
关于设计和评估的对话 检索增强生成(RAG) 系统是一个漫长而多方面的讨论。即使我们单独研究检索,开发者也会有选择地使用许多技术,例如查询分解、重写、构建软过滤器等,以提高其 RAG 流程的准确性。虽然技术因系统而异,但嵌入模型通常是 RAG 中每个检索流程的核心。
嵌入,尤其是密集嵌入,用于表达文本的语义结构。由于 RAG 中的所有检索器都有一个关键的必须求解,以理解原始文本的语义,因此拥有系统的评估过程来选择正确的过程至关重要。
我们展示了如何使用流行的库,如scikit-learn和XGBoost,将联邦线性模型、k-means 聚类、非线性 SVM、随机森林和 XGBoost 应用于协作学习。
在本文中,您将学习:
- 一些最热门的学术基准需要什么,以及如何最好地利用这些基准作为代理。
- 用于评估检索器的推荐指标。
如果您不熟悉检索器在 RAG 中的作用,请查看 这篇博文介绍了如何使用 NVIDIA Retrieval QA Embedding 模型构建企业 RAG 应用程序。
数据混合对基准测试的影响
用于评估检索的最佳数据是您自己的。理想情况下,您构建一个清晰且带有标记的评估数据集,以更好地反映您在生产中看到的内容。最好构建一个自定义基准来评估不同检索器的质量,这些质量可能因领域和任务的不同而有很大差异。
如果没有经过良好标记的评估数据,许多基准测试会转而采用两个热门基准测试:MTEB 和BEIR 作为代理。但是,一个关键问题是:这些基准测试是否能够准确地评估不同语言模型的性能?如果没有足够的评估数据,这些基准测试的结果可能会有偏差,从而影响我们对不同语言模型性能的判断。因此,为了确保这些基准测试的结果的准确性,我们需要提供足够的评估数据,并且对这些数据的质量进行严格控制。只有这样,我们才能相信这些基准测试的结果能够准确地反映不同语言模型的性能。
“这些基准测试中的数据集是否真正代表您的工作负载?”
回答这个问题至关重要,因为评估不相关案例的性能可能会导致对 RAG 流程产生错误置信度。
热门基准测试是什么?
RAG 系统通常作为聊天机器人的一部分部署。检索者的任务是根据用户的查询找到相关段落,以便为 LLM 提供上下文。自 2021 年推出以来,BeIR 基准测试已成为评估信息检索嵌入的首选标准。
通过整合 BEIR 和各种其他数据集,由 Hugging Face 主持的 MTEB 旨在评估不同任务(例如分类、聚类、检索、排名等)中的嵌入模型。
检索基准测试
贝尔拥有 17 个基准测试数据集,涵盖不同的文本检索任务和领域。而 MTEB 由 58 个数据集组成,涉及 112 种语言,适用于 8 种不同的嵌入任务。每个数据集都能满足用于测量嵌入模型的各种应用(检索、聚类和汇总)的性能。鉴于对 RAG 的关注,您必须考虑哪些性能指标和数据集对于评估与您的用例一致的问答 (QA) 检索解决方案最有用。
多个数据集可以解决基于输入查询查找相关段落的任务:
- HotpotQA 和NaturalQuestions(NQ) 评估一般 QA。
- FiQA 专注于与财务数据相关的 QA。
- NFCorpus 由医学领域的 QA 对组成。
Hotpot QA:常规问题通道
| 输入:Scott Derrickson 和 Ed Wood 是同一个国家的人吗? 目标:Scott Derrickson (1966 年 7 月 16 日出生)是一位美国导演、编剧和制作人。他现居加利福尼亚州洛杉矶。他因导演恐怖电影而闻名,其中包括<邪恶博士>(Doctor Strange)、<邪恶博士>(Deliver Us From Evil) 和<邪恶博士>(Deliver Us From Evil)。 |
NQ:常规问题通道
| 输入:资产负值表上的非控制权益是什么? 目标:在会计学中,少数权益(或非控制权益)是指子公司的股份中不属于母公司的部分。子公司的少数权益通常不到已发行股票的 50%,否则该公司通常将不再是母公司的子公司。[1] |
但是,其他数据集,例如 Quora 和Arguana 专注于 QA 以外的任务。
Quora:查找重复的问题
| 输入:我应该在 Quora 上问哪个问题? 目标:在 Quora 上可以提出哪些好问题? |
Arguana:查找反事实段落
| 输入:杀死动物是不道德的行为随着人类的进化,我们有道德责任尽可能减少动物的生存所带来的痛苦。因此,如果我们不需要为了生存而给动物带来痛苦,我们就不应该这样做。农场动物(例如鸡、仔、牛和奶牛)像我们一样是有情感的生物体 — — 他们是我们的进化兄弟,和我们一样,他们可以感受到愉悦和痛苦。18 世纪的功利主义哲学家 Jeremy Bentham 甚至认为动物的痛苦与人类的痛苦一样严重,并将人类优势的想法比作种族主义。如果我们不需要这样做,就耕种和杀死这些动物作为食物是错误的[…] 目标:人类和动物之间存在巨大的道德差异。与动物不同,人类有能力进行合理思考,并且可以改变周围的世界。其他生物被放置在地球上供人类使用,包括吃肉。出于所有这些原因,我们认为男人和女人都有权利,而动物没有权利。 |
这些示例强调了仔细审查基准数据并选择与您的用例紧密匹配的问题的重要性。使用 Beir 基准测试来指导您的决策时,请考虑以下内容:
- 构成 BEIR 的所有数据集是否都与您的 RAG 应用相关?
- 来自不同基准测试的样本分布是否准确地代表了用户通常会问的问题?
我们的一般建议是评估相关子集(例如 HotpotQA、NQ 和 FiQA)上的检索器,因为它们代表通用 QA 应用程序。但是,如果您的 RAG 工作流有独特的注意事项,我们建议将先前来源的代表性数据添加到您的评估混合中。
如何为 QA 基准选择最佳模型
让我们深入探讨如何选择或整理与您的评估最匹配的基准测试。
领域和质量
