
최근 몇 년 동안 GPT-3, Megatron-Turing, Chinchilla, PaLM-2, Falcon, Llama 2와 같은 대규모 언어 모델(LLM)의 등장으로 자연어 생성에 괄목할 만한 발전이 이루어졌습니다. 그러나 사람과 유사한 텍스트를 생성할 수 있는 능력에도 불구하고 기초 LLM은 사용자 선호도에 맞춘 유용하고 미묘한 응답을 제공하지 못할 수 있습니다.
현재 LLM을 개선하기 위한 접근 방식은 사람의 데모에 대한 감독 미세 조정(SFT)과 사람의 피드백을 통한 강화 학습(RLHF)을 포함합니다. RLHF는 성능을 향상시킬 수 있지만, 훈련의 복잡성 및 사용자 제어 부족 등 몇 가지 한계가 있습니다.
이러한 문제를 극복하기 위해 NVIDIA 연구팀은 사용자가 지정한 속성에 따라 모델 출력을 동적으로 조정할 수 있는 동시에 LLM 커스터마이징을 간소화하는 새로운 4단계 기술인 SteerLM을 개발하여 NVIDIA NeMo의 일부로 출시했습니다. 이 포스팅에서는 SteerLM의 작동 방식, 이 기술이 중요한 이유, SteerLM 모델을 훈련하는 방법에 대해 자세히 살펴봅니다.
언어 모델의 가능성과 잠재적 함정
대규모 텍스트 말뭉치에 대한 사전 학습을 통해 LLM은 광범위한 언어 능력과 세계 지식을 습득합니다. 연구자들은 번역, 질의응답, 텍스트 생성 등 다양한 자연어 처리(NLP) 작업에 LLM을 성공적으로 적용했습니다. 하지만 이러한 모델은 사용자가 제공한 지침을 따르지 못하고 일반적이고 반복적이거나 무의미한 텍스트를 생성하는 경우가 많습니다. 사람의 피드백에 대한 액세스는 LLM을 사용자 정의하는 데 필수적입니다.
기존 접근 방식의 기회
SFT는 모델 기능을 강화하지만 응답이 짧고 기계적입니다. RLHF는 대안(althernative)보다 사람이 선호하는 응답을 선호함으로써 모델을 최적화합니다. 하지만 RLHF는 매우 복잡한 트레이닝 인프라가 필요하기 때문에 광범위한 채택에 걸림돌이 됩니다.
SteerLM 소개
SteerLM은 추론 중에 응답을 제어할 수 있는 감독 미세 조정 방법을 활용합니다. 이 방법은 사전 정렬 기술의 한계를 극복하며, 네 가지 주요 단계로 구성됩니다:
- 사람이 주석을 단 데이터 세트에 대해 속성 예측 모델을 훈련하여 도움, 유머, 창의성 등 다양한 속성에 대한 응답 품질을 평가합니다.
- 1단계의 모델을 사용하여 속성 점수를 예측하여 다양한 데이터 세트에 주석을 달아 모델에 사용할 수 있는 데이터의 다양성을 강화합니다.
- 사용자가 인지하는 품질 및 유용성과 같이 지정된 속성 조합에 따라 조건부 응답을 생성하도록 LLM을 훈련하여 속성 조건부 SFT를 수행합니다.
- 최대 품질에 따라 다양한 응답을 생성하여 모델 샘플링을 통한 부트스트랩 학습을 수행한 다음(그림 1, 4a), 이를 미세 조정하여 정렬을 더욱 개선합니다(그림 1, 4b).
