이 게시물은 가속화된 데이터 분석에 대한 시리즈의 일부입니다:
- 가속화된 데이터 분석: 가속화된 데이터 분석: RAPIDS cuDF로 데이터 탐색 속도 높이기에서는 pandas 라이브러리가 어떻게 Python에서 효율적이고 표현력이 풍부한 함수를 제공하는지에 대해 설명합니다.
- 이 게시물에서는 RAPIDS cuDF를 사용한 시계열 데이터 처리의 일반적인 단계를 안내합니다.
일반적으로 단일 코어로 제한되기 때문에 표준 탐색적 데이터 분석(EDA) 워크플로우에서는 pandas와 유사한 인터페이스를 갖춘 가속화된 데이터 분석 라이브러리인 RAPIDS cuDF를 사용한 가속 컴퓨팅의 이점을 누릴 수 있습니다. 시계열 데이터는 워크플로우에 시간과 복잡성을 더하는 추가 데이터 처리를 필요로 하는 것으로 악명이 높기 때문에, RAPIDS를 활용하는 또 다른 훌륭한 사용 사례입니다.
RAPIDS cuDF를 사용하면 너무 크지도 작지도 않은 ‘골디락스’ 데이터 집합에 대한 시계열 처리 속도를 높일 수 있습니다. 이러한 데이터 세트는 판다에게 부담스럽지만 Apache Spark나 Dask와 같은 완전한 분산 컴퓨팅 도구가 필요하지 않습니다.
시계열 데이터란 무엇인가요?
이 섹션에서는 시계열 데이터를 사용하는 머신 러닝(ML) 사용 사례와 가속화된 데이터 처리를 고려해야 하는 시점에 대해 설명합니다.
시계열 데이터는 어디에나 있습니다. 타임스탬프는 날씨 측정, 자산 가격 책정, 제품 구매 정보 등 다양한 유형의 데이터 원본에서 변수로 사용됩니다.
타임스탬프는 밀리초 단위의 측정값이나 월 단위의 측정값 등 모든 수준의 세분화로 제공됩니다. 타임스탬프 데이터를 복잡한 모델링에 활용하면 시계열 데이터가 되어 다른 변수를 색인화하여 패턴을 관찰할 수 있게 됩니다.
다음과 같은 일반적인 ML 사용 사례는 시계열 데이터에 크게 의존하며, 다른 많은 사용 사례도 마찬가지입니다:
- 금융 서비스 업계의 사기 이상 징후 탐지
- 소매 업계의 예측 분석
- 일기 예보를 위한 센서 판독
- 콘텐츠 제안을 위한 추천 시스템
복잡한 모델링 사용 사례에는 수년에서 수십 년에 걸친 고해상도 과거 데이터가 포함된 대규모 데이터 집합을 처리해야 할 뿐만 아니라 실시간 스트리밍 데이터도 처리해야 하는 경우가 많습니다. 시계열 데이터는 데이터 세트 간에 일관된 기간을 만들기 위해 데이터를 위아래로 리샘플링하고, 패턴의 노이즈를 제거하는 롤링 윈도우로 평활화하는 등의 변환을 거칩니다.
pandas는 이러한 작업을 관리할 수 있는 간단하고 표현력이 풍부한 함수를 제공하지만, 단일 스레드 설계가 필요한 처리량으로 인해 금방 압도당할 수 있다는 것을 직접 작업하면서 보셨을 것입니다. 이는 특히 시계열 분석 사용 사례와 같이 빠른 데이터 처리 처리가 필요한 대규모 데이터 집합이나 사용 사례에 적용될 수 있습니다. 팬더가 데이터를 처리할 때까지 기다리는 시간이 길어지면 답답할 수 있으며 인사이트 도출이 지연될 수 있습니다.
따라서 이러한 시나리오는 시계열 데이터 분석에 cuDF를 매우 적합하게 만듭니다. 팬더와 유사한 API를 사용하면 수십 기가바이트의 데이터를 최대 40배 빠른 속도로 처리할 수 있으므로 모든 데이터 프로젝트에서 가장 귀중한 자산인 시간을 절약할 수 있습니다.
