
企业数据不断变化。随着时间的推移,这给保持 AI 系统的准确性带来了重大挑战。随着企业组织越来越依赖 代理式 AI 系统 来优化业务流程,保持这些系统与不断变化的业务需求和新数据保持一致变得至关重要。
本文将深入探讨如何使用 NVIDIA NeMo 微服务构建数据飞轮迭代,并简要概述构建端到端流程的步骤。如需了解如何使用 NeMo 微服务解决构建数据飞轮时面临的各种挑战,请参阅使用 NVIDIA NeMo 微服务更大限度地提高 AI Agent 性能。
为什么 data flywheels 对于代理式 AI 至关重要
数据飞轮是一种自我增强的循环。从用户交互中收集的数据可改进 AI 模型,从而提供更好的结果,吸引更多用户生成更多数据,从而在持续改进循环中进一步增强系统。这类似于获取经验和收集反馈以学习和改进工作的过程。
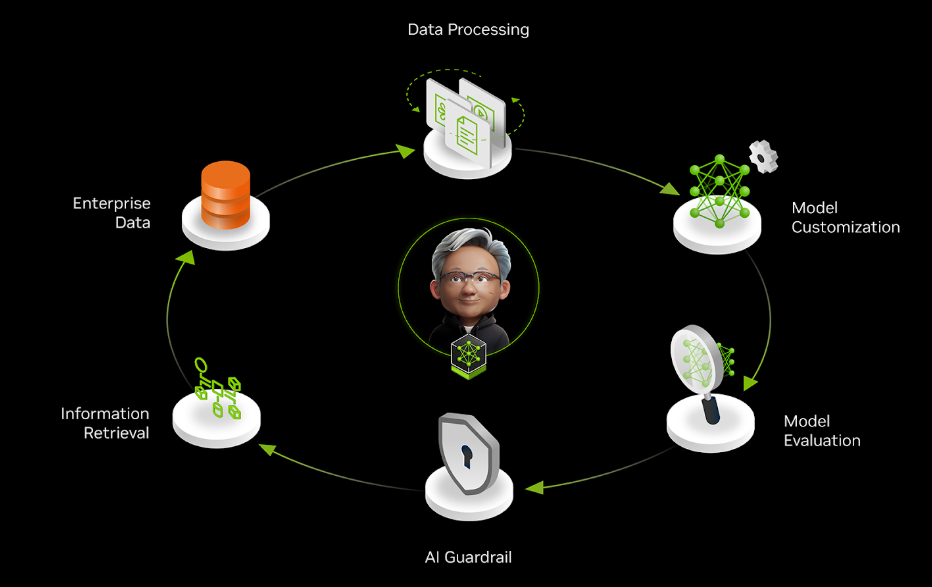
因此,需要部署的应用持续适应并保持高效是将数据 flywheel 整合到代理式系统中的主要动机。
需要持续适应
在生产环境中,AI 应用面临着持久的挑战:model drift。设想一个将用户查询路由到专业专家系统的 AI 智能体 。此系统的输入、所使用的工具及其响应都在不断演变。如果没有适应机制,准确度必然会下降,原因如下:
- 更新企业知识库和文档
- 改变用户行为和查询模式
- 更改工具 API 和响应
例如,当组织添加具有不同模式的新 MongoDB 数据集并更新其响应格式时,通过查询事务 SQL (PostgreSQL) 数据库来回答客户问题的 银行大语言模型 (LLM) 智能体 将面临重大挑战。在不进行重新训练的情况下,智能体继续为旧数据库结构制定查询,从而导致检索失败或信息错误。这会损害客户信任,并可能造成合规性问题。
效率需求