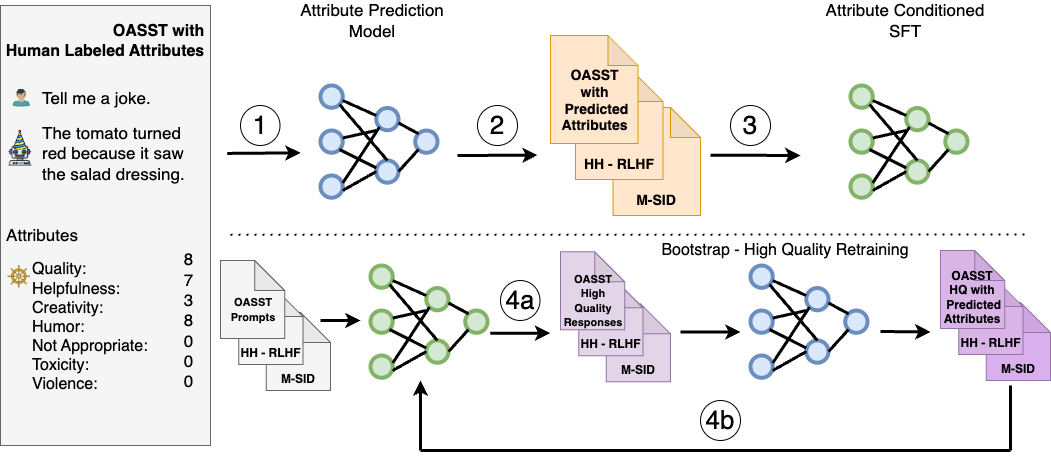
표준 언어 모델링 목표에만 의존하는 SteerLM은 RLHF에 비해 얼라인먼트를 간소화합니다. 추론 시점에 속성을 조정할 수 있도록 하여 사용자가 조정 가능한 AI를 지원합니다. 따라서 미리 정해진 기본 설정을 사용해야 하는 다른 기술과 달리 개발자가 애플리케이션과 관련된 기본 설정을 정의할 수 있습니다.
사용자 조정을 통한 맞춤형 AI 구현
사용자가 모델을 쿼리할 때 추론할 때 원하는 속성(예: 유머 수준 및 독성 허용치)을 지정할 수 있도록 하는 것이 SteerLM의 핵심 혁신입니다. 사용자는 SteerLM으로 하나의 사용자 지정을 실행하는 것에서 추론 시점에 여러 사용 사례를 지원하는 것으로 전환할 수 있습니다.
SteerLM은 다음과 같은 다양한 애플리케이션을 지원합니다:
- 게임: 게임 시나리오의 비플레이어 캐릭터 대화에 변화를 줍니다. 자세한 내용은 NVIDIA ACE, NeMo SteerLM으로 AI 기반 NPC에 감정을 더하다를 참조하세요.
- 교육: 학생 질문에 대해 공식적이고 유용한 페르소나를 유지합니다.
- 엔터프라이즈: 개인화된 기능으로 조직 내 여러 팀에 서비스를 제공하세요.
- 접근성: 민감한 속성을 제어하여 원치 않는 모델 편향성을 억제합니다.
이러한 유연성을 통해 개인의 필요에 맞춘 새로운 맞춤형 AI 시스템을 구현할 수 있습니다.
간소화된 훈련을 통한 최첨단 커스터마이징의 대중화
다른 고급 커스터마이징 기법에 필요한 전문화된 인프라와 비교했을 때, SteerLM의 간단한 교육 체계는 개발자가 최첨단 커스터마이징 기능에 더 쉽게 접근할 수 있도록 해줍니다. 이 성능은 강력한 명령어 조정을 위해 강화 학습과 같은 기술이 필요하지 않다는 것을 분명히 보여줍니다.
SFT와 같은 표준 기술을 활용하면 복잡성을 간소화하여 인프라와 코드 변경을 최소화할 수 있습니다. 제한된 하이퍼파라미터 최적화를 통해 합리적인 결과를 얻을 수 있습니다.
전반적으로, 이는 매우 정확한 맞춤형 LLM을 얻기 위한 간단하고 실용적인 접근 방식으로 이어집니다. 실험 결과, SteerLM 43B는 Vicuna 벤치마크에서 LLaMA 30B RLHF와 같은 기존 RLHF 모델을 능가하는 최첨단 성능을 달성했습니다. 특히, Vicuna 자동 평가에서 평균 655.75점을 획득한 반면, Guanaco 65B는 646.25점, LLaMA 30B RLHF는 612.75점을 기록했습니다.
