
随着 大型语言模型(LLM) 在企业 AI 应用中获得更多吸引力,定制化模型 理解和集成特定行业术语、领域专业知识和独特的组织要求变得越来越重要。
为满足对自定义 LLM 的日益增长的需求,NVIDIA NeMo 团队宣布 NeMo Customizer 抢先体验计划。这是一种高性能、可扩展的微服务,可简化 LLM 的微调和对齐。
使用 NeMo Customizer 调整生成式 AI
企业可以利用 NVIDIA NeMo 来开发自定制的生成式 AI 平台,包括训练、微调、检索增强生成 (RAG)、guardrailing 和数据管护等功能。NeMo 提供从框架到更高级别的 API 端点,以简化开发过程。它提供了预训练模型和技术堆栈,以帮助企业快速开发和部署具有特定功能的生成式 AI 模型。
NeMo Customizer 微服务是一组基于 NeMo 框架的 API 端点,旨在为企业提供快速、经济高效地微调 Large Language Model (LLM) 的最简单方法,以促进生成式 AI 的采用。
抢先体验中提供的自定义技术
该微服务最初支持两种流行的参数高效微调技术:低级适应 (LoRA) 和 P-tuning。
LoRA
借助 LoRA 技术,原始模型参数会被冻结,并注入可训练的秩分解矩阵。这将可训练参数的数量减少 10K 倍,GPU 需求减少 3 倍。可以针对不同的任务训练多个小型 LoRA 模块,从而无需创建多个微调模型。NeMo 还提供了在用户认为必要时将可训练矩阵与原始权重合并的选项。
P 调优
借助 P-tuning,企业应用程序开发者可以向 LLM 添加新的任务功能,而不会覆盖或中断 LLM 已学习的先前任务。
针对这种定制技术,LLM 参数会被冻结,长短期记忆 (LSTM) 或多层感知器 (MLP) 模型称为 *提示编码器* 用于预测虚拟令牌嵌入。这些虚拟令牌并不代表 LLM 的任何词汇表,纯粹是为了调整目的而学习的。
完全对齐技术
除了这些参数高效的微调技术之外,NeMo Customizer 微服务还将在未来添加对完全对齐技术的支持,包括:
- 监督式微调 (SFT)
- 从人类反馈中进行强化学习 (RLHF)
- 直接偏好优化 (DPO)
- NVIDIA SteerLM:简单且实用的技术,可定制大型语言模型(LLM)的推理过程。
同时,NeMo-Aligner GitHub 库可用于那些希望完整模型比对的人。这也是 NeMo 框架容器 NGC 目录的一部分。
NeMo 定制器的优势
NeMo Customizer 通过利用可快速部署的微服务来简化 LLM 定制,使用并行技术加速训练性能,并扩展到多 GPU 和多节点。此外,您可以随时随地下载和部署这些微服务,确保灵活性和对开发流程的控制,同时保持数据安全性。
加快上市时间
利用熟悉的微服务和 API 架构加速开发周期,并加快产品上市速度。
这些微服务提供了灵活性和互操作性,并且可以作为 API 无缝集成到现有工作流程中,而无需考虑所使用的底层技术。
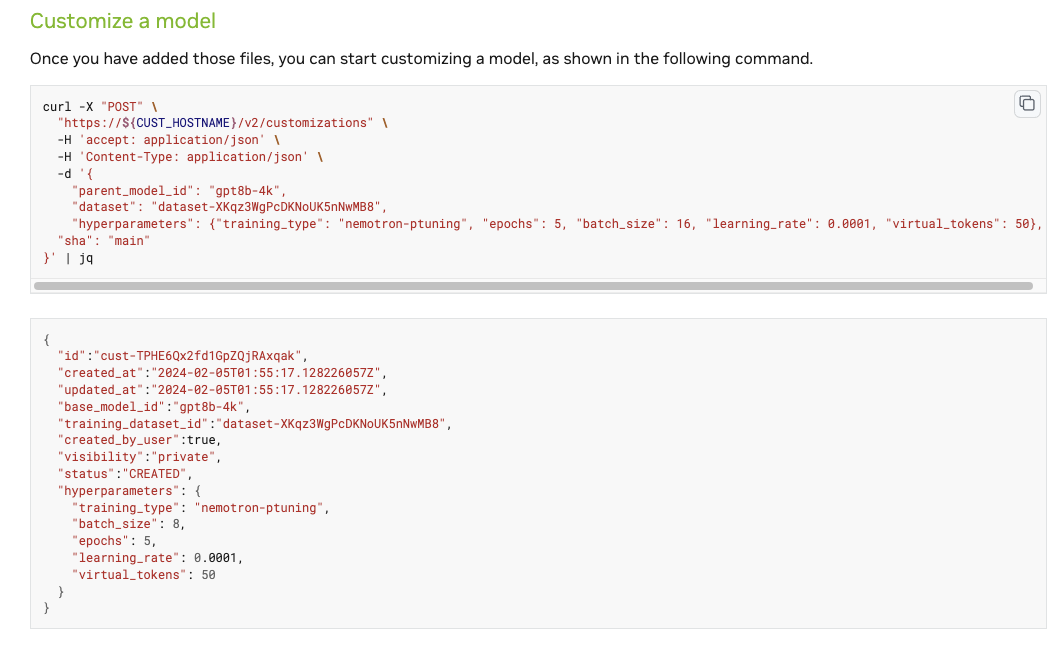
图 1 显示了 cURL 命令示例和来自 NeMo Customizer 微服务的响应。
加速性能和可扩展性
利用多种并行技术可减少这些 LLM 所需的训练时间。由于 LLM 支持多 GPU 和多节点架构,因此可以训练更大的模型。这些方法协同工作以增强训练过程,从而确保优化资源利用并提高训练性能。
随处自定义
您可以下载 NeMo Customizer 微服务,并在您喜欢的基础架构上运行,这意味着您不依赖于任何特定的提供商。这为您提供了更多的自由和对开发设置的控制。
对于处理敏感数据的企业而言,基础设施灵活性是一个巨大的优势,因为他们可以通过将所有内容都保留在本地来保持更严格的控制和安全性。这可以确保敏感信息始终受到保护,免受可能在外部平台上发生的潜在风险或漏洞的影响。
例如,如 “使用机密计算保护敏感数据和 AI 模型” 中所述,银行环境中的客户财务数据必须保密且安全。生成敏感和个人身份信息 (PII) 的活动示例包括信用卡交易、医学影像或其他诊断测试、保险索赔和贷款申请。
此外,NeMo Customizer 微服务支持 Kubernetes 可访问类似 NFS 的文件系统和火山调度程序。这允许批量调度,这是高性能多节点微调 LLM 通常所需的功能。
注册以抢先体验
作为 NVIDIA NeMo 微服务抢先体验的一部分,您可以在请求访问以下微服务:NeMo Curator 和 NeMo Evaluator。这些微服务可以跨任何云或数据中心轻松地进行学术和自定义基准测试,提供对自定义生成式 AI 模型的数据管护和自动评估。这些微服务组合在一起,使企业能够轻松构建企业级自定义生成式 AI,并以更快的速度将解决方案推向市场。
首先,请申请 NeMo Customizer 抢先体验 系统。申请获得批准后,您将收到访问微服务容器的链接。