随着这些智能体处理更复杂的任务变得越来越复杂,保持准确性和相关性变得更具挑战性。此外,随着交易量的增加,为这些模型提供服务的计算成本也会大幅增加,因此效率问题至关重要。这对于代理式 AI 系统来说尤其成问题,因为它们通常需要多个推理通道来执行推理、规划和执行步骤,与简单的单通道推理模型相比,计算负担成倍增加。
当智能体必须评估多个潜在动作、查询多个知识来源并验证其输出时,每次交互所需的计算量可能比标准模型推理多 5x 到 10x 倍,随着使用规模的扩大,基础设施成本会大幅增加。
使用定制技术,您可以优化较小的模型,使其与较大模型的准确性相匹配,从而降低延迟和总体拥有成本 (TCO) 。此外,随着更新和功能更强大的模型的出现,不断评估这些模型 (及其微调的变体) ,利用用户交互数据可以确保持续的性能和适应性。
使用 NVIDIA NeMo 微服务为您的数据飞轮提供支持
NVIDIA NeMo 微服务提供了一个用于构建数据飞轮的端到端平台,使企业能够利用最新信息不断优化其 AI 智能体。
如图 2 所示, NVIDIA NeMo 可帮助企业 AI 开发者轻松地大规模整理数据,使用热门的微调技术自定义 LLM,根据行业和自定义基准一致评估模型,并保护它们以获得适当的接地输出。
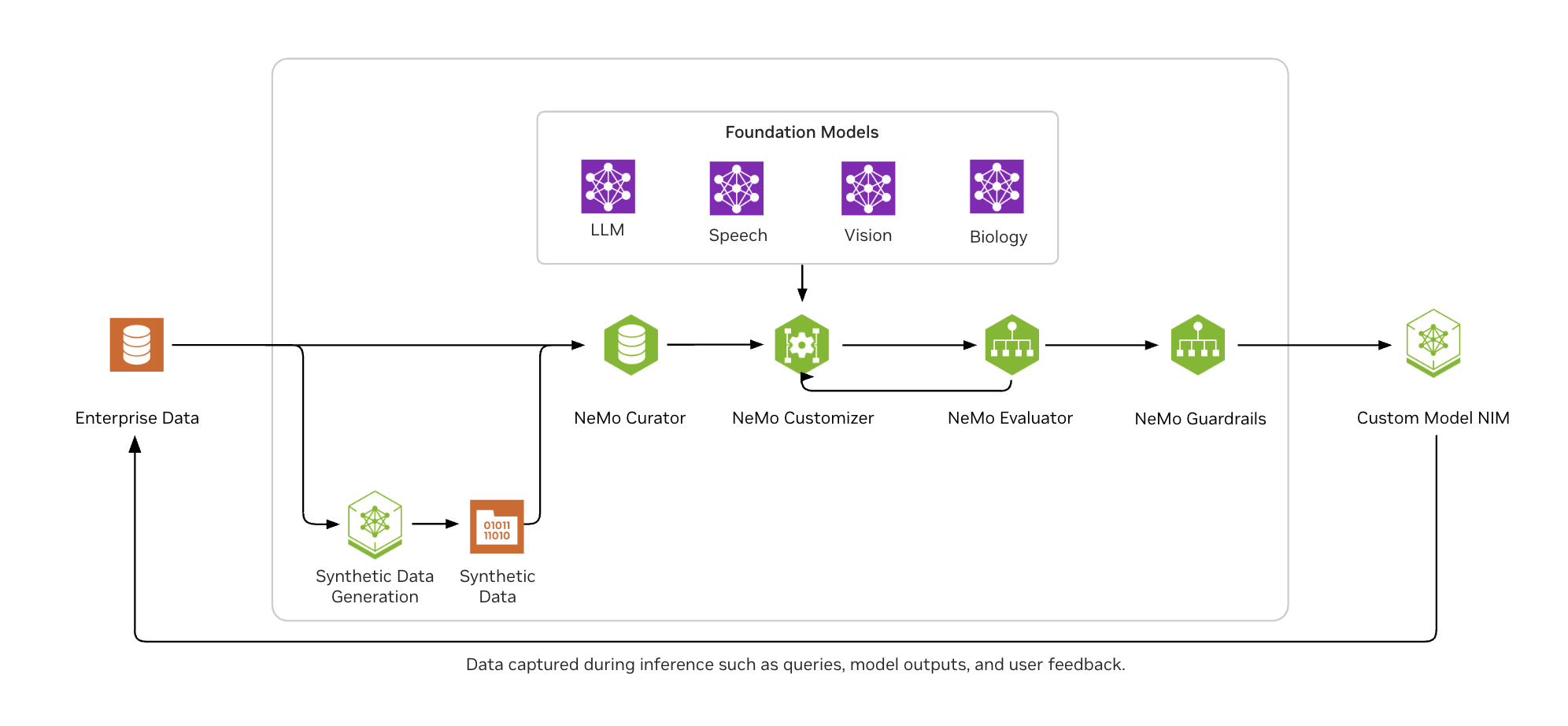
使用 NeMo 微服务增强 Agent 工具调用的示例代码
为了说明 NeMo 微服务的端到端工作流,以智能体中的工具调用为例。工具调用使 LLM 能够与外部系统交互、执行程序,以及访问训练数据中不可用的实时信息。
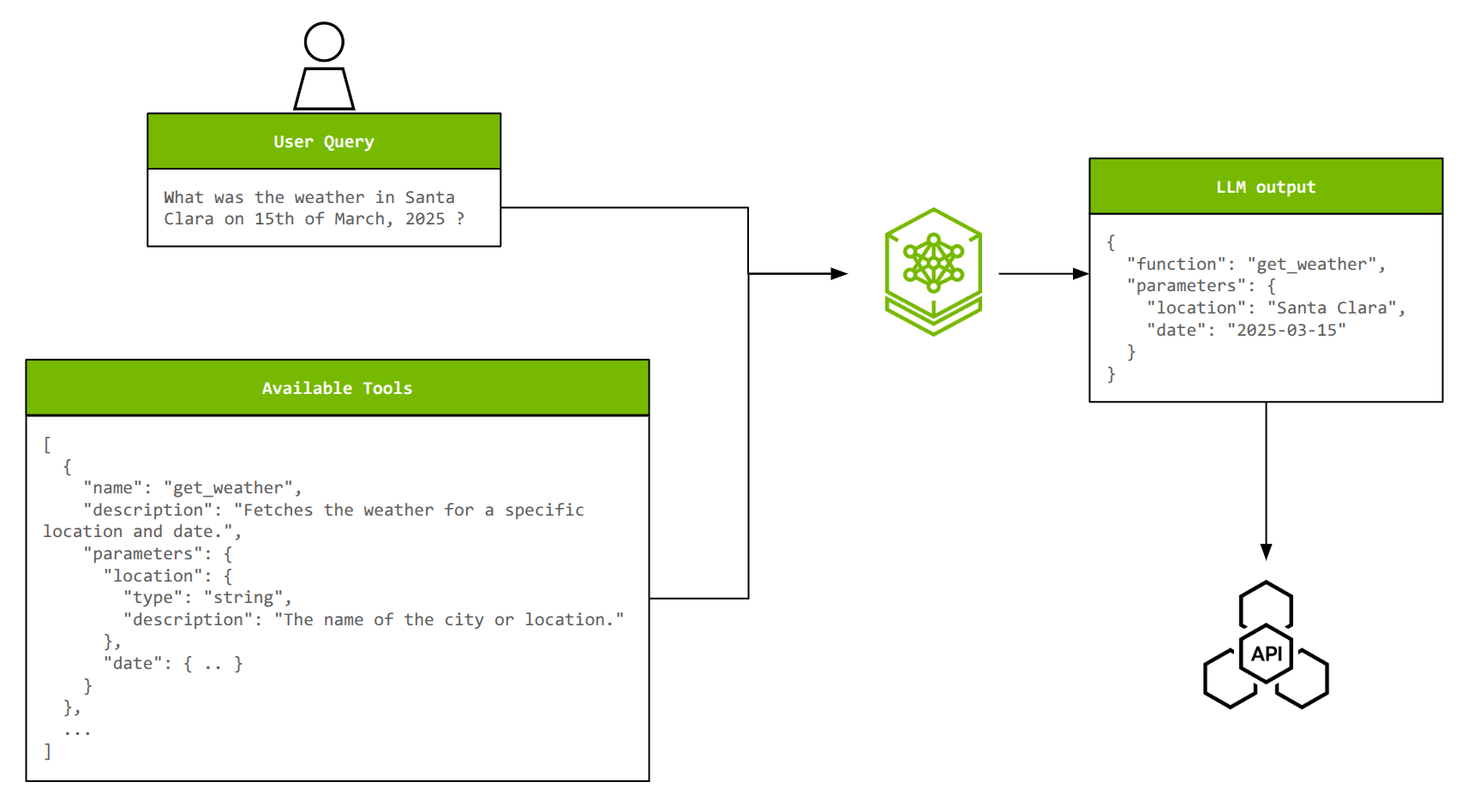
为了有效地调用工具,LLM 必须从可用选项中选择正确的工具,从自然语言查询中提取适当的参数,并且可能会将多个操作关联在一起或并行调用多个工具。随着工具数量及其复杂性的增加,定制对于保持准确性和效率至关重要。
通过在 xLAM 数据集 (~60,000 工具调用示例) 上微调 Llama 3.2 1B Instruct 模型 ,可以实现接近 Llama 3.1 70B Instruct 模型 的工具调用准确性,从而将模型大小减少 70x。
