
이 게시물은 가속화된 데이터 분석에 관한 시리즈의 일부입니다:
- 가속화된 데이터 분석: 가속화된 데이터 분석: RAPIDS cuDF를 사용한 더 빠른 시계열 분석에서는 RAPIDS cuDF를 사용한 시계열 데이터 처리의 일반적인 단계를 안내합니다.
- 이 게시물에서는 pandas 라이브러리가 Python에서 효율적이고 표현력이 풍부한 함수를 제공하는 방법에 대해 설명합니다.
기후 모델링, 의료, 금융, 소매업의 디지털 발전으로 전례 없는 양과 유형의 데이터가 생성되고 있습니다. IDC에 따르면 2025년에는 2020년의 64ZB에 비해 180ZB의 데이터가 생성될 것이며, 이 모든 데이터를 인사이트로 전환하기 위한 데이터 분석의 필요성이 확대될 것입니다.
- 하루에 두 번씩 수신되는 위성 이미지는 대기질, 홍수, 태양 플레어 모델링에 정보를 제공하여 자연 위험을 식별하는 데 도움을 주고 있습니다.
- 고급 유전체학 및 유전자 염기서열 분석은 암 치료법에 더 가까워질 수 있는 인사이트로 인코딩된 유전자 데이터 풀을 제공합니다.
- 디지털 구매 및 네트워킹 시스템은 테라바이트 규모의 시장 및 행동 데이터를 생성하고 있습니다.
NVIDIA는 데이터 사이언티스트가 엔드투엔드 데이터 사이언스 및 분석 파이프라인을 전적으로 GPU에서 실행할 수 있도록 오픈 소스 소프트웨어 라이브러리 및 API의 RAPIDS 제품군을 제공합니다. 여기에는 분석 및 데이터 사이언스를 위한 일반적인 데이터 준비 작업과 DataFrame API가 포함됩니다: RAPIDS cuDF.
일반적인 데이터 분석 워크플로우에서 최대 40배까지 속도가 빨라지는 가속화된 데이터 분석은 시간을 절약하고 현재 분석 도구로 인해 제약이 있을 수 있는 반복 작업의 기회를 추가합니다.
가속 데이터 분석의 가치를 설명하기 위해, 이 게시물에서는 RAPIDS cuDF를 사용한 간단한 탐색 데이터 분석(EDA) 자습서를 살펴보겠습니다.
현재 Spark 3.0을 사용해 대규모 데이터 세트를 처리하고 계신다면, Spark용 RAPIDS 가속기를 참조하세요. 지금 RAPIDS를 시작할 준비가 되셨다면, RAPIDS로 머신 러닝 애플리케이션을 구축하기 위한 단계별 가이드를 참조하세요.
왜 EDA용 RAPIDS cuDF인가?
오늘날 대부분의 데이터 사이언티스트는 EDA 작업을 위한 데이터 조작 및 분석을 위해 Python을 기반으로 구축된 인기 있는 오픈 소스 소프트웨어 라이브러리인 pandas를 사용합니다. 유연하고 표현력이 풍부한 데이터 구조는 관계형 데이터나 레이블이 지정된 데이터로 쉽고 직관적으로 작업할 수 있도록 설계되었으며, 특히 EDA와 같은 개방형 워크플로우에 적합합니다.
그러나 pandas는 단일 코어에서 실행되도록 설계되어 데이터 크기가 1~2GB에 도달하면 속도가 느려지기 시작하여 적용 가능성에 제한이 있습니다. 데이터 크기가 10~20GB 범위를 초과하는 경우, Dask나 Apache Spark와 같은 분산 컴퓨팅 도구를 고려해야 합니다. 단점은 코드를 다시 작성해야 하므로 도입에 장벽이 될 수 있다는 점입니다.
2~10GB의 중간 지점에는 RAPIDS cuDF가 적합한 Goldilocks 솔루션입니다.
