트랜스포머는 오늘날 가장 영향력 있는 AI 모델 아키텍처 중 하나이며 미래 AI R&D의 방향을 형성하고 있습니다. 자연어 처리(NLP)를 위한 도구로 처음 개발된 트랜스포머는 현재 컴퓨터 비전, 자동 음성 인식, 분자 구조 분류, 금융 데이터 처리 등 거의 모든 AI 작업에 활용되고 있습니다.
국내에서는 카카오브레인이 트랜스포머 아키텍처를 기반으로 정확도 높은 대규모 언어 모델인 ‘KoGPT’를 개발했습니다. 대규모 한국어 데이터셋을 학습하고 FasterTransformer를 사용해 최적화에 성공했습니다. 이번 블로그에서는 엔비디아와 카카오브레인이 어떻게 FasterTransformer를 통해 KoGPT를 최적화했는지 살펴보겠습니다.
FasterTransformer 소개
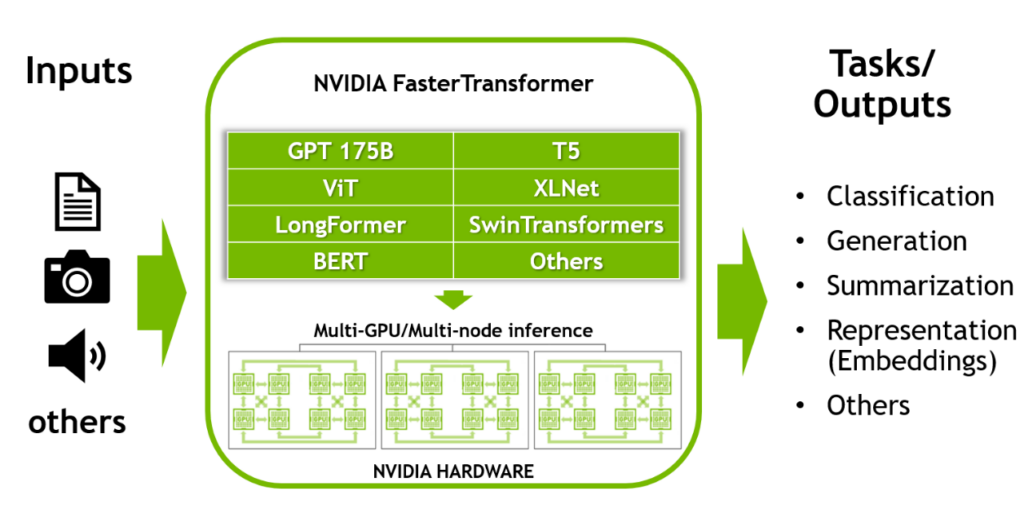
Transformer 는 현재 딥러닝에서 가장 널리 사용되고 있는 딥러닝 아키텍처입니다. NLP (Natural Language Processing) 분야를 시작으로 Vision, Speech, Generative AI영역을 넘어서 적용범위가 확장되고 있습니다. NLP 영역에서 가장 주목받는 AI 모델로는 GPT 모델이 있습니다. GPT 모델은 OpenAI에서 개발한 언어 모델로써 Transformer 모델 아키텍처에서 decoder block을 여러 겹 쌓아 만들어낸 언어 모델입니다. 예를 들어 GPT-3는 수천억개의 매개변수를 가지는 대규모 언어 모델로 거대한 백과사전과 같이 방대한 양의 정보를 집적할 수 있습니다.
하지만 이런 거대언어모델을 학습하기 위해서는 다음과 같은 어려움이 있습니다.
- 이러한 거대언어모델은 단일 GPU의 용량을 초과할 수 있는 상당한 양의 메모리를 차지합니다.
- 훈련과 추론에는 막대한 연산 작업이 필요하기 때문에 상당한 시간이 소요될 수 있습니다. 따라서 알고리즘, 소프트웨어, 하드웨어 등 스택의 모든 레벨에 대한 최적화가 필요합니다.
Nemo 프레임워크와 FasterTransformer는 각각 수천억 개의 매개변수가 있는 대규모 언어 모델에 대해 더 빠른 학습과 추론을 지원합니다.
FasterTransformer의 최적화
FasterTransformer는 앞서 설명한 모델 병렬화 (텐서병렬화와 파이프라인병렬화) 방법을 사용하여 거대 트랜스포머 모델에 대해 추론 가속 엔진을 구현한 라이브러리입니다. FasterTransformer는 기존 딥 러닝 프레임워크에 비해 지연 시간을 최소화하고 처리량을 최대화하기 위해 개발되었습니다.
FasterTransformer에는 사용자에게 트랜스포머 모델의 최적화된 디코더와 인코더 블록을 제공합니다. C++/CUDA로 작성되었으며 TensorFlow, Pytorch 및 Triton Backend 프레임워크의 API를 제공합니다. 주요 기능을 시연할 수 있는 샘플 코드가 함께 제공됩니다. 이미 많은 모델 (GPT-3, GPT-J, GPT-NeoX, BERT, ViT, SwinTransformer, Longformer, T5, XLNet, BLOOM) 을 지원하며, 새로운 모델에 대한 지원이 지속적으로 추가되고 있습니다. 또한 프롬프트 러닝 기법도 지원합니다. 최신 지원 matrix는 여기를 참조하세요. (https://github.com/NVIDIA/FasterTransformer#support-matrix)
앞서 설명한 바와 같이 FasterTransformer는 다른 딥 러닝 Framework보다 낮은 지연시간과 높은 처리량, 그리고 빠른 inference pipeline을 구현 합니다. 다음은 FasterTransformer에서 사용된 몇가지 최적화 기술을 소개하겠습니다.