以下各节将概述关键步骤,以便您快速了解相关内容。查看 Jupyter notebooks 中的完整教程。
第 1 步:部署 NVIDIA NeMo 微服务
NeMo 微服务平台以 Helm 图表的形式提供,您可以选择在支持 Kubernetes 的系统上进行部署。 首先 ,您可以在配备至少两个 NVIDIA GPU (NVIDIA A100 80 GB 或 NVIDIA H100 80 GB) 的单节点 NVIDIA GPU 集群上使用 minikube。
第 2 步:数据准备
xLAM 数据集转换为与用于训练的 NeMo Customizer 和用于测试的 NeMo Evaluator 兼容的格式。每个数据样本都是一个 JSON 对象,由用户查询、可用工具列表 (及其描述和参数) 和真值响应 (带参数的选定工具) 组成。此外,还创建了用于训练、验证和测试的数据拆分。
NeMo Customizer 的数据格式如下所示。请注意,messages 包含用户查询和助手的 ground truth 响应,而 tools 包含可供选择的可用工具列表。
{
"messages": [
{
"role": "user",
"content": "Where can I find live giveaways for beta access?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_beta",
"type": "function",
"function": {
"name": "live_giveaways_by_type",
"arguments": {"type": "beta"}
}
},
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "live_giveaways_by_type",