在检查不同的 BEIR 数据集时,您可能会注意到一些数据集是特定于领域的。如果您想构建 RAG 系统以执行技术手册说明,您可能会考虑来自同一领域的数据集以及最能体现您用例的类似问题。此类数据集的示例如下:TechQA 领域自适应数据集,其中包含用户在技术论坛上提出的实际问题。TechQA 不在 BEIR 基准测试数据集中,但它可能是与您的 IT/技术支持用例具有类似领域的理想候选项。例如:
| 问题贴图:“Citrix 上的 Datacap” 问题文本:“大家好,我们能否在 Citrix 上运行 Datacap 瘦客户端?” 答案:“通过 WAN 访问 Datacap 的远程用户可以使用基于 Taskmaster Web 的“瘦客户端”,或在离线模式下运行的 FastDoc Capture.” 上下文:” WAN LAN 架构部署 TECHNOTE (FAQ) n*nQUESTION n 在广域网 (WAN) 上部署 Datacap 服务器和客户端的最佳实践是什么?ANSWER 通过 WAN 访问 Datacap 的远程用户可以使用基于 Web 的 Taskmaster“瘦客户端”,或在离线模式下运行的 FastDoc Capture.Datacap 厚客户端(DotScan、DotEdit)和实用程序(NENU、Fingerprint Maintenance Tool)需要 LAN 通信速度和低延迟以实现响应速度。将所有 Datacap Taskmaster 任务主服务器、Rulerunner 服务器、Web 服务器、文件服务器和数据库连接到单个高性能 LAN 以获得最佳结果。Taskmaster 服务器、共享文件和数据库之间的网络延迟会导致作业监控器和数据密集型操作的性能下降。一些客户使用 Citrix 或其他远程访问技术成功地在远程站点中运行 Datacap 厚客户端。IBM 尚未通过 Citrix 测试或寻求认证,也不为 Citrix 提供支持。如果您在 Citrix 上部署 Datacap 客户端并遇到问题,IBM 可能会要求您在 Citrix.C 版调查中重现外部问题,作为 Citrix.C.C Consult IBM 的标题为“Implementing Solutions with IBM Imagingbooks and IBM Capture”Redbooks,Redbooks“Reddegrade section 2.5”部分,Reddegrade deploymentation section 2.5 和 IBM Related Information。 |
训练数据:域内数据与域外数据对比
一些 BEIR 基准数据集具有训练数据和测试数据分割的特点。虽然将训练分割成检索者的训练数据集是好的,但这会使比较基于 MTEB 基准的模型性能及其对未发现的企业特定数据的有效性变得复杂。如果包括训练分割,模型会从与测试数据集相同的分布中学习,从而导致测试数据集的性能指标过高。这种差异通常称为域内与域外。
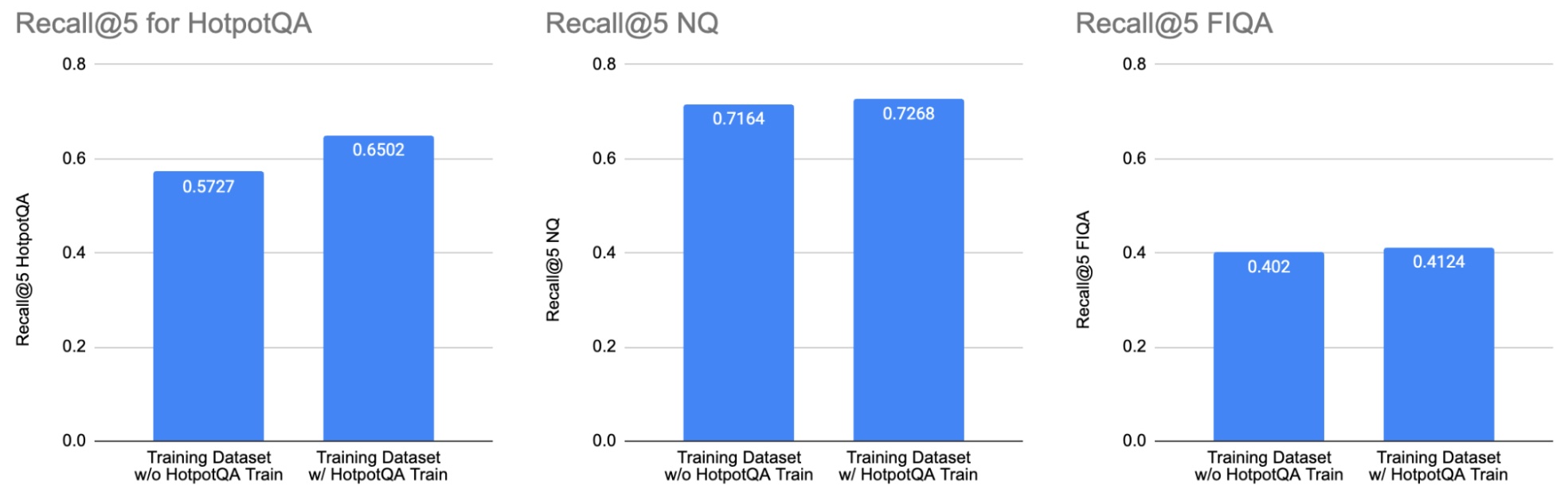