이러한 결과는 SteerLM의 간단한 트레이닝 프로세스를 통해 더 복잡한 RLHF 기법과 동등한 정확도의 맞춤형 LLM을 생성할 수 있다는 것을 강조합니다. 단순화된 트레이닝을 통해 높은 수준의 정확도를 달성하는 것이 더욱 쉬워져 개발자들이 쉽게 커스터마이징을 대중화할 수 있습니다.
자세한 내용은 당사의 백서인 SteerLM: RLHF의 (사용자 조정 가능한) 대안으로서의 속성 조건부 SFT를 참조하세요. 또한 SteerLM 방법을 사용하여 커스터마이징한 라마 2 13B 모델을 실험하는 방법에 대한 정보도 얻을 수 있습니다.
SteerLM 모델을 훈련하는 방법
이 섹션에서는 2B NeMo LLM 모델을 사용하여 OASST 데이터에서 전체 SteerLM 파이프라인을 실행하는 방법을 단계별로 안내하는 자습서입니다. 여기에는 다음이 포함됩니다:
- 데이터 정리 및 전처리
- 속성 예측 훈련(값 모델)
- 속성 조건부 SFT(SteerLM 모델) 훈련
- 속성 값이 다른 SteerLM 모델에 대한 추론
1단계: 요구 사항 설치
먼저 필요한 Python 라이브러리를 설치합니다:
pip install fire langchain==0.0.1332단계: 데이터 다운로드 및 하위 집합
이 튜토리얼에서는 OASST 데이터 세트의 작은 하위 집합을 사용합니다. OASST에는 13가지 품질 속성에 대한 사람의 주석이 있는 오픈 도메인 대화가 포함되어 있습니다.
먼저 데이터를 다운로드하여 하위 집합으로 만듭니다:
mkdir -p data
cd data
wget https://huggingface.co/datasets/OpenAssistant/oasst1/resolve/main/2023-04-12_oasst_all.trees.jsonl.gz
gunzip -f 2023-04-12_oasst_all.trees.jsonl.gz
mv 2023-04-12_oasst_all.trees.jsonl data.jsonl
head -5000 data.jsonl > subset_data.jsonl
cd -3단계: Llama 2 LLM 모델 및 토큰화 도구 다운로드 및 변환
Llama 2 7B LLM 모델과 토큰라이저를 models 폴더에 다운로드합니다.
그런 다음 Llama 2 LLM을 .nemo 형식으로 변환합니다:
python NeMo/scripts/nlp_language_modeling/convert_hf_llama_to_nemo.py --in-file /path/to/llama --out-file /output_path/llama7b.nemo.nemo 파일을 압축 해제하여 NeMo 형식의 토큰화기를 얻습니다:
tar <path-to-model>/llama7b.nemo mv ba4632640484461f8ae9d61f6dfe0d0b_tokenizer.model tokenizer.model
토큰화기의 접두사는 추출할 때 달라질 수 있습니다. 앞의 명령을 실행할 때 올바른 토큰화기 파일을 사용했는지 확인하세요.
4단계: OASST 데이터 전처리
NeMo 전처리 스크립트를 사용하여 데이터를 전처리합니다. 그런 다음 별도의 텍스트-값 및 값-텍스트 버전을 생성합니다:
python scripts/nlp_language_modeling/sft/preprocessing.py \
--input_file=data/subset_data.jsonl \
--output_file_prefix=data/subset_data_output \
--mask_role=User \
--type=TEXT_TO_VALUE \
--split_ratio=0.95 \
--seed=10
python scripts/nlp_language_modeling/sft/preprocessing.py \
--input_file=data/subset_data.jsonl \
--output_file_prefix=data/subset_data_output_v2t \
--mask_role=User \
--type=VALUE_TO_TEXT \
--split_ratio=0.95 \
--seed=105단계: 텍스트-값 데이터 정리
시퀀스 길이에 따른 잘림으로 인해 모든 토큰이 마스킹된 경우 다음 스크립트를 실행하면 레코드가 제거됩니다.