RAPIDS cuDF를 사용한 시계열
이 게시물에서는 RAPIDS cuDF로 데이터를 탐색할 때 가속화의 이점과 이를 쉽게 채택할 수 있는 방법을 보여드리기 위해 시계열 데이터 분석에서 시계열 처리 작업의 하위 집합을 살펴봅니다. 이 게시물은 공개적으로 사용 가능한 실제 기상 관측 데이터 집합에 대한 강력한 노트북 분석으로, RAPIDS GitHub 리포지토리에서 사용할 수 있습니다.
전체 분석에서 RAPIDS cuDF는 13배의 속도로 실행되었습니다(정확한 수치는 이 게시물의 뒷부분에 있는 벤치마킹 섹션 참조). 일반적으로 전체 워크플로우가 복잡해지면 속도가 빨라집니다.
실제 환경에 적용하면 이러한 속도 향상은 실질적인 영향을 미칩니다. 1시간이 걸리는 작업을 5분 이내에 완료할 수 있다면 하루의 시간을 의미 있게 늘릴 수 있습니다.
데이터 세트
Meteonet은 2016년부터 2018년까지 파리 전역에 위치한 기상 관측소의 측정값을 집계하는 실제 날씨 데이터 집합으로, 누락되거나 유효하지 않은 데이터가 포함되어 있습니다. 크기는 약 12.5GB입니다.
분석 접근 방식
이 게시물에서는 이 집계 데이터를 처음 받아 기상학 사용 사례에 맞게 준비해야 하는 데이터 과학자라고 가정해 보겠습니다. 구체적인 사용 사례는 예보, 보고서 또는 기후 모델의 입력이 될 수 있는 개방형입니다.
이 게시물을 검토하면서 대부분의 함수는 판다의 작업과 유사하게 설계되었으므로 익숙할 것입니다. 이 분석은 다음 작업을 수행하도록 구조화되어 있습니다:
- 데이터 프레임의 서식을 지정합니다.
- 시계열을 다시 샘플링합니다.
- 롤링 윈도우 분석을 실행합니다.
이 게시물에서는 노트북에서 설명한 엔드투엔드 워크플로우, cuDF를 사용한 시계열 데이터 분석에서 해결된 몇 가지 데이터 불일치는 무시합니다.
1단계. 데이터 프레임 서식 지정
먼저 다음 명령을 사용하여 이 분석에 사용된 패키지를 가져옵니다:
# Import the necessary packages
import cudf
import cupy as cp
import pandas as pd다음으로 CSV 데이터를 읽어옵니다.
## Read in data
gdf = cudf.read_csv('./SE_data.csv')관심 있는 기상 매개변수인 풍속, 온도, 습도에 초점을 맞추는 것부터 시작하세요.
gdf = gdf.drop(columns=['dd','precip','td','psl'])관심 있는 매개변수를 분리한 후 일련의 빠른 검사를 수행합니다. 날짜 열을 날짜/시간 데이터 유형으로 변환하여 첫 번째 변환을 시작합니다. 그런 다음 처음 5개의 행을 인쇄하여 작업 중인 내용을 시각화하고 표 형식 데이터 집합의 크기를 평가합니다.
# Change the date column to the datetime data type. Look at the DataFrame info
gdf['date'] = cudf.to_datetime(gdf['date'])
gdf.head()
Gdf.shape| number_sta | lat | lon | height_sta | date | ff | hu | t | |
| 0 | 1027003 | 45.83 | 5.11 | 196.0 | 2016-01-01 | <NA> | 98.0 | 279.05 |
| 1 | 1033002 | 46.09 | 5.81 | 350.0 | 2016-01-01 | 0.0 | 99.0 | 278.35 |
| 2 | 1034004 | 45.77 | 5.69 | 330.0 | 2016-01-01 | 0.0 | 100.0 | 279.15 |
| 3 | 1072001 | 46.20 | 5.29 | 260.0 | 2016-01-01 | <NA> | <NA> | 276.55 |
| 4 | 1089001 | 45.98 | 5.33 | 252.0 | 2016-01-01 | 0.0 | 95.0 | 279.55 |
결과
데이터 프레임 모양(127515796, 8)은 127,515,796개의 행과 8개의 열을 보여줍니다. 이제 데이터 집합의 크기와 모양을 알았으므로 데이터의 샘플링 빈도를 확인하기 위해 좀 더 심층적인 조사를 시작할 수 있습니다.