"description": "Retrieve live giveaways from the GamerPower API based on the specified type.",
"parameters": {
"type": "object",
"properties": {
"type": {
"type": "string",
"description": "The type of giveaways to retrieve (e.g., game, loot, beta).",
"default": "game"
}
},
"required": []
}
}
}
]
}
NeMo Evaluator 非常严格地遵循这种格式,但略有不同。有关更多信息,请参阅 Jupyter notebook 。
第 3 步:实体管理
NVIDIA NeMo 实体商店微服务可管理命名空间、项目、数据集和模型等组织实体,为高效资源管理提供分层结构。这样一来,它可以实现无缝协作,并防止多个用户之间的资源冲突。另一方面,NVIDIA NeMo 数据存储微服务处理与这些实体关联的实际文件,支持上传、下载和版本控制等操作。
在此步骤中,准备好的数据集将通过与 Hugging Face Hub 接口 (HfApi) 支持的集成上传到 NeMo Datastore,并通过 REST API 调用注册到 Entity Store 和 Datastore。NeMo Customizer 和 Evaluator 引用这些路径作为其输入。
第 4 步:Low-rank adaptation (LoRA) 微调
NeMo Customizer 用于对 Llama 3.2 1B Instruct 模型进行 LoRA 微调。触发自定义作业和监控作业状态也是对 NeMo Customizer 端点的 REST API 调用。训练参数可以像任何其他深度学习训练作业一样进行配置。此外,NeMo Customizer 与 Weights & Biases 无缝集成,用于监控训练运行。
