
빠르게 진화하는 생성형 AI 환경에서 가속화된 추론 속도에 대한 요구는 여전히 시급한 문제입니다. 모델 크기와 복잡성이 기하급수적으로 증가함에 따라 수많은 사용자에게 동시에 서비스를 제공하기 위해 신속하게 결과를 생성해야 할 필요성이 계속 커지고 있습니다. NVIDIA 플랫폼은 이러한 노력의 최전선에서 칩, 시스템, 소프트웨어, 알고리즘 등 전체 기술 스택에 걸친 혁신을 통해 지속적인 성능 향상을 구현합니다.
NVIDIA는 최첨단 사후 트레이닝 및 트레이닝 인더루프 모델 최적화 기술의 종합 라이브러리인 NVIDIA TensorRT Model Optimizer를 통해 추론 서비스를 확장하고 있습니다. 이러한 기술에는 모델 복잡성을 줄이기 위한 양자화 및 희소성이 포함되어 있어 NVIDIA TensorRT-LLM 같은 다운스트림 추론 라이브러리가 딥 러닝 모델의 추론 속도를 더 효율적으로 최적화할 수 있습니다.
NVIDIA TensorRT 에코시스템의 일부에 속하는 NVIDIA TensorRT Model Optimizer(Model Optimizer라고도 함)는 NVIDIA Hopper, NVIDIA Ampere및 NVIDIA Ada Lovelace등의 인기 아키텍처에서 사용할 수 있습니다.
Model Optimizer는 PyTorch 및 ONNX 모델에 대해 시뮬레이션된 양자화된 체크포인트를 생성합니다. 이러한 양자화된 체크포인트는 TensorRT-LLM 또는 TensorRT에 원활하게 배포할 수 있으며 다른 인기 있는 배포 프레임워크도 곧 지원할 예정입니다. Model Optimizer Python API를 사용하면 개발자가 다양한 모델 최적화 기술을 스택하여 TensorRT의 기존 런타임 및 컴파일러 최적화를 기반으로 추론을 가속화할 수 있습니다.
NVIDIA TensorRT Model Optimizer는 2024년 5월 8일에 공개되었으며 모든 개발자는 이 옵티마이저를 NVIDIA PyPI 휠로서 무료로 사용할 수 있습니다. GitHub에서 NVIDIA/TensorRT-Model-Optimizer 를 방문하여 예제 스크립트를 확인하고 자세한 내용은 설명서를 참조하세요.
양자화 기술
트레이닝 후 양자화(PTQ)는 메모리 설치 공간을 줄이고 추론을 가속화하는 가장 인기 있는 모델 압축 방법 중 하나에 속합니다. 그 외 일부 양자화 툴킷은 가중치 전용 양자화 또는 기본 기술만 지원하지만 Model Optimizer는 INT8 SmoothQuant 및 INT4 AWQ(활성화 인식 가중치 양자화)를 포함한 고급 보정 알고리즘을 제공합니다. TensorRT-LLM에서 FP8 또는 그보다 더 낮은 정밀도(예: INT8 또는 INT4)를 사용하는 경우, Model Optimizer의 PTQ를 이미 내부에서 활용하고 있는 것입니다.
지난 1년 동안 Model Optimizer의 PTQ는 이미 수많은 TensorRT-LLM 사용자가 모델 정확도를 유지하면서 LLM에 대해 추론 속도를 현저하게 향상할 수 있도록 지원했습니다. INT4 AWQ를 활용하는 Falcon 180B는 단일 NVIDIA H200 GPU에 적합합니다. 그림 1은 사용자가 Llama 3 모델에서 Model Optimizer PTQ를 사용하여 실현할 수 있는 추론 속도 향상을 보여줍니다.

지연 시간은 인플라이트 배치 처리 없이 측정되었습니다. 가속은 GPU 수로 정규화됩니다.
양자화가 없다면 확산 모델은 NVIDIA A100 Tensor 코어 GPU에서도 이미지를 생성하는 데 최대 1초가 걸릴 수 있으며 최종 사용자의 경험에 영향을 미칠 수 있습니다. Model Optimizer의 선도적인 8비트(INT8 및 FP8) 트레이닝 후 양자화는 이미지 생성 속도를 높이기 위해 TensorRT의 확산 배포 파이프라인 및 Stable Diffusion XL NIM 의 내부에서 사용되었습니다.
MLPerf Inference v4.0에서 Model Optimizer는 TensorRT를 더욱 강화하여 Stable Diffusion XL 성능에 대한 기준을 다른 모든 접근 방식보다 높게 설정했습니다. 이 8비트 양자화 기능을 활용한 많은 생성형 AI 업체들은 모델 품질을 유지하면서 더 빠른 추론의 사용자 경험을 제공할 수 있게 되었습니다.
FP8 및 INT8 모두에 대한 엔드 투 엔드 예시를 보려면 GitHub에서 NVIDIA/TensorRT-Model-Optimizer와 NVIDIA/TensorRT를 참조하세요. 보정 데이터세트의 크기에 따라 차이는 있겠지만 확산 모델의 보정 프로세스는 대체로 몇 분 정도 걸립니다. FP8의 경우, RTX 6000 Ada에서는 1.45배, FP8 MHA가 없는 L40S에서는 1.35배의 속도 향상을 확인했습니다. 표 1은 INT8 및 FP8 양자화의 추가적인 벤치마크를 보여줍니다.
