Posts by Tanay Varshney
生成式人工智能/大语言模型
2024年 3月 20日
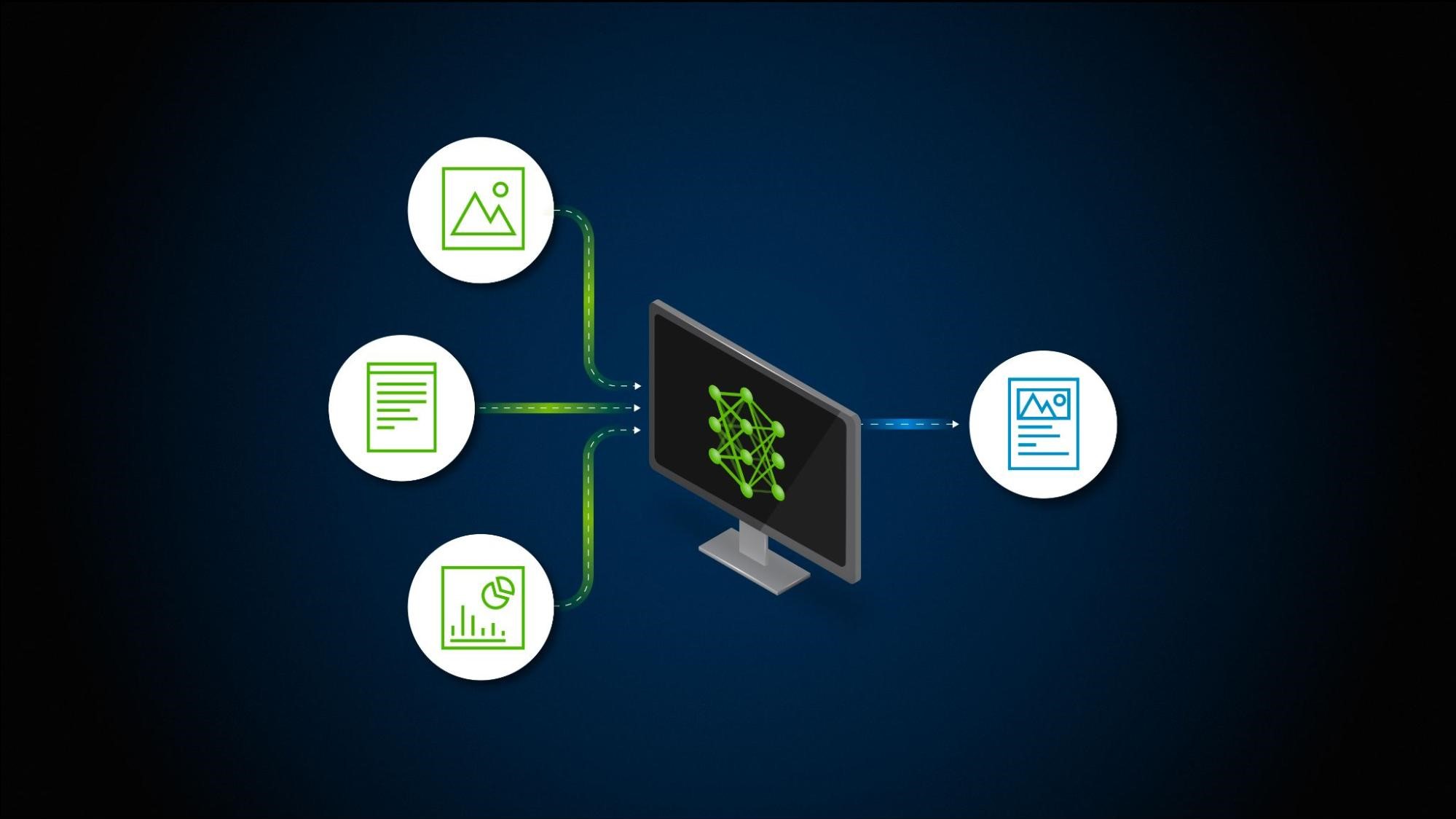
多模态检索增强生成的简单介绍
检索增强生成 (RAG) 应用程序如果能够处理各种数据类型,包括表格、图形和图表,而不仅仅是文本,其效用将会呈指数级增长。
2 MIN READ

生成式人工智能/大语言模型
2024年 3月 18日
借助 NVIDIA NeMo Retriever,将企业数据转换为可行见解
在每个行业和每个工作职能部门,生成式 AI 正在激发组织内部的潜力,它将数据转化为知识,并使员工能够更高效地工作。
2 MIN READ

生成式人工智能/大语言模型
2024年 2月 23日
评估适用于企业级 RAG 的 Retriever
关于设计和评估的对话 检索增强生成(RAG) 系统是一个漫长而多方面的讨论。即使我们单独研究检索,开发者也会有选择地使用许多技术,
3 MIN READ
生成式人工智能/大语言模型
2024年 2月 21日
构建由 LLM 提供支持的 API Agent 来执行任务
长期以来,开发者一直在构建 Web 应用程序等界面,使用户能够利用正在构建的核心产品。要了解如何在您的大型语言模型(LLM)…
3 MIN READ
生成式人工智能/大语言模型
2024年 2月 20日
构建 LLM 支持的数据代理以进行数据分析
AI 智能体是一个由规划功能、内存和工具组成的系统,用于执行用户请求的任务。对于数据分析或与复杂系统交互等复杂任务,
4 MIN READ

生成式人工智能/大语言模型
2023年 11月 30日
构建您的首个 LLM 代理申请
在构建 大型语言模型 (LLM) 智能体应用时,您需要四个关键组件:智能体核心、内存模块、智能体工具和规划模块。无论您是设计问答智能体、
3 MIN READ