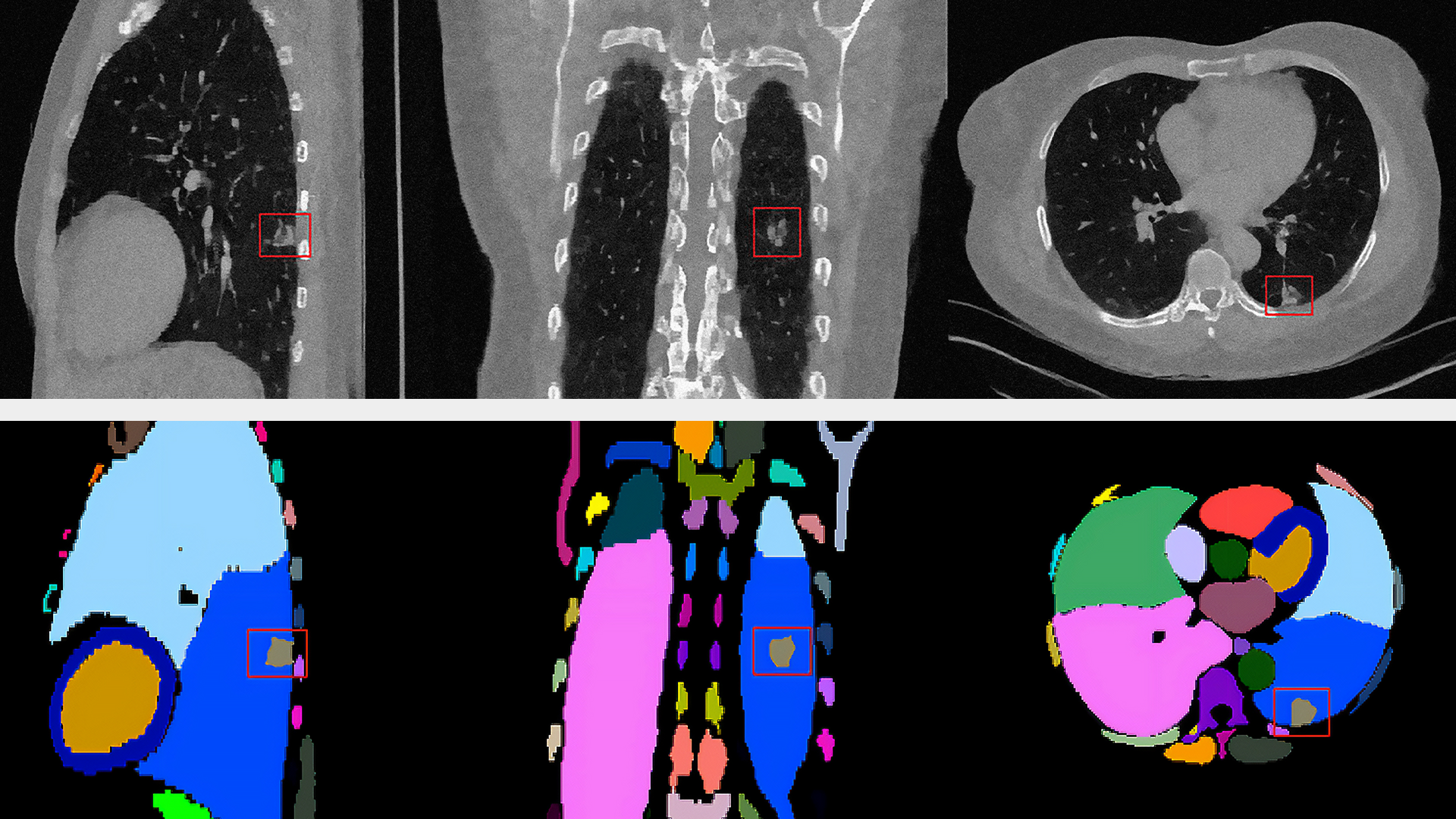
视觉效果生成式 AI是一个根据文本提示创建图像的过程。该技术基于在互联网规模的数据上预训练的视觉语言基础模型。通过提供多模态表示,这些基础模型可以应用于许多领域。例如,包括图像字幕和视频检索、创意3D和2D图像合成以及机器人操作。所有这些任务都得益于视觉语言基础模型的“开放世界”能力,从而能够使用丰富、自由形式的文本和视觉类别的“长尾”。
借助这些强大的表征,我们将面临新的挑战。也就是说,如何将这些模型与用户特定的或个性化的视觉概念结合使用。如何教会这些模型将此类用户特定的概念与他们之前从海量数据集中学到的知识相结合?