## Investigate the sampling frequency with the diff() function to calculate the time diff
## dt.seconds, which is used to find the seconds value in the datetime frame. Then apply the
## max() function to calculate the maximum date value of the series.
delta_mins = gdf['date'].diff().dt.seconds.max()/60
print(f"The dataset collection covers from {gdf['date'].min()} to {gdf['date'].max()} with {delta_mins} minute sampling interval")데이터 세트는 6분 샘플링 간격으로 2016-01-01T00:00:00.000000000 부터 2018-12-31T23:54:00.000000000,까지의 센서 판독값을 포함합니다. 예상 날짜와 시간이 데이터 집합에 표시되는지 확인합니다.
데이터 집합에 대한 기본적인 검토가 완료되면 시계열별 서식 지정을 시작하세요. 시간 증분을 별도의 열로 분리하는 것부터 시작합니다.
gdf['year'] = gdf['date'].dt.year
gdf['month'] = gdf['date'].dt.month
gdf['day'] = gdf['date'].dt.day
gdf['hour'] = gdf['date'].dt.hour
gdf['mins'] = gdf['date'].dt.minute
gdf.tail이제 데이터는 마지막에 연도, 월, 일의 열로 분리됩니다. 따라서 데이터를 다른 증분 단위로 훨씬 더 간단하게 분할할 수 있습니다.
| number_sta | lat | lon | height_sta | date | ff | hu | t | year | month | day | hour | mins | |
| 127515791 | 84086001 | 43.811 | 5.146 | 672.0 | 2018-12-31 23:54:00 | 3.7 | 85.0 | 276.95 | 2018 | 12 | 31 | 23 | 54 |
| 127515792 | 84087001 | 44.145 | 4.861 | 55.0 | 2018-12-31 23:54:00 | 11.4 | 80.0 | 281.05 | 2018 | 12 | 31 | 23 | 54 |
| 127515793 | 84094001 | 44.289 | 5.131 | 392.0 | 2018-12-31 23:54:00 | 3.6 | 68.0 | 280.05 | 2018 | 12 | 31 | 23 | 54 |
| 127515794 | 84107002 | 44.041 | 5.493 | 836.0 | 2018-12-31 23:54:00 | 0.6 | 91.0 | 270.85 | 2018 | 12 | 31 | 23 | 54 |
| 127515795 | 84150001 | 44.337 | 4.905 | 141.0 | 2018-12-31 23:54:00 | 6.7 | 84.0 | 280.45 | 2018 | 12 | 31 | 23 | 54 |
분석할 특정 시간 범위와 스테이션을 선택하여 업데이트된 데이터프레임을 실험해 보세요.
# Use the cupy.logical_and(...) function to select the data from a specific time range.
import pandas as pd
start_time = pd.Timestamp('2017-02-01T00')
end_time = pd.Timestamp('2018-11-01T00')
station_id = 84086001
gdf_period = gdf.loc[cp.logical_and(cp.logical_and(gdf['date']>start_time,gdf['date']<end_time),gdf['number_sta']==station_id)]
gdf_period.shape
(146039, 13)13개의 변수와 146,039개의 행이 포함된 데이터 프레임이 성공적으로 준비되었습니다.
2단계. 시계열 재샘플링
이제 데이터프레임이 설정되었으므로 간단한 리샘플링 작업을 실행합니다. 데이터는 6분마다 업데이트되지만, 이 경우 데이터를 일 단위 주기로 재구성해야 합니다.