headers = {"wandb-api-key": WANDB_API_KEY} if WANDB_API_KEY else None
training_params = {
"name": "llama-3.2-1b-xlam-ft",
"output_model": f"{NAMESPACE}/llama-3.1-8b-xlam-run1",
"config": BASE_MODEL,
"dataset": {"name": DATASET_NAME, "namespace" : NAMESPACE},
"hyperparameters": {
"training_type": "sft",
"finetuning_type": "lora",
"epochs": 2,
"batch_size": 16,
"learning_rate": 0.0001,
"lora": {
"adapter_dim": 32,
"adapter_dropout": 0.1
}
}
}
# Trigger the job.
resp = requests.post(f"{NEMO_URL}/v1/customization/jobs", json=training_params, headers=headers)
customization = resp.json()
# Used to track status
JOB_ID = customization["id"]
# This will be the name of the model that will be used to send inference queries to
CUSTOMIZED_MODEL = customization["output_model"]
第 5 步:推理
完成模型训练后,其 LoRA 适配器将保存在 NeMo Entity Store 中,并由 NVIDIA NIM 自动获取。您可以通过向模型的 NIM 端点发送提示来测试模型。
inference_client = OpenAI(
base_url = f"{NIM_URL}/v1",
api_key = "None"
)
completion = inference_client.chat.completions.create(
model = CUSTOMIZED_MODEL,
messages = test_sample["messages"],
tools = test_sample["tools"],
tool_choice = 'auto',
temperature = 0.1,
top_p = 0.7,
max_tokens = 512,
stream = False
)
print(completion.choices[0].message.tool_calls)
这将生成一个输出,其中包含工具名称以及填充其参数:
[ChatCompletionMessageToolCall(id='chatcmpl-tool-bd3e4ee65e0641b7ae2285a9f82c7aae',
function=Function(arguments='{"type": "beta"}', name=’live_giveaways_by_type’), type='function')]
此时,模型已准备好进行评估,以量化其在 tool calling 时的准确性。
第 6 步:评估
使用 NeMo Evaluator 评估经过微调的模型,并将其准确性与基础模型进行比较。function_name_accuracy 和 function_name_and_args_accuracy 等指标突出显示了工具调用能力的改进。顾名思义,这些指标用于计算函数名称及其参数的字符串匹配准确性。
评估通常包括以下几个部分:
1. 创建评估配置:这将告知 NeMo Evaluator 有关所需评估的详细信息,例如要使用的数据集、测试样本数量、指标等。
simple_tool_calling_eval_config = {
"type": "custom",
"tasks": {
"custom-tool-calling": {
"type": "chat-completion",
"dataset": {
"files_url": f"hf://datasets/{NAMESPACE}/{DATASET_NAME}/testing/xlam-test.jsonl",
"limit": 50
},
"params": {
"template": {
"messages": "{{ item.messages | tojson}}",
"tools": "{{ item.tools | tojson }}",
"tool_choice": "auto"
}
},
"metrics": {
"tool-calling-accuracy": {
"type": "tool-calling",
"params": {"tool_calls_ground_truth": "{{ item.tool_calls | tojson }}"}
}
}
}
}
}
2. 触发评估作业: 这包括指定评估配置以及应评估的自定义模型 (NIM) 。
res = requests.post(
f"{NEMO_URL}/v1/evaluation/jobs",
json={
"config": simple_tool_calling_eval_config,
"target": {"type": "model", "model": CUSTOM_MODEL_NAME}
}
)
base_eval_job_id = res.json()["id"]
3. 审查评估指标 :评估作业完成后,审查指标也是 REST 调用。
res = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{base_eval_job_id}/results")
ft_function_name_accuracy_score = res.json()["tasks"]["custom-tool-calling"]["metrics"]["tool-calling-accuracy"]["scores"]["function_name_accuracy"]["value"]
ft_function_name_and_args_accuracy = res.json()["tasks"]["custom-tool-calling"]["metrics"]["tool-calling-accuracy"]["scores"]["function_name_and_args_accuracy"]["value"]
如果按照所提供的演示 Notebook 操作,您会发现与基本 meta/llama-3.2-1B-instruct 模型相比,出现了显著的凸起。您可以大致预期:
function_name_accuracy: 12% 至 92%function_name_and_args_accuracy: 8% 至 72%
这非常接近此任务的基础 meta/llama-3.1-70B-instruct 的准确性,一个模型是其大小的 70 倍。
第 7 步:护栏
此工作流的最后一部分是为您的自定义模型 NIM 添加护栏。在本例中,我们使用 nvidia/llama-3_1-nemoguard-8b-content-safety 来加强内容安全性,该方法可调节人类-LLM 交互内容,并将用户提示和 LLM 响应分类为安全或不安全。如果内容不安全,模型还会返回一个响应,其中包含内容违反的类别列表。