我们通过微调 e5_large_unsupervised 模型两次:一次是训练数据集,其中排除了 HotpotQA 训练分割(左栏),一次是训练数据集,其中包括 HotpotQA 训练分割(右栏)。加入 HotpotQA 训练分割提高了 HotpotQA 测试数据集(左条形图)的性能。但是,它并没有显著改变 NQ (中间条形图)和 FIQA (右条形图)的性能。这说明了在解释公共基准测试结果时,检查用于训练模型的数据集的重要性。
许多模型都混合使用 MSMarco、NQ 和 NLI 进行训练,包括从 BeIR 数据集进行的训练分割。例如,这项研究 使用大型语言模型改进文本嵌入 在附录中提供了训练数据集的详细信息。在论文中,表 1 说明了 synthetic=MSMarco 和 synthetic=Full 配置之间的性能差异。通常情况下,人工生成或标注的数据比纯合成数据集提供更好的质量评估。这种相关性对于数据集的大小也成立。
总而言之,我们的一般建议是寻找与您的用例保持一致且包含大量样本的人工生成和带注释的数据集。
许可证
请注意,以下内容只是解释而非法律建议,建议您咨询您的法律团队以获得任何考虑。
要考虑的另一个重要方面是与预训练模型相关的许可和使用条款。虽然许多预训练模型在 HuggingFace 平台上根据 MIT 或 Apache 2.0 许可证共享,但审查用于预训练的数据集至关重要,因为一些数据集可能具有禁止商业应用程序的许可证。考虑使用预训练模型,该模型使用经许可用于商业用途的训练数据。
鉴于理解数据的重要性,我们涵盖了评估的一个方面。另一个关键方面是我们用于衡量质量的指标。
评估指标
检索评估主要使用两种类型的指标:
- 排名感知指标:这些指标考虑检索到的文档的顺序或排名。在推荐系统或搜索引擎等列表中将最相关的结果放在更高的位置会有所帮助的情况下,这些指标非常有用。示例包括标准化折扣累积增益 (NDCG)。
- 与排名无关的指标:这些指标不考虑显示结果的顺序。当目标是检测列表中是否存在相关项目(而非其排名)时,这些指标很有用。
现在,我们来深入探讨 Recall 和 NDCG,这是学术基准测试和排行榜中常见的两个指标。
召回
与排名无关的度量召回测量检索到的相关结果的百分比:

简而言之,如果给定查询有三个相关数据块,且在检索到的前 5 个数据块中只出现两个数据块,则召回率约为 0.66、
您将在基准测试中看到的一个热门变体是回调%K,该变体仅考虑系统返回的前 K 个商品。但是,如果您的系统始终返回固定的 K 个商品,则回调%K,并且回调实际上是相同的指标。
在大多数信息检索场景中,当检索到的候选项的顺序不重要时,召回是一个很好的指标。从 RAG 的角度来看,如果您的数据块很小(300 – 500 个令牌),并且要检索几个数据块,大多数 LLM 不会遇到迷失在中间的 1500 – 2500 令牌上下文问题。
在为 LLM 提供相当长的上下文的情况下,其提取相关信息的能力会因信息的位置而异。通常,LLM 在处理顶部和底部的信息时效果最佳,如果信息处于“中间”,则会出现严重的性能下降。在较短的上下文中,数据块的顺序无关紧要,只要它们都包含在内。