例如,玩具品牌的创意总监正在计划围绕新的玩具熊产品开展广告活动,并希望在不同的场景中展示玩具,这些场景包括扮演超级英雄或巫师的角色。或者,孩子希望创作家庭狗的搞笑动画片。或者,室内设计师希望在使用传家宝家庭沙发设计房间。所有这些个性化用例都需要合成新场景,并将特定物品与通用组件相结合。
为应对这一挑战,我们设计了多种算法。此类个性化算法应满足以下质量、易用性和效率目标:
- 捕捉所学概念的视觉特征,同时根据文本提示进行更改。
- 支持在一张图像中结合使用多个已学习的概念。
- 快速运行,每个概念只需占用少量内存。
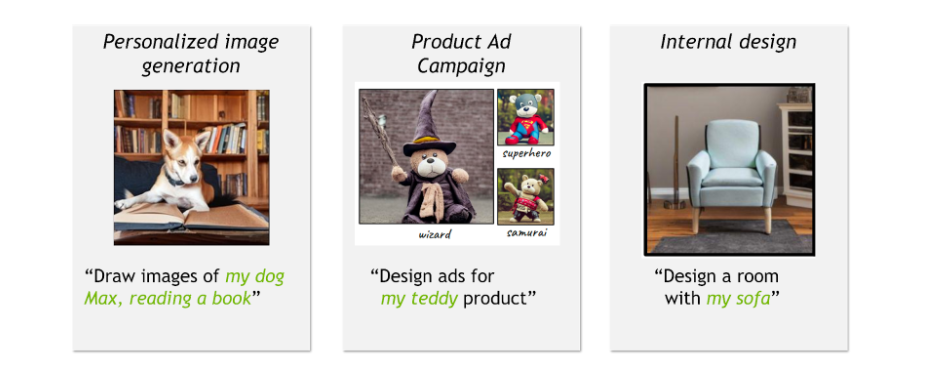
什么是文本反演?
本节通过 文本反演 介绍了个性化生成式 AI 的基本技术。
给定一些概念的训练图像,我们的目标是学习新概念,使基础模型能够以合成方式使用丰富的语言生成图像。概念可以与训练期间未与新概念一起看到的名词、关系和形容词相结合。同时,即使在修改和与其他概念结合时,概念也应保持其“基本”视觉属性。
名为文本反演的方法通过在冻结的视觉语言基础模型的词嵌入空间中查找新词来克服这些挑战(图 2)。这包括学习将新的嵌入向量与用占位符标记的新“伪词”进行匹配 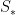
为了找到
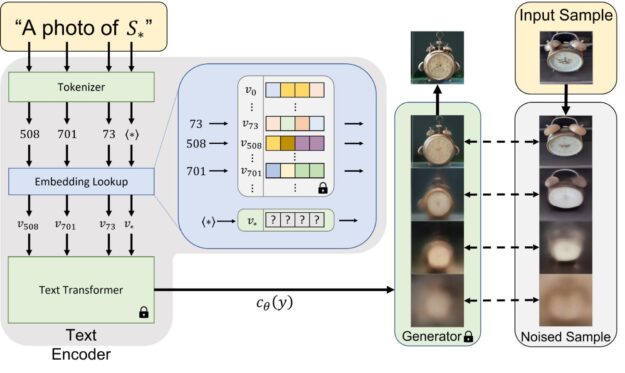
实验性见解
文本转图像个性化支持一系列应用。图 3 通过将学习到的伪词整合到新的文本提示中,显示了新场景的构成。每个概念都从四个示例图像中学习,然后用于新的复杂文本提示。冻结的文本转图像模型可以将大量先前知识与新概念相结合,将它们整合到新的创作中。
令人惊讶的是,虽然学习概念时的训练目标本质上是直观的,但学习的伪词封装了语义知识。例如,碗(下行)可以包含其他对象。

