严格的 99.9%准确率目标。与封闭除法中使用的模型相比,稀疏模型在每个样本中生成的令牌更少,从而缩短了对查询的响应时间。
带有剪枝和提炼功能的 GPT-J
在开放除法 GPT-J 提交中,使用了经过剪枝的 GPT-J 模型。这项技术极大地减少了模型中头层和层的数量,在 H100 GPU 上运行模型时,与封闭除法提交相比,推理吞吐量增加了近 40%.自 NVIDIA 在本轮 MLPerf 中提交结果以来,性能进一步提升了。
然后,使用知识提炼对经过剪枝的模型进行微调,从而实现 98.5%的出色准确率。
使用 DeepCache 的 Stable Diffusion XL
在 Stable Diffusion XL 工作负载的端到端处理中,约有 90%用于使用 UNet 运行迭代降噪步骤。这具有一个由层组成的 U 拓扑结构,其中隐性首先进行下转换,然后上转换回原始分辨率。
DeepCache 文档中介绍了一种技术,建议使用两种不同的 UNet 结构。第一种是原始的 UNet,在我们的提交中称为 Deep UNet。第二种是单层 UNet,称为 Shallow UNet 或 Shallow UNet,它重复使用(或绕过)来自最新 Deep UNet 的中间张量,显著减少了计算。
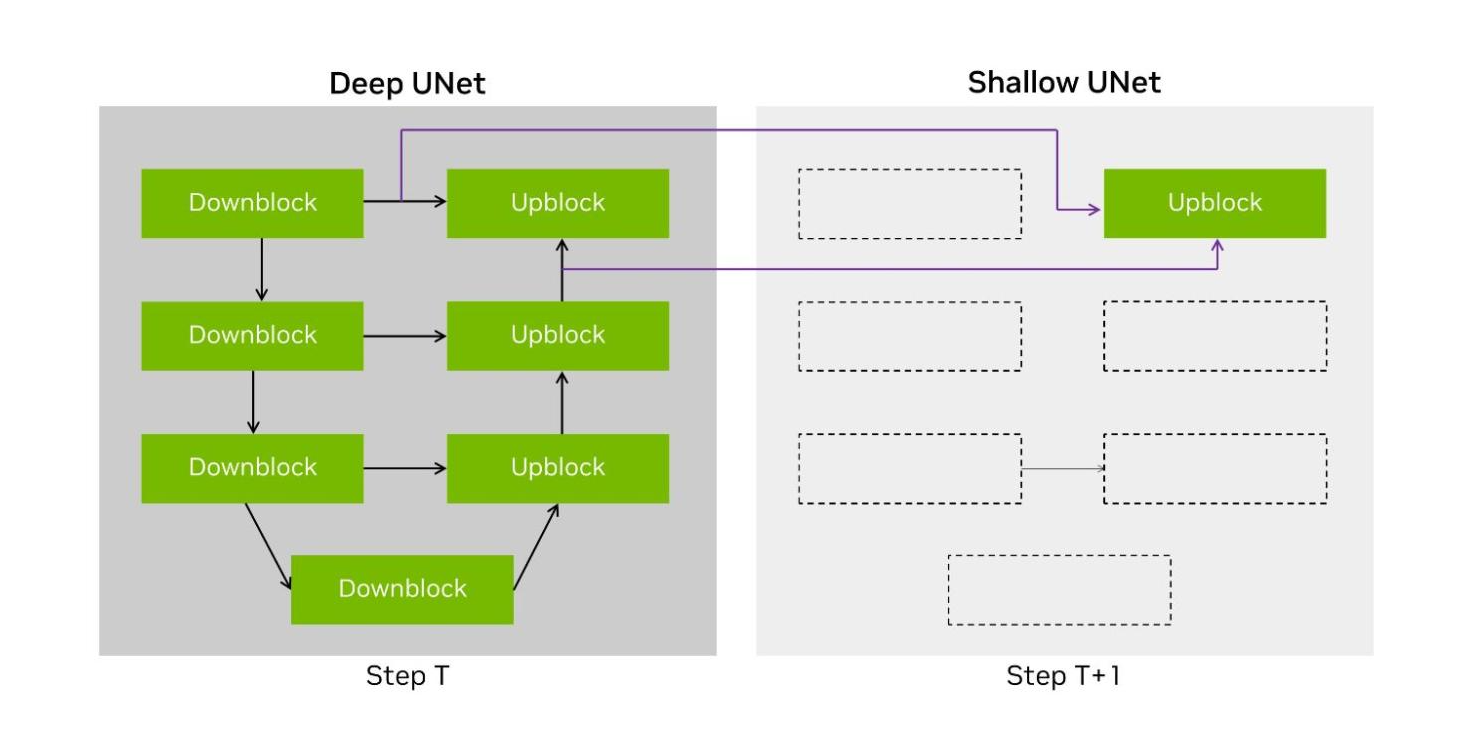
图 4:使用 Deep UNet 和 Shallow UNet 的 DeepCache 技术说明
NVIDIA 开放分割提交实现了 DeepCache 的变体,我们将两个输入缓存到最后一个上转换层,并在降噪步骤之间交替使用 Deep UNet 和 Shallow UNet.这将运行模型的 UNet 部分所需的计算量减少了一半,在 H100 上将端到端性能提高了 74%。
出色的推理性能
NVIDIA 平台在 MLPerf Inference v4.0 基准测试中展示了出色的推理性能,而 Hopper 架构可在每个工作负载上实现每个 GPU 的最高性能。
借助 TensorRT-LLM 软件,H100 在处理 GPT-J 工作负载时实现了出色的性能提升,在短短 6 个月内性能几乎提升了 3 倍。H200 是全球首款采用 TensorRT – LLM 软件的 HBM3e GPU,在离线和服务器场景中,为 Lama 2 70B 工作负载提供了创纪录的推理性能。此外,在首次针对文本转图像生成式 AI 进行的 Stable Diffusion XL 测试中, NVIDIA 平台提供了最高性能。
要重现 NVIDIA MLPerf Inference v4.0 中展示的惊人性能,请参阅 MLPerf 库。