python scripts/nlp_language_modeling/sft/data_clean.py \
--dataset_file=data/subset_data_output_train.jsonl \
--output_file=data/subset_data_output_train_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
python scripts/nlp_language_modeling/sft/data_clean.py \
--dataset_file=data/subset_data_output_val.jsonl \
--output_file=data/subset_data_output_val_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 40966단계: 정리된 OASST 데이터로 값 모델 훈련하기
이 튜토리얼에서는 1K 단계에 대해 값 모델을 훈련합니다. 좋은 가치 모델을 얻으려면 더 많은 데이터에 대해 훨씬 더 오래 훈련하는 것이 좋습니다.
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py \
++trainer.limit_val_batches=10 \
trainer.num_nodes=1 \
trainer.devices=2 \
trainer.max_epochs=null \
trainer.max_steps=1000 \
trainer.val_check_interval=100 \
trainer.precision=bf16 \
model.megatron_amp_O2=False \
model.restore_from_path=/model/llama7b.nemo \
model.tensor_model_parallel_size=2 \
model.pipeline_model_parallel_size=1 \
model.optim.lr=5e-6 \
model.optim.name=distributed_fused_adam \
model.optim.weight_decay=0.01 \
model.answer_only_loss=True \
model.activations_checkpoint_granularity=selective \
model.activations_checkpoint_method=uniform \
model.data.chat=True \
model.data.train_ds.max_seq_length=4096 \
model.data.train_ds.micro_batch_size=1 \
model.data.train_ds.global_batch_size=1 \
model.data.train_ds.file_names=[data/subset_data_output_train_clean.jsonl] \
model.data.train_ds.concat_sampling_probabilities=[1.0] \
model.data.train_ds.num_workers=0 \
model.data.train_ds.hf_dataset=True \
model.data.train_ds.prompt_template='\{input\}\{output\}' \
model.data.train_ds.add_eos=False \
model.data.validation_ds.max_seq_length=4096 \
model.data.validation_ds.file_names=[data/subset_data_output_val_clean.jsonl] \
model.data.validation_ds.names=["oasst"] \
model.data.validation_ds.micro_batch_size=1 \
model.data.validation_ds.global_batch_size=1 \
model.data.validation_ds.num_workers=0 \
model.data.validation_ds.metric.name=loss \
model.data.validation_ds.index_mapping_dir=/indexmap_dir \
model.data.validation_ds.hf_dataset=True \
model.data.validation_ds.prompt_template='\{input\}\{output\}' \
model.data.validation_ds.add_eos=False \
model.data.test_ds.max_seq_length=4096 \
model.data.test_ds.file_names=[data/subset_data_output_val_clean.jsonl] \
model.data.test_ds.names=["oasst"] \
model.data.test_ds.micro_batch_size=1 \
model.data.test_ds.global_batch_size=1 \
model.data.test_ds.num_workers=0 \
model.data.test_ds.metric.name=loss \
model.data.test_ds.hf_dataset=True \
model.data.test_ds.prompt_template='\{input\}\{output\}' \
model.data.test_ds.add_eos=False \
exp_manager.explicit_log_dir="/home/value_model/" \
exp_manager.create_checkpoint_callback=True \
exp_manager.checkpoint_callback_params.monitor=val_loss \
exp_manager.checkpoint_callback_params.mode=min7단계: 주석 생성
주석을 생성하려면 백그라운드에서 다음 명령을 실행하여 추론 서버를 실행합니다:
python examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/models/<TRAINED_ATTR_PREDICTION_MODEL.nemo> \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=1 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=1 \
trainer.num_nodes=1 \
web_server=False \
port=1424이제 다음을 실행하세요:
python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_train.jsonl --output_file_name=data/subset_data_v2t_train_value_output.jsonl --port_num=1424