RAPIDS cuDF는 GPU의 여러 코어로 컴퓨팅을 병렬화하며, 팬더와 유사한 API로 추상화되어 있습니다. pandas에서 가장 인기 있고 표준적인 많은 연산을 모방한 cuDF 함수를 통해 cuDF는 pandas처럼 실행되지만 더 빠릅니다. RAPIDS는 현재 pandas 워크로드를 위한 터보 부스트 버튼이라고 생각하면 됩니다.
RAPIDS cuDF를 사용한 EDA
이 포스팅에서는 EDA 접근 방식을 취할 때 cuDF를 얼마나 쉽게 채택할 수 있는지 보여줍니다.
이 게시물에서 다루는 연산을 통해 pandas를 사용할 때와 비교하여 cuDF를 사용할 때 작업 속도가 15배 빨라지는 것을 관찰했습니다. 이 약간의 이득은 여러 프로젝트에서 작업할 때 시간을 절약하는 데 도움이 될 수 있습니다.
시계열 분석 수행에 대한 자세한 내용은 RAPIDS GitHub 리포지토리에 있는 전체 노트북, cuDF를 사용한 탐색적 데이터 분석을 참조하세요. 전체 워크플로우를 사용하면 관찰된 속도가 15배로 증가합니다.
데이터 세트
Meteonet은 2016년부터 2018년까지 파리 전역에 위치한 기상 관측소의 측정값을 집계한 기상 데이터 세트입니다. 누락되거나 유효하지 않은 데이터가 없는 사실적인 데이터 세트입니다.
분석 접근 방식
이 게시물에서는 데이터 사이언티스트가 이 집계 데이터를 읽고 그 품질을 평가한다고 가정해 보겠습니다. 이 사용 사례는 보고서, 일기 예보 또는 토목 공학 사용 사례에 대한 정보를 제공하는 데 사용할 수 있는 개방형입니다.
다음 단계에 따라 데이터를 컨텍스트화하도록 분석을 구조화하세요:
- 변수 이해하기.
- 데이터 집합의 격차 파악.
- 변수 간의 관계 분석.
1단계. 변수 이해하기
먼저 cuDF 라이브러리를 가져와서 데이터 집합을 읽어들입니다. 북서부 관측소의 2016년, 2017년, 2018년 데이터가 포함된 NW.csv를 다운로드하여 만들려면 cuDF를 사용한 탐색적 데이터 분석 노트북을 참조하세요.
# Import cuDF and CuPy
import cudf
import cupy as cp
# Read in the data files into DataFrame placeholders
gdf_2016 = cudf.read_csv('./NW.csv')데이터 집합을 검토하고 작업 중인 변수를 파악하세요. 이는 데이터프레임의 차원과 데이터의 종류를 이해하는 데 도움이 됩니다. 전체적으로 pandas 구문과 공통점이 있습니다.
pandas와 동일한 .info 명령을 사용하여 전체 데이터 프레임 구조를 살펴봅니다:
GS_cudf.info()
<class 'cudf.core.dataframe.DataFrame'>
RangeIndex: 22034571 entries, 0 to 22034570
Data columns (total 12 columns):
# Column Dtype
--- ------ -----
0 number_sta int64
1 lat float64
2 lon float64
3 height_sta float64
4 date datetime64[ns]
5 dd float64
6 ff float64
7 precip float64
8 hu float64
9 td float64
10 t float64
object
dtypes: datetime64[ns](1), float64(9), int64(1), object(1)
memory usage: 6.5+ GB출력에서는 12개의 변수가 관찰되었고, 변수의 타이틀을 볼 수 있습니다.
데이터에 대해 더 자세히 알아보려면 데이터 프레임의 전체적인 모양(행과 열)을 결정하세요.
# Checking the DataFrame dimensions. Millions of rows by 12 columns.
GS_cudf.shape
(65826837, 12)이 때 데이터 세트 차원은 알 수 있지만 각 변수의 데이터 범위는 알 수 없습니다. 65,826,837개의 행이 있으므로 전체 데이터 집합을 한 번에 시각화할 수 없습니다.