个性化还可以通过使用精心策划的小型数据集,为有偏见的概念学习不太带偏见的新词。然后,可以用这个新词代替原始词,以推动更具包容性的生成(图 4)。

在轻量级模型中进行更好的编辑
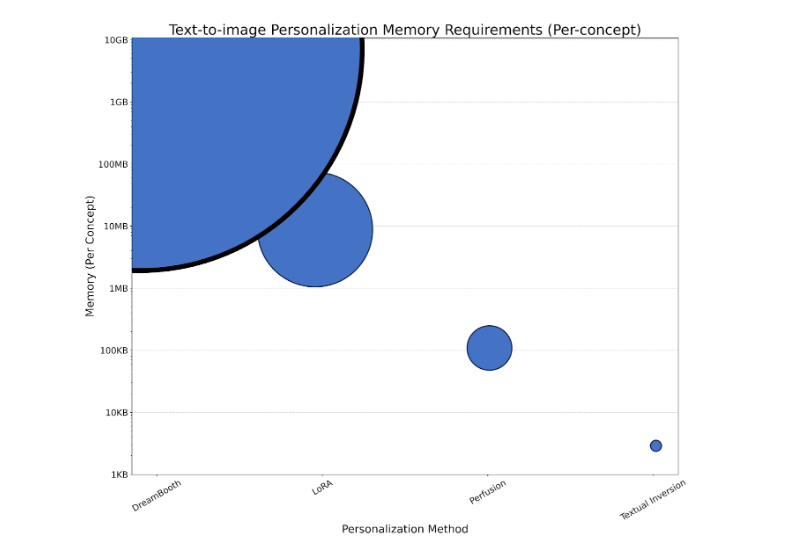
前面介绍的文本反演方法是一种轻量级模型,仅使用 1K 参数对概念进行编码。由于规模很小,需要组合多个概念或严格控制概念与文本时,其质量可能会下降。
另一种模型DreamBooth:针对主题驱动生成微调文本转图像漫射模型调优一个GB大小的U-Net架构会生成一个资源密集型模型,每个概念都需要GB的存储空间,训练速度很慢。LoRA(低阶自适应)可以与DreamBooth结合使用,通过冻结U-Net权重并将较小的可训练矩阵注入特定层来减少其存储占用空间。
我们开始设计一种网络架构和算法,该架构和算法可生成更符合文本提示和视觉特征的图像,同时保持较小的模型尺寸,并支持将多个学习概念组合到单个图像中。
我们提出了一种方法,通过对 1 级模型进行轻量级编辑来应对所有这些挑战,如在 用于文本转图像个性化的 Key-Locked Rank One Editing。这可以实现更好的泛化,同时在 4 – 7 分钟内使用低至 100KB 的存储空间对模型进行个性化处理。
这个想法非常直观。使用 Teddy Bear 的示例,预训练模型可能已经知道生成了扮演超级英雄的普通玩具熊的图像。在这种情况下,首先为普通玩具熊生成图像,“锁定”一些模型组件的激活,然后使用特定的个性化玩具熊重新生成图像。当然,关键是应该锁定哪些组件。
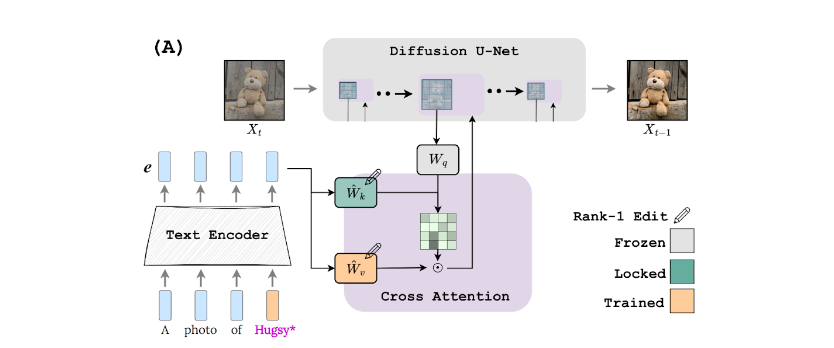
我们的主要见解是,扩散模型(K 矩阵)中交叉注意力模块的关键路径控制着注意力图的布局。事实上,我们观察到现有技术往往过适合该组件,导致对 新词的注意力超出概念本身的视觉范围。