python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_val.jsonl --output_file_name=data/subset_data_v2t_val_value_output.jsonl --port_num=14248단계: 값-텍스트 데이터 정리하기
시퀀스 길이에 따라 잘라낸 후 모든 토큰이 마스킹된 경우 레코드를 제거합니다:
python scripts/data_clean.py \ –dataset_file=data/subset_data_v2t_train_value_output.jsonl \ –output_file=data/subset_data_v2t_train_value_output_clean.jsonl \ –library sentencepiece \ –model_file tokenizer.model \ –seq_len 4096 python scripts/data_clean.py \ –dataset_file=data/subset_data_v2t_val_value_output.jsonl \ –output_file=data/subset_data_v2t_val_value_output_clean.jsonl \ –library sentencepiece \ –model_file tokenizer.model \ –seq_len 4096
9단계: SteerLM 모델 훈련하기
이 튜토리얼의 목적에 따라, SteerLM 모델은 1K 단계로 훈련됩니다. 잘 훈련된 모델을 얻으려면 훨씬 더 많은 데이터로 더 오래 훈련하는 것이 좋습니다.
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py \ ++trainer.limit_val_batches=10 \ trainer.num_nodes=1 \ trainer.devices=2 \ trainer.max_epochs=null \ trainer.max_steps=1000 \ trainer.val_check_interval=100 \ trainer.precision=bf16 \ model.megatron_amp_O2=False \ model.restore_from_path=/model/llama7b.nemo \ model.tensor_model_parallel_size=2 \ model.pipeline_model_parallel_size=1 \ model.optim.lr=5e-6 \ model.optim.name=distributed_fused_adam \ model.optim.weight_decay=0.01 \ model.answer_only_loss=True \ model.activations_checkpoint_granularity=selective \ model.activations_checkpoint_method=uniform \ model.data.chat=True \ model.data.train_ds.max_seq_length=4096 \ model.data.train_ds.micro_batch_size=1 \ model.data.train_ds.global_batch_size=1 \ model.data.train_ds.file_names=[data/subset_data_v2t_train_value_output_clean.jsonl] \ model.data.train_ds.concat_sampling_probabilities=[1.0] \ model.data.train_ds.num_workers=0 \ model.data.train_ds.prompt_template='\{input\}\{output\}' \ model.data.train_ds.add_eos=False \ model.data.validation_ds.max_seq_length=4096 \ model.data.validation_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl] \ model.data.validation_ds.names=["oasst"] \ model.data.validation_ds.micro_batch_size=1 \ model.data.validation_ds.global_batch_size=1 \ model.data.validation_ds.num_workers=0 \ model.data.validation_ds.metric.name=loss \ model.data.validation_ds.index_mapping_dir=/indexmap_dir \ model.data.validation_ds.prompt_template='\{input\}\{output\}' \ model.data.validation_ds.add_eos=False \ model.data.test_ds.max_seq_length=4096 \ model.data.test_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl] \ model.data.test_ds.names=["oasst"] \ model.data.test_ds.micro_batch_size=1 \ model.data.test_ds.global_batch_size=1 \ model.data.test_ds.num_workers=0 \ model.data.test_ds.metric.name=loss \ model.data.test_ds.prompt_template='\{input\}\{output\}' \ model.data.test_ds.add_eos=False \ exp_manager.explicit_log_dir="/home/steerlm_model/" \ exp_manager.create_checkpoint_callback=True \ exp_manager.checkpoint_callback_params.monitor=val_loss \ exp_manager.checkpoint_callback_params.mode=min10단계: 추론
추론을 시작하려면 다음 명령을 사용하여 백그라운드에서 추론 서버를 실행합니다:
python examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/models/<TRAINED_STEERLM_MODEL.nemo> \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=1 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=1 \
trainer.num_nodes=1 \
web_server=False \
port=1427다음으로는, Python 헬퍼 기능을 구축합니다.