대신, 데이터 프레임의 처음 다섯 행을 살펴보고 소모성 샘플의 변수 입력을 조사합니다:
# Display the first five rows of the DataFrame to examine details
GS_cudf.head()| number_sta | lat | lon | height_sta | date | dd | ff | precip | hu | td | t | psl | |
| 0 | 14066001 | 49.33 | -0.43 | 2.0 | 2016-01-01 | 210.0 | 4.4 | 0.0 | 91.0 | 278.45 | 279.85 | <NA> |
| 1 | 14126001 | 49.15 | 0.04 | 125.0 | 2016-01-01 | <NA> | <NA> | 0.0 | 99.0 | 278.35 | 278.45 | <NA> |
| 2 | 14137001 | 49.18 | -0.46 | 67.0 | 2016-01-01 | 220.0 | 0.6 | 0.0 | 92.0 | 276.45 | 277.65 | 102360.0 |
| 3 | 14216001 | 48.93 | -0.15 | 155.0 | 2016-01-01 | 220.0 | 1.9 | 0.0 | 95.0 | 278.25 | 278.95 | <NA> |
| 4 | 14296001 | 48.80 | -1.03 | 339.0 | 2016-01-01 | <NA> | <NA> | 0.0 | <NA> | <NA> | 278.35 | <NA> |
표 1. 출력 결과
이제 각 행에 포함된 내용을 파악할 수 있습니다. 데이터 소스는 몇 개인가요? 이 모든 데이터를 수집하는 스테이션의 수를 살펴보세요:
# How many weather stations are covered in this dataset?
# Call nunique() to count the distinct elements along a specified axis.
number_stations = GS_cudf['number_sta'].nunique()
print("The full dataset is composed of {} unique weather stations.".format(GS_cudf['number_sta'].nunique()))전체 데이터 세트는 287개의 고유한 기상 관측소로 구성되어 있습니다. 이 기상 관측소는 얼마나 자주 데이터를 업데이트하나요?
## Investigate the frequency of one specific station's data
## date column is datetime dtype, and the diff() function calculates the delta time
## TimedeltaProperties.seconds can help get the delta seconds between each record, divide by 60 seconds to see the minutes difference.
delta_mins = GS_cudf['date'].diff().dt.seconds.max()/60
print(f"The data is recorded every {delta_mins} minutes")데이터는 6.0분마다 기록됩니다. 기상 관측소는 한 시간에 10개의 기록을 생성합니다.
이제 다음과 같은 데이터 특성을 이해했습니다:
- 데이터 유형
- 데이터 집합의 차원
- 데이터 집합을 수집하는 소스의 수
- 데이터 집합 업데이트 빈도
그러나 이 데이터에 누락되거나 잘못된 데이터 입력으로 인해 데이터에 큰 공백이 있는지 살펴봐야 합니다. 이러한 문제는 이 데이터를 그 자체로 신뢰할 수 있는 소스로 사용할 수 있는지 여부에 영향을 미칩니다.
2단계. 격차 파악
이러한 기상 관측소에는 여러 개의 센서가 있습니다. 하나의 센서가 고장 나거나 일 년 내내 신뢰할 수 없는 판독값을 제공할 수 있습니다. 일부 누락된 데이터는 허용되지만, 관측소가 너무 자주 다운되면 데이터가 일 년 내내 실제 상태를 잘못 나타낼 수 있습니다.
이 데이터 소스의 신뢰성을 이해하려면 누락된 데이터의 비율과 유효하지 않은 입력의 수를 분석합니다.
누락된 데이터의 비율을 평가하려면 판독 횟수와 예상 판독 횟수를 비교합니다.
데이터 세트에는 271개의 고유한 스테이션이 포함되어 있으며, 시간당 10개의 레코드가 입력됩니다(6분마다 하나씩). 센서의 다운타임이 없다고 가정할 때 예상되는 기록된 데이터 항목 수는 271 x 10 x 24 x 365 = 23,739,600개입니다. 그러나 앞서 .shape 작업에서 관찰한 것처럼 데이터 행은 22,034,571개에 불과합니다.