基于这一观察结果,我们提出了一种密钥锁定机制(图 5),在该机制中,个性化概念(玩具熊)的密钥固定在超级类别(填充动物甚至普通玩具)的密钥上。为了保持模型的轻量级和快速训练,我们将这些组件直接整合到文本到图像的扩散模型中。我们还添加了门控机制,以调节对所学概念的重视程度,并在推理时结合多个概念。我们称之为方法注入 (执行时间声音化差异融合)。
实验性见解
本节提供了一系列探索 Perfusion 属性的示例。
图 7 展示了生成的高质量个性化图像,这些图像将两个新概念组合到一张图像中。左侧的图像用于向模型教授新的个性化概念,即 Teddy™ 和 Teapot™.在实践中,我们不需要特定的描述,我们可以使用更广泛的概念,例如 toy™。在右侧的图像中,这些概念被组合在一起,并且以令人惊讶的方式进行了组合,例如“a teddy*sailing in a Teapot™”。
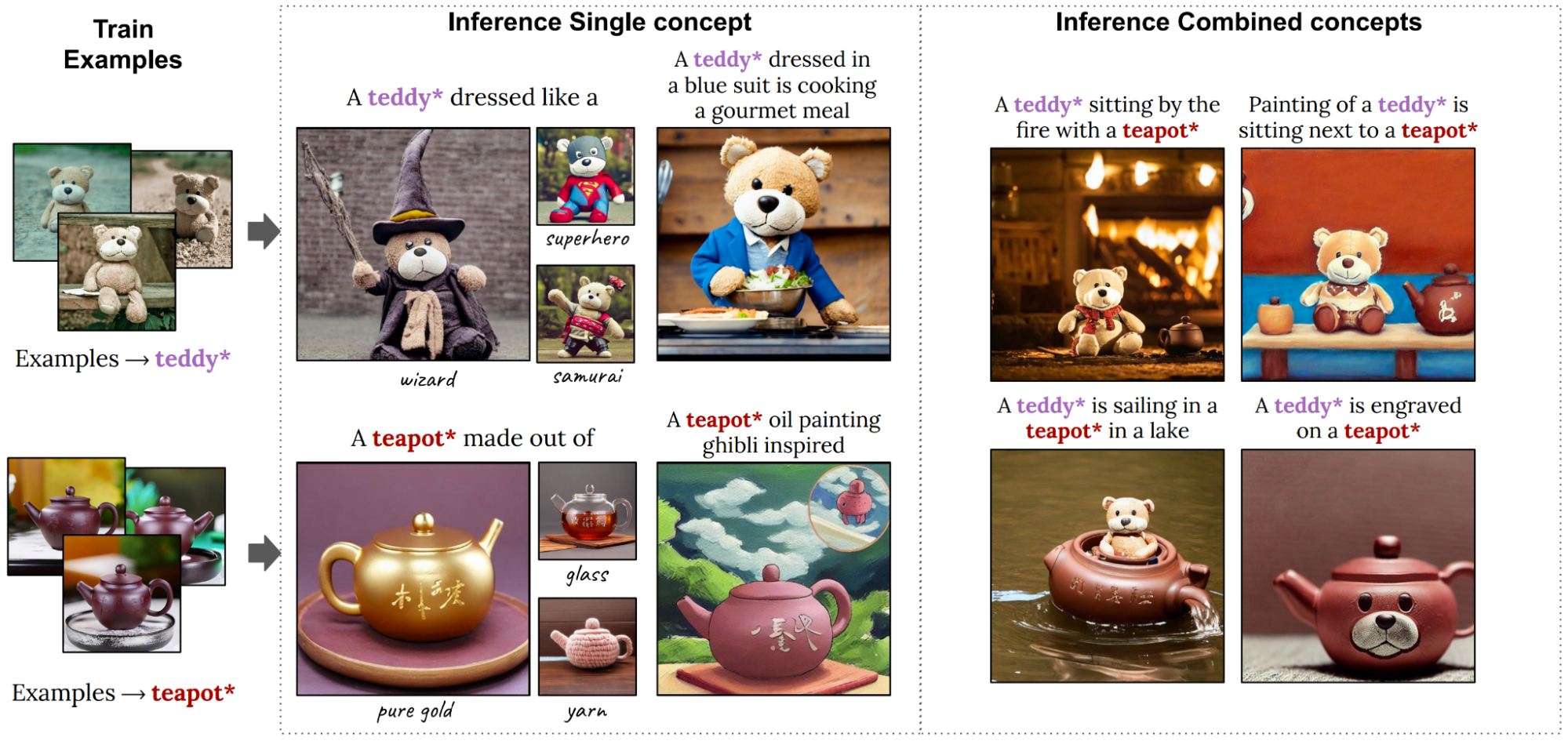
图 8 探讨了在 Perfusion 中使用密钥锁定对生成的图像与文本提示的相似性产生的影响。使用密钥锁定生成的图像(第一行)与未使用密钥锁定的图像(最后一行)相比,与提示的匹配效果要好得多,但与训练图像的姿势和外观的相似性较低。训练密钥类似于 DreamBooth 或 LoRA,但所需的存储空间更少。

图 9 说明了 Perfusion 如何使创作者能够在生成过程中使用单个运行时参数控制视觉保真度和文本相似度之间的平衡。左侧是单个训练模型的量化结果,其中调整了单个运行时参数。Perfusion 可以通过在生成时调整该参数而跨度广泛的结果范围(由蓝色线表示),而无需重新训练。右侧的图像说明了此参数对生成图像的影响。
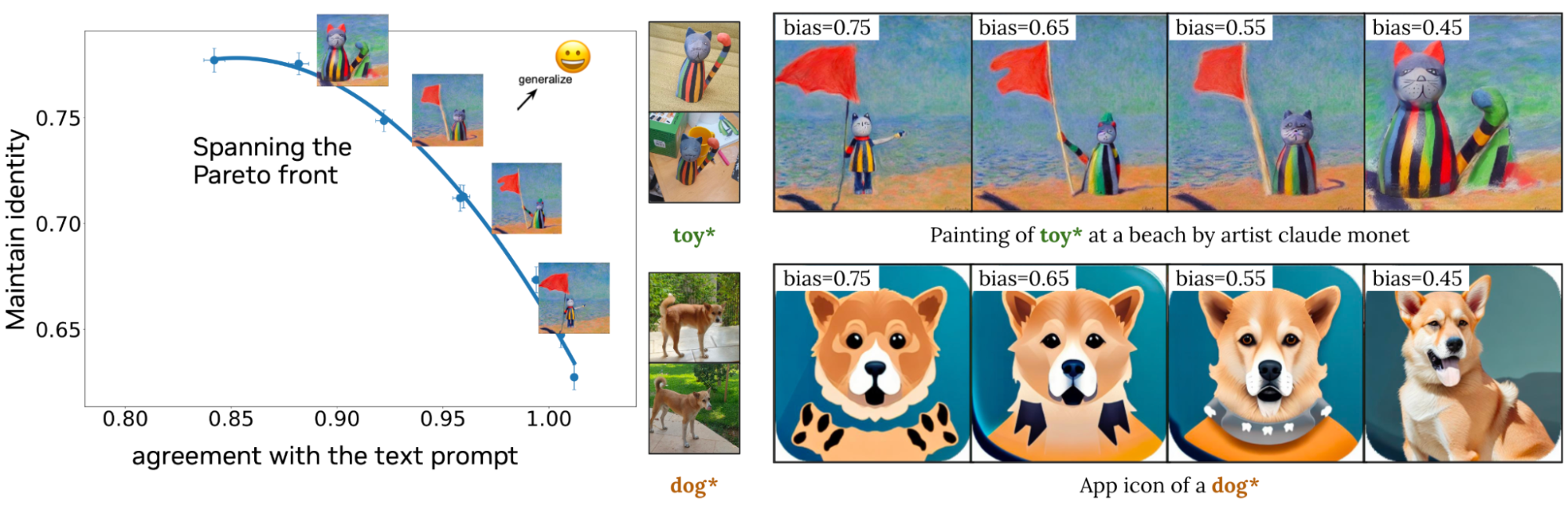