def get_answer(question, max_tokens, values, eval_port='1427'):
prompt = f"""<extra_id_0>System
A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
<extra_id_1>User
{question}
<extra_id_1>Assistant
<extra_id_2>{values}
"""
prompts = [prompt]
data = {
"sentences": prompts,
"tokens_to_generate": max_tokens,
"top_k": 1,
'greedy': True,
'end_strings': ["<extra_id_1>", "quality:", "quality:4", "quality:0"]
}
url = f"http://localhost:{eval_port}/generate"
response = requests.put(url, json=data)
json_response = response.json()
response_sentence = json_response['sentences'][0][len(prompt):]
return response_sentencedef encode_labels(labels):
items = []
for key in labels:
value = labels[key]
items.append(f'{key}:{value}')
return ','.join(items)
그런 다음 아래 값을 변경하여 언어 모델을 조정합니다:
values = OrderedDict([
('quality', 4),
('toxicity', 0),
('humor', 0),
('creativity', 0),
('violence', 0),
('helpfulness', 4),
('not_appropriate', 0),
('hate_speech', 0),
('sexual_content', 0),
('fails_task', 0),
('political_content', 0),
('moral_judgement', 0),
])
values = encode_labels(values)마지막으로 질문을 하고 답변을 생성합니다:
question = """Where and when did techno music originate?"""
print (get_answer(question, 4096, values))이 튜토리얼에 언급된 스크립트 및 유틸리티를 사용하여 추가 설정 단계를 수행할 수 있습니다. 이 단계는 다양한 벤치마크에서 모델 정확도를 더욱 향상시키는 데 도움이 될 수 있습니다.
SteerLM을 통한 AI의 미래
SteerLM은 인간의 선호도에 맞춰 통제 가능한 방식으로 차세대 AI 시스템을 구현할 수 있는 새로운 기술을 제공합니다. 개념적 단순성, 성능 향상, 커스터마이징 기능은 사용자가 제어할 수 있는 AI의 혁신적 가능성을 강조합니다. SteerLM은 현재 오픈 소스 소프트웨어로 제공되며, NVIDIA/NeMo GitHub 리포지토리를 통해 액세스할 수 있습니다. 또한 SteerLM 방법을 사용하여 커스터마이징한 라마 2 13B 모델을 실험하는 방법에 대한 정보도 얻을 수 있습니다.
완전한 엔터프라이즈 보안 및 지원을 위해 SteerLM은 대규모 생성 AI 모델을 구축, 커스터마이징 및 배포할 수 있는 풍부한 프레임워크인 NVIDIA NeMo에 통합될 예정입니다. SteerLM 방식은 라마 2(Llama 2), 팔콘(Falcon) LLM, MPT 등 커뮤니티에서 구축한 인기 있는 사전 훈련된 LLM을 포함하여 NeMo에서 지원되는 모든 모델에서 작동합니다. 저희의 연구가 사용자를 제약하는 것이 아니라 권한을 부여하는 모델을 개발하기 위한 추가 연구에 자극제가 되기를 바랍니다. AI의 미래는 SteerLM으로 조종할 수 있으니까요.
감사의 말
이 게시물과 SteerLM의 시작에 기여해 주신 Xianchao Wu와 Oleksii Kuchaiev에게 감사의 말씀을 전합니다.
관련 리소스
- GTC 세션: 최신 커스터마이징 기법으로 LLM 길들이기
- GTC 세션: 초대형 변압기 모델의 효율적인 추론
- GTC 세션: AWS에서 PyTorch로 LLM 훈련 및 프로덕션화하기(AWS 제공)
- SDK: NeMo LLM 서비스
- SDK: NeMo
- 웨비나: TensorRT 및 TRITON 자세히 알아보기