# Theoretical number of records is...
theoretical_nb_records = number_stations * (60 / delta_mins) * 365 * 24
actual_nb_of_rows = GS_cudf.shape[0]
missing_record_ratio = 1 - (actual_nb_of_rows/theoretical_nb_records)
print("Percentage of missing records of the NW dataset is: {:.1f}%".format(missing_record_ratio * 100))
print("Theoretical total number of values in dataset is: {:d}".format(int(theoretical_nb_records)))
Percentage of missing records of the NW dataset is: 12.7%1년 전체를 맥락화하면 12.7%는 연간 약 19.8주의 데이터가 누락된 것을 의미합니다.
36주 중 약 5개월의 데이터가 단순히 기록되지 않았다는 것을 알 수 있습니다. 다른 데이터 요소의 경우 일부 변수에 대한 기록은 있지만 다른 변수에 대한 기록은 없는 누락된 데이터가 있습니다. 데이터 집합의 처음 다섯 행을 보면 이 사실을 알 수 있는데, 여기에는 NA가 포함되어 있습니다.
얼마나 많은 NA 데이터가 있는지 이해하려면 먼저 어떤 변수에 NA 판독값이 있는지 파악합니다. 각 범주에 얼마나 많은 유효하지 않은 판독값이 있는지 평가합니다. 분석의 이 부분에서는 2018년 데이터만 고려하도록 데이터 집합을 줄입니다.
# Finding which items have NA value(s) during year 2018
NA_sum = GS_cudf[GS_cudf['date'].dt.year==2018].isna().sum()
NA_data = NA_sum[NA_sum>0]
NA_data.index
StringIndex(['dd' 'ff' 'precip' 'hu' 'td' 't' 'psl'], dtype='object')
NA_data
dd 8605703
ff 8598613
precip 1279127
hu 8783452
td 8786154
t 2893694
psl 17621180
dtype: int64PSL(해수면 압력)이 누락된 수치가 가장 많다는 것을 알 수 있습니다. 전체 판독값의 약 80%가 기록되지 않습니다. 강수량은 유효하지 않은 판독값이 약 6%로 가장 낮은데, 이는 센서가 견고하다는 것을 나타냅니다.
이 두 가지 지표는 데이터 집합에 어떤 차이가 있는지, 분석 중에 어떤 매개 변수에 의존해야 하는지 이해하는 데 도움이 됩니다. 매월 데이터 유효성이 어떻게 변하는지에 대한 종합적인 분석은 노트북을 참조하세요.
이제 데이터의 모양과 격차를 잘 파악했으므로 통계 분석에 영향을 줄 수 있는 변수 간의 관계를 살펴볼 수 있습니다.
3단계. 변수 간의 관계 분석
모든 ML 애플리케이션은 통계 모델링과 많은 분석 애플리케이션에 의존합니다. 어떤 사용 사례든 상관관계가 높은 변수는 결과를 왜곡할 수 있으므로 주의해야 합니다.
이 글에서는 기상 카테고리의 수치를 분석하는 것이 가장 적절합니다. 전체 3년 데이터 집합에 대한 상관관계 매트릭스를 생성하여 주의해야 할 종속성을 평가합니다.
# Only analyze meteorological columns
Meteo_series = ['dd', 'ff', 'precip' ,'hu', 'td', 't', 'psl']
Meteo_df = cudf.DataFrame(GS_cudf,columns=Meteo_series)
Meteo_corr = Meteo_df.dropna().corr()
# Check the items with correlation value > 0.7
Meteo_corr[Meteo_corr>0.7]| dd | ff | precip | hu | td | t | psl | |
| dd | 1.0 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| ff | <NA> | 1.0 | <NA> | <NA> | <NA> | <NA> | <NA> |
| precip | <NA> | <NA> | 1.0 | <NA> | <NA> | <NA> | <NA> |
| hu | <NA> | <NA> | <NA> | 1.0 | <NA> | <NA> | <NA> |
| td | <NA> | <NA> | <NA> | <NA> | 1.0 | 0.840558357 | <NA> |
| t | <NA> | <NA> | <NA> | <NA> | 0.840558357 | 1.0 | <NA> |
| psl | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
행렬에서 td(이슬점)와 t(온도) 사이에는 유의미한 상관관계가 있습니다. 선형 회귀와 같이 변수가 독립적이라고 가정하는 향후 알고리즘을 사용하는 경우 이 점을 고려하세요. 유효하지 않은 데이터 분석으로 돌아가서 선택할 지표로 누락된 판독값이 다른 지표보다 많은지 확인할 수 있습니다.