图 10 将 Perfusion 与基准方法进行了比较。Perfusion 可在不受训练图像特征影响的情况下实现出色的提示一致性。

加速个性化
大多数个性化方法(如文本反演和 Perfusion)可能需要几分钟时间来教授模型一个新概念。对于业余爱好者来说,这通常足够快,但有一种更快、更高效的方法可以大规模或动态地实现个性化。
加速新概念训练过程的一种方法是预训练编码器。 编码器是一种经过训练的神经网络,用于预测漫长的个性化训练过程的大致结果。例如,如果您想为模型教授一个表示您的猫的新词,您可以训练一个新模型,该模型将猫的一张(或多张)图像作为输入,并输出一个新词的数字表示。然后,您可以将该表示输入到文本转图像模型中,以生成新的猫照片。
我们提出了一种用于调整的编码器 (E4T) 方法,该方法采用两步式方法。第一步是学习预测描述概念的新词,以及该概念类别的一组权重偏移量。这些偏移量有助于您更轻松地学习个性化该类别中的新对象,例如狗、猫或面孔。这些偏移量保持较小(正则化),以避免过拟合。
在第二步中,我们对完整的模型权重(包括权重偏移)进行了微调,以更好地重建概念的单个图像。虽然这仍然需要一些调整,但我们的第一步是确保我们从非常接近概念的角度开始。因此,训练新概念只需五个训练步骤,只需几秒钟而不是几分钟。
结束语
个性化生成方面的最新进展现在能够在令人惊喜的新环境中创建特定个性化商品的高质量图像。本文解释了个性化背后的基本思路以及两种改进个性化文本转图像模型的方法。
第一种方法使用密钥锁定来提高与训练图像的视觉外观和文本提示含义的相似性。第二种方法使用编码器以更少的图像将个性化速度提高 100 倍。这两种技术可以结合使用,从而生成快速训练的高质量、轻量级模型。
这些技术仍然存在局限性。学习模型并不总是完全保留概念的特征,使用文本提示而非通用概念可能更难以编辑。未来的工作将继续改进这些局限性。
想要在商业应用程序中使用这些方法?请填写 研究许可申请表。