- Layer Fusion: 레이어 퓨전은 여러 레이어를 단일 레이어로 결합하는 기법입니다. 이 기법은 데이터 전송을 줄이고 연산 집약도를 높여 추론 연산을 가속화합니다. 이러한 가속화의 예로 Bias + LayerNormalization, Bias + activation, Bias + Softmax 및 Attention layer의 3개의 transpose matrix의 fusion 등의 기술이 있습니다.
- Multi-head attention Acceleration: Multi-head attention은 시퀀스에서 토큰 간의 관계를 연산합니다. 이 과정에는 많은 양의 연산과 메모리 복사가 필요합니다. FasterTransformer에서는 데이터 캐시를 유지하여 연산을 줄이고(K/V cache), 퓨즈 커널을 이용하여 메모리 전송 크기를 최소화합니다.
- GEMM Kernel autotuning: Matrix Multiplication은 트랜스포머 기반 모델에서 가장 일반적이며 무거운 연산입니다. FasterTransformer는 이 연산을 실행하기 위해 cuBLAS 및 CUTLASS 라이브러리에서 제공하는 기능을 사용합니다. Matrix Multiplication 연산은 “하드웨어” 수준에서 서로 다른 low-level 연산을 구현할 수 있습니다. FasterTransformer는 모델의 매개 변수(Attachment 레이어, 크기, Attachment 헤드 수, 히든 레이어 크기, 등)와 입력 데이터에 대해 실시간 벤치마크를 수행하고 가장 적합한 함수와 매개 변수를 선택합니다.
- Lower precision: Fastertransformer에서는 FP16과 BF16, INT8 데이터 타입과 같은 낮은 정밀도의 데이터 타입을 지원합니다. FP16과 BF16, INT8에 대한 연산은 NVIDIA의 최신 GPU(Volta 아키텍쳐 이후)에서 TensorCore를 통해 가속화 할 수 있습니다. 특히, Hopper GPU에서는 Transformer engine과 같은 특수 하드웨어를 실행할 수 있습니다.
KoGPT 소개

카카오브레인의 KoGPT는 제시된 한국어를 사전적, 문맥적으로 이해하고 사용자의 의도에 맞춘 문장을 생성해 제공합니다. GPT-3 기반 언어 모델인 KoGPT를 활용하여, 주어진 문장이 긍정인지 부정인지 판단하기, 내용 요약 또는 결과 예측하기, 질문에 답하기, 다음 문장 생성하기 등 한국어와 관련된 모든 작업을 수행할 수 있습니다. 이 외에도 다양한 분야에서 기계 독해, 기계 번역, 작문, 감정 분석 등 고차원적인 언어 작업에도 활용할 수 있습니다.
KoGPT 의 성능과 FasterTransformer
카카오브레인은 GPT-3 기반 언어 모델인 KoGPT를 서비스하고자 했습니다. KoGPT는 HuggingFace를 기반으로 구현되어 있었습니다. 훈련을 할때는 성능이 중요해서 속도가 문제가 되지 않았지만 서비스를 해야하는 상황에서는 속도가 크게 문제가 되었습니다. 추론 속도가 느릴수록 서비스에 투입되어야 하는 서버의 갯수는 기하급수적으로 증가하고 이는 운영 비용으로 연결되기 때문에 추론 속도의 최적화는 반드시 필요했습니다. 카카오브레인은 GPT-3의 추론 속도를 최적화하는 여러가지 방법을 찾고 적용해봤지만 크게 개선 효과를 얻지 못했습니다. 그러던 중 NVIDIA의 FasterTransformer를 적용하고나서 추론 속도가 매우 크게 개선되는 것을 확인할 수 있었습니다. 추론 속도는 입력과 출력 토큰 수에 따라 다르지만 평균적으로 V100 1 GPU에서 기존 속도보다 최대 4배 (400%) 까지 추론 속도가 향상됨을 확인할 수 있었습니다. NVIDIA의 FasterTransformer는 텐서 병렬화, 파이프라인 병렬화도 지원하며, V100 4 GPU를 사용할 경우 추론 속도가 기존보다 11배 (1100%) 이상 향상됨을 확인할 수 있었습니다.

NVIDIA의 FasterTransformer를 통해 KoGPT는 서비스 출시 전 직면해야 했던 기술적 과제를 쉽게 극복할 수 있었고, 카카오브레인 ML Optimization 팀은 동일한 하드웨어에서 기존보다 더 많은 요청을 처리할 수 있어 수익성(TCO)도 15%이상 개선할 수 있었습니다.
앞으로 카카오브레인의 한국어 특화 LLM 모델 KoGPT와 한국형 AI 챗봇 KoChat GPT에 대해 더 궁금하신 분들은 다음 링크를 참조해 주세요.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.