먼저 날짜를 인덱스로 설정하여 나머지 변수가 시간에 따라 조정되도록 합니다. 6분마다 샘플에서 하루에 하나의 레코드로 데이터를 다운샘플링하여 매일 각 변수에 대해 하나의 레코드를 생성합니다. 각 변수의 최대값을 해당 날짜의 레코드로 유지합니다.
## Set "date" as the index. See what that does?
gdf_period.set_index("date", inplace=True)
## Now, resample by daylong intervals and check the max data during the resampled period.
## Use .reset_index() to reset the index instead of date.
gdf_day_max = gdf_period.resample('D').max().bfill().reset_index()
gdf_day_max.head()이제 데이터를 일 단위로 사용할 수 있습니다. 표를 참조하여 작업이 원하는 결과를 얻었는지 확인하세요.
| date | number_sta | lat | lon | height_sta | ff | hu | t | year | month | day | hour | mins | |
| 0 | 2017-02-01 | 84086001 | 43.81 | 5.15 | 672.0 | 8.1 | 98.0 | 283.05 | 2017 | 2 | 1 | 23 | 54 |
| 1 | 2017-02-02 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 98.0 | 283.85 | 2017 | 2 | 2 | 23 | 54 |
| 2 | 2017-02-03 | 84086001 | 43.81 | 5.15 | 672.0 | 10.1 | 99.0 | 281.45 | 2017 | 2 | 3 | 23 | 54 |
| 3 | 2017-02-04 | 84086001 | 43.81 | 5.15 | 672.0 | 12.5 | 99.0 | 284.35 | 2017 | 2 | 4 | 23 | 54 |
| 4 | 2017-02-05 | 84086001 | 43.81 | 5.15 | 672.0 | 7.3 | 99.0 | 280.75 | 2017 | 2 | 5 | 23 | 54 |
3단계. 롤링 윈도우 분석 실행
이전 리샘플링 예제에서는 시간을 기준으로 포인트를 샘플링했습니다. 그러나 롤링 윈도우를 사용하여 빈도를 기준으로 데이터를 평활화할 수도 있습니다.
다음 예에서는 데이터에 길이 3의 롤링 윈도우를 적용합니다. 여기서도 각 변수의 최대값을 유지합니다.
# Specify the rolling window.
gdf_3d_max = gdf_day_max.rolling('3d',min_periods=1).max()
gdf_3d_max.reset_index(inplace=True)
gdf_3d_max.head()롤링 윈도우를 사용하여 데이터 노이즈를 제거하고 시간 경과에 따른 데이터 안정성을 평가할 수 있습니다.
| date | number_sta | lat | lon | height_sta | ff | hu | t | year | month | day | hour | mins | |
| 0 | 2017-02-01 | 84086001 | 43.81 | 5.15 | 672.0 | 8.1 | 98.0 | 283.05 | 2017 | 2 | 1 | 23 | 54 |
| 1 | 2017-02-02 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 98.0 | 283.85 | 2017 | 2 | 2 | 23 | 54 |
| 2 | 2017-02-03 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 99.0 | 283.85 | 2017 | 2 | 3 | 23 | 54 |
| 3 | 2017-02-04 | 84086001 | 43.81 | 5.15 | 672.0 | 14.1 | 99.0 | 283.35 | 2017 | 2 | 4 | 23 | 54 |
| 4 | 2017-02-05 | 84086001 | 43.81 | 5.15 | 672.0 | 12.5 | 99.0 | 283.35 | 2017 | 2 | 5 | 23 | 54 |
이 게시물에서는 시계열 데이터 처리의 일반적인 단계를 안내해 드렸습니다. 예제에서는 날씨 데이터 집합이 사용되었지만, 이 단계는 모든 형태의 시계열 데이터에 적용할 수 있습니다. 프로세스는 오늘날의 시계열 분석 코드와 유사합니다.
성능 속도 향상
Meteonet 날씨 데이터 집합으로 전체 노트북을 실행했을 때, RAPIDS 23.02를 사용하는 NVIDIA RTX A6000 GPU에서 13배의 속도 향상을 달성했습니다(그림 1).