标准化折扣累积收益
标准化折扣累积收益 (NDCG) 是一种排名感知指标,用于测量检索到的信息的相关性和顺序。
- 累积增益追踪相关性,即根据检索列表中的每个项目在回答查询时的有用性为其分配相关性分数。
- 根据职位适用折扣,较低的职位可获得较高的折扣,从而提高排名。
- 当使用不同数量的相关数据块*时,标准化会统一查询中的指标。
在 RAG 工作流中检索的主要目标是使 LLM 能够执行提取问答。在检索到的数据块过长(超过 4K 令牌),或检索大量数据块时,NDCG 变得相关,从而导致在长上下文中可能在中间丢失的场景。此外,如果您的应用程序将数据块作为引用公开,您可能会发现检索到的数据块的顺序和相关性很重要。
在许多现实世界的应用中,包含高达 4K 令牌的上下文已经足够,并且召回是推荐的指标,因为当最相关的块未排名在顶部时,NDCG 会惩罚。只要它位于顶部的 K 检索结果中,并且可以在合理大小的上下文中共享,LLM 就应该有效地利用这些信息来制定响应。
虽然召回和 NDCG 是非常不同的方法,但它们通常表现出很高的相关性。在数据上具有良好回忆分数的检索模型也可能具有良好的 NDCG 分数。
现在,我们来探索与基于文本的 QA 相关的检索基准测试,并与目前的建议保持一致。
检索基准测试
NVIDIA NeMo Retriever 是 NVIDIA NeMo 框架 提供信息检索服务,旨在安全轻松地简化企业级 RAG 与定制生产级 AI 应用程序的集成。其核心是 NVIDIA Retrieval QA Embedding 模型,该模型基于商业上可行的内部精选数据集进行训练。
在图 2 中,我们展示了 MTEB/BEIR 相关子集(包括 NaturalQuestions、HotpotQA 和 FiQA)的 5 个回顾分数。这些子集可用作 QA 任务的代表性 RAG 工作负载。
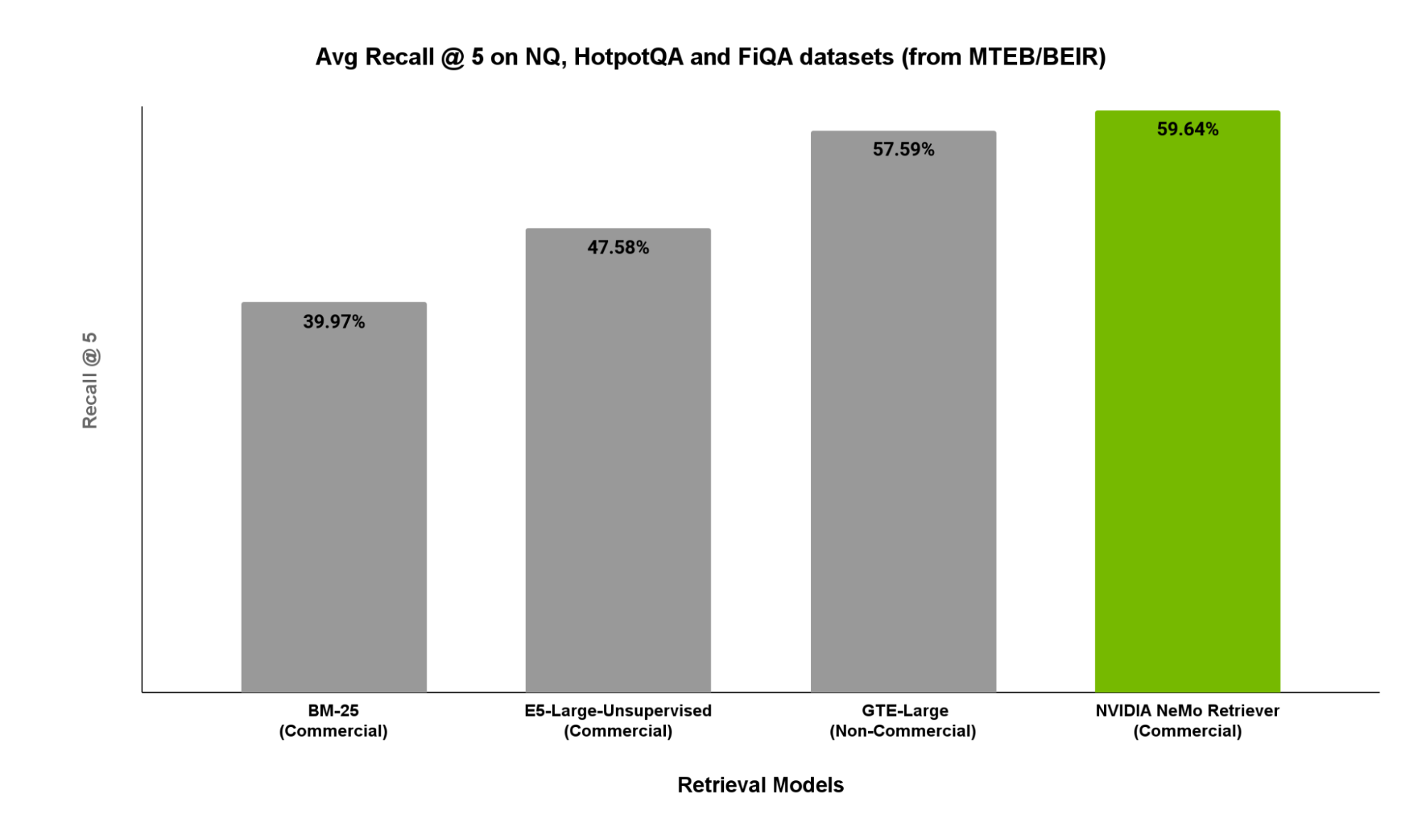
如图 2 所示, NVIDIA 检索 QA 嵌入的性能优于其他开源选项。
结束语
在没有评估数据的情况下,务必要确定学术基准套件中的哪些部分可以接近您的用例,而不是对潜在无关的子集求取平均值。此外,请注意不要仅依赖学术基准,因为其中某些部分可能已被用于训练相应的检索器,从而可能导致对其数据性能的错误置信度。
准备好优化您的人工智能了吗?想要了解更多信息,请访问 NVIDIA/ProViz-AI-Samples GitHub 并亲自尝试。如果您有任何疑问,请访问 数据处理开发者论坛。
此外,回想一下,K 和 NDCG 是两个最相关的指标,您可以选择两者的组合。如果仅选择一个,则回想更易于解释,并且适用更广泛。
注册参加 NVIDIA GTC,详细了解 使用检索增强型生成技术构建生成式 AI 应用 并探索我们的 DLI 课程,如何使用 RAG 构建 AI 聊天机器人。