기본적인 탐색을 마친 후에는 이제 데이터의 차원과 변수를 이해하고 변수 상관관계 행렬을 검토했습니다. 더 많은 EDA 기법이 있지만, 이 게시물에 소개된 방법은 데이터 사이언티스트라면 누구나 익히 알고 있는 일반적인 시작점으로 구성된 일반적인 방법입니다. 튜토리얼을 통해 보셨듯이, cuDF는 pandas 구문과 거의 동일합니다.
EDA를 위한 RAPIDS cuDF 벤치마킹하기
앞서 언급했듯이, 이 게시물은 전체 노트북의 전체 워크플로우에 대한 간단한 안내입니다. 이 게시물에서는 9.55배의 속도 향상을 관찰했습니다. 이러한 결과는 NVIDIA A6000 GPU에서 달성되었습니다.
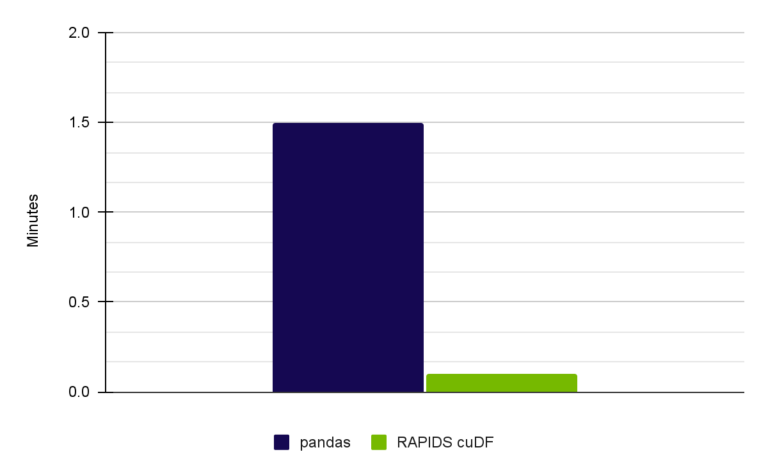
표 3은 이 게시물과 전체 노트북의 결과를 비교한 성능 비교표입니다.
| Full Notebook (15x speed-up) | Pandas on CPU (Intel Core i7-7800X CPU) | user 1 min 15 sec sys: 14.3 sec total: 1 min 30 sec |
| RAPIDS cuDF on NVIDIA A6000 | user 3.92 sec sys: 2.03 sec total: 5.95 sec |
주요 요점
라이브 소스의 실제 데이터에는 인사이트를 개발하기 위해 모델링하기 전에 해결해야 하는 격차, 누락된 정보, 상관관계가 있습니다.
관찰된 15배의 속도 향상으로 더 길고 복잡한 워크로드에 대해 절약된 시간을 추정할 수 있습니다. EDA 단계를 실행하는 데 1시간이 걸리는 경우, 4분 만에 완료할 수 있습니다. 따라서 데이터의 예상치 못한 문제를 해결하고, 데이터 처리를 완료하고, 이 데이터 집합에 1년치 데이터를 추가하여 공백을 최소화하고, 사용 사례에 맞게 데이터 집합을 엔지니어링할 수 있는 56분이 남습니다. 무엇보다도 시간을 다시 통제할 수 있습니다.
탐색적 데이터 분석에서 cuDF에 대해 더 자세히 알아보려면 노트북 전체인 cuDF를 사용한 탐색적 데이터 분석을 검토해 보세요. NVIDIA GTC 2023에 오픈된 무료 데이터 사이언스 세션을 시청해보세요.
시계열 데이터로 cuDF가 작동하는 모습을 보려면 가속화된 데이터 분석: RAPIDS cuDF로 더 빠르게 시계열 분석하기를 참조하세요.
감사의 말
Meiran Peng, David Taubenheim, Sheng Luo, Jay Rodge가 이 게시물에 기여해 주셨습니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.