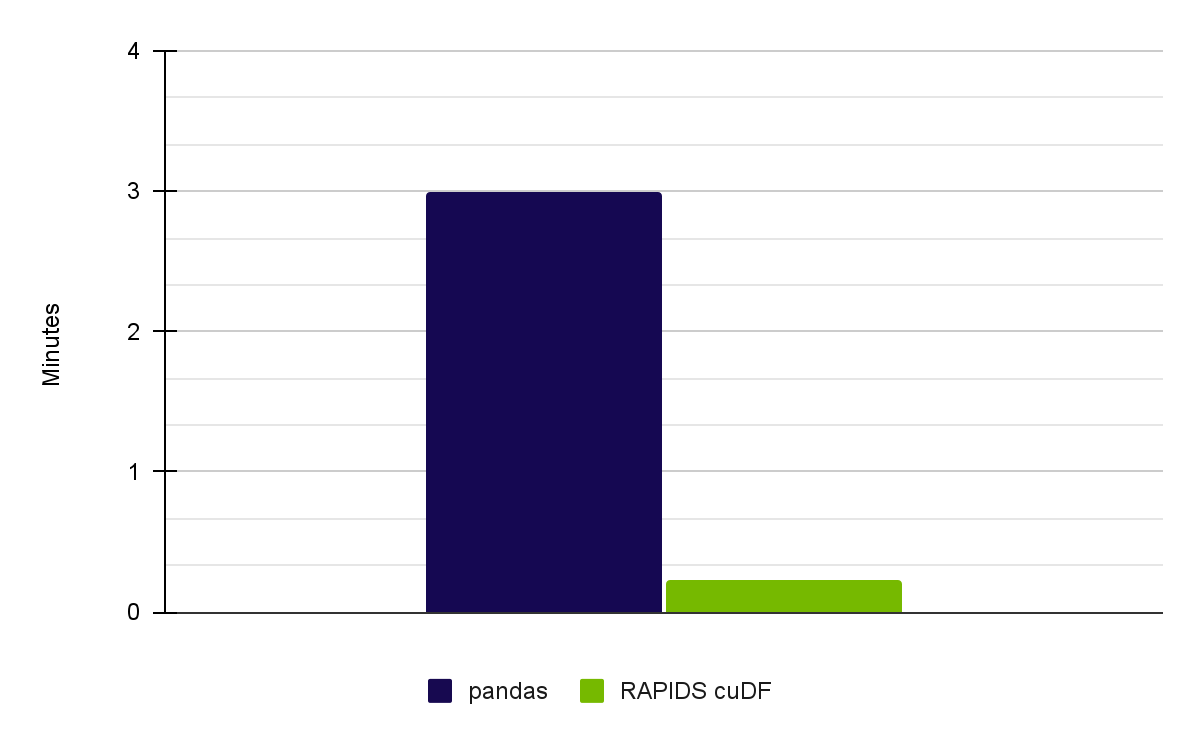
| Pandas on CPU (Intel Core i7-7800X CPU) | User: 2 min 32 sec Sys: 27.3 sec Total: 3 min |
| RAPIDS cuDF on NVIDIA A6000 GPUs | User: 5.33 sec Sys: 8.67 sec Total: 14 sec |
주요 시사점
시계열 분석은 다른 변수에 비해 추가 처리가 필요한 분석의 핵심 부분입니다. RAPIDs cuDF를 사용하면 익숙한 Pandas 기능으로 처리 단계를 더 빠르게 관리하고 인사이트에 도달하는 시간을 단축할 수 있습니다.
시계열 분석에서 cuDF에 대해 더 자세히 알아보려면 GitHub의 rapidsai-community/notebooks-contrib를 참조하세요. EDA 애플리케이션에서 cuDF를 다시 살펴보려면 가속화된 데이터 분석: RAPIDS cuDF로 데이터 탐색 속도를 높이세요를 참고하세요.
3월 20일부터 23일까지 열린 NVIDIA GTC 2023의 데이터 사이언스 세션을 온디맨드로 만나보세요.
출처
Meiran Peng, David Taube
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.