与评估类似,这包括以下内容:
1. 创建和注册 guardrails 配置: 请注意,系统会告知模型要检测的不安全类别,以及模型应采用的响应格式。
data = {
"name": "toolcalling",
"namespace": "default",
"data": {
"models": [
{
"type": "content_safety",
"engine": "nim",
"model": "nvidia/llama-3.1-nemoguard-8b-content-safety"
}
],
"rails": {
"input": {
"flows": [
"content safety check input $model=content_safety"
]
},
"dialog": {
"single_call": {
"enabled": False
}
}
},
"prompts": [
{
"task": "content_safety_check_input $model=content_safety",
"messages": [
{
"type": "system",
"content": "Task: Check if there is unsafe content in the user or agent messages in the below conversation in accordance with our
safety policy with the below categories. Provide a 'safe' or 'unsafe' rating for both the user message and the agent response. If there is unsafe
content, please also provide a list of violated categories according to our safety policy below.\n\n<BEGIN UNSAFE CONTENT
CATEGORIES>\nS1: Violence.\nS2: Sexual.\nS3: Criminal Planning/Confessions.\nS4: Guns and Illegal Weapons.\nS5: Controlled/Regulated
Substances.\nS6: Suicide and Self Harm.\nS7: Sexual (minor).\nS8: Hate/Identity Hate.\nS9: PII/Privacy.\nS10: Harassment.\nS11: Threat.\nS12:
Profanity.\nS13: Needs Caution.\nS14: Other.\nS15: Manipulation.\nS16: Fraud/Deception.\nS17: Malware.\nS18: High Risk Gov Decision
Making.\nS19: Political/Misinformation/Conspiracy.\nS20: Copyright/Trademark/Plagiarism.\nS21: Unauthorized Advice.\nS22: Illegal
Activity.\nS23: Immoral/Unethical.\nS24: Deleting Logs.\n<END UNSAFE CONTENT CATEGORIES>\n\n<BEGIN CONVERSATION>\nuser:
{{user_query}}\n<END CONVERSATION>\n\nProvide your safety assessment for the above conversation in the below output JSON
format:\n{\"User Safety\": safe or unsafe rating for the user message, \"Response Safety\": safe or unsafe rating for the agent response.
Omit if no agent response present. \"Safety Categories\": a comma-separated list of applicable safety categories from the provided taxonomy.
Omit if all safe.}\n\nDo not include anything other than the output JSON in your response.\nOutput JSON:"
},
{
"type": "user",
"content": "{{ user_input }}"
}
],
"output_parser": "nemoguard_parse_prompt_safety",
"max_tokens": 50
}
]
},
}
# Register the guardrails configuration
response = requests.post(GUARDRAILS_URL, json=data)
2. 在 LLM NIM 推理调用之前为用户输入添加 guardrails
payload = {
"model": BASE_MODEL,
"messages": [
{
"role": "user",
"content": user_message
}
],
"guardrails": {
"config_id": "toolcalling"
},
"temperature": 0.2,
"top_p": 1
}
# Check for unsafe user message in guardrails
response = requests.post(f"{NEMO_URL}/v1/guardrail/checks", json=payload)
status = response.json()
if status == “success”:
# SAFE
… (Proceed with your LLM inference call as in step 5)
else:
# UNSAFE
print(f"Not a safe input, the guardrails have resulted in status as {status}. Tool-calling shall not happen")
开始使用
按照本文中概述的步骤,您可以使用 NeMo 微服务为模型自定义、推理、评估和护栏构建端到端流程。如果此管道能够自动处理定期触发或在检测到漂移时触发的连续数据流,则需要建立数据飞轮。这种自增强循环使您的系统能够不断学习、适应和改进,从而不断推动性能的持续提升。
NVIDIA NeMo 微服务现已正式开放下载。 下载微服务并使用 教程 notebook 和 相关视频 ,开始使用本文中展示的示例。
如需详细了解 NeMo 微服务,请 参阅文档 。要在生产环境中运行 NeMo 微服务,请申请 NVIDIA AI Enterprise 的 90 天免费许可证 。