| 그래픽 카드 | INT8 지연 시간(ms) | FP8 지연 시간(ms) | 속도 향상(INT8 vs FP16) | 속도 향상(FP8 vs FP16) |
| RTX 6000 Ada | 2,479 | 2,441 | 1.43배 | 1.45배 |
| RTX 4090 | 2,058 | 2,161 | 1.20배 | 1.14배 |
| L40S | 2,339 | 2,168 | 1.25배 | 1.35배 |
| H100 80GB HBM3 | 1,209 | 1,216 | 1.08배 | 1.07배 |
구성: Stable Diffusion XL 1.0 기본 모델. 이미지 해상도 = 1024×1024, 30단계. TensorRT v9.3. 배치 크기=1

차세대 플랫폼을 위한 초저정밀도 추론 지원
최근에 발표된 NVIDIA Blackwell 플랫폼은 4비트 부동 소수점 AI 추론 기능으로 컴퓨팅의 새로운 시대를 열고 있습니다. Model Optimizer는 모델 품질을 유지하면서 4비트 추론을 지원하는 데 중추적인 역할을 합니다. 4비트 추론으로 이동할 때 트레이닝 후 양자화는 대체로 상당한 수준의 정확도 저하를 초래합니다.
이 문제를 해결하기 위해 Model Optimizer는 개발자가 정확도를 저하시키지 않으면서 4비트로 추론 속도를 최대한 활용할 수 있도록 양자화 인식 트레이닝(QAT)을 제공합니다. QAT는 트레이닝 중에 스케일링 계수를 계산하고 시뮬레이션된 양자화 손실을 미세 조정 프로세스에 통합함으로써 뉴럴 네트워크가 양자화에 더 탄력적으로 대응할 수 있도록 지원합니다.
Model Optimizer QAT 워크플로우는 NVIDIA NeMo, Megatron-LM 및 Hugging Face Trainer API를 포함한 최고의 트레이닝 프레임워크와 통합되도록 설계되었습니다. 이를 통해 개발자는 다양한 프레임워크에서 NVIDIA 플랫폼의 기능을 활용할 수 있습니다. NVIDIA Blackwell 플랫폼을 사용하기 전에 QAT를 시작하려면 Hugging Face Trainer API를 사용하여 INT4 QAT 예제를 따르세요.
NVIDIA의 연구에 따르면 QAT가 사전 트레이닝 단계 대신 SFT(supervised fine-tuning) 단계에서만 적용되는 경우에도 QAT는 낮은 정밀도에서 PTQ보다 더 나은 성능을 구현할 수 있는 것으로 밝혀졌습니다. 즉, QAT는 낮은 트레이닝 비용으로 적용할 수 있으며, 정확도 저하에 민감한 생성형 AI 애플리케이션이 가까운 미래에 가중치와 활성화가 모두 4비트인 초저정밀도에서도 정확도를 유지할 수 있도록 지원합니다.
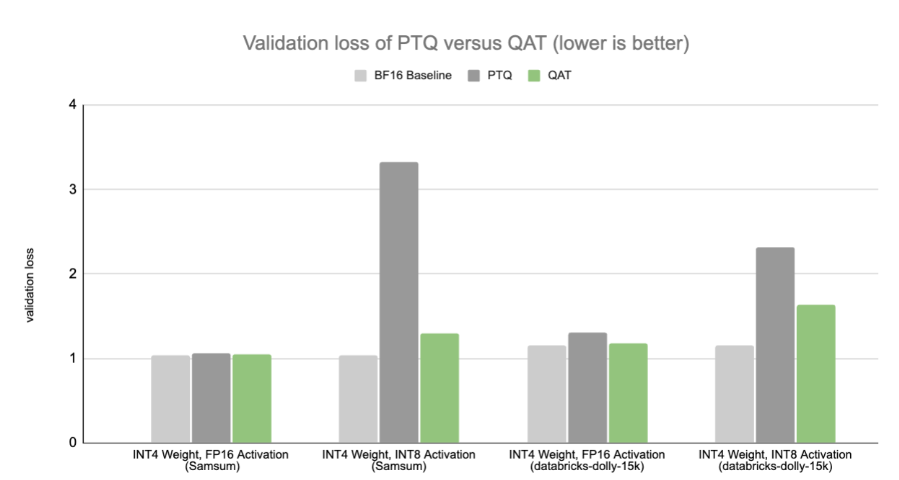
기준선은 대상 데이터세트에서 미세 조정됩니다. 이 벤치마크에서는 INT4를 사용하여 QAT를 시연합니다. 4비트 결과는 NVIDIA Blackwell 플랫폼의 일반 출시와 함께 제공됩니다.
희소성이 있는 모델 압축
딥 러닝 모델은 전통적으로 밀도가 높고 과다 매개변수화되어 있습니다. 이로 인해 또 다른 모델 최적화 기술이 필요합니다. 희소성은 모델 매개변수의 0값을 선택적으로 권장하여 모델의 크기를 더욱 축소합니다. 이 값은 스토리지 또는 연산에서 폐기할 수 있습니다.
Model Optimizer의 트레이닝 후 희소성은 Llama 2 70B에 대한 FP8 양자화 외에 배치 크기 32에서 1.62배만큼 속도를 더 높여줍니다. 여기서는 NVIDIA Ampere 아키텍처에 도입된 독점 NVIDIA 2:4 희소성이 적용된 NVIDIA H100 GPU 1개가 사용되었습니다. 자세한 내용을 알아보려면 NVIDIA Ampere 아키텍처 및 NVIDIA TensorRT를 사용하여 희소성을 통해 추론 가속화를 참조하세요.
MLPerf Inference v4.0에서 TensorRT-LLM은 트레이닝 후 희소성 Model Optimizer를 사용하여 Llama 2 70B를 37% 압축합니다. 이를 통해 모델과 KV 캐시를 단일 H100 GPU의 GPU 메모리에 맞출 수 있으며 Tensor 병렬 처리 수준은 2에서 1로 감소합니다. MLPerf의 이 특정 요약 작업에서 Model Optimizer는 희소화된 모델의 품질을 유지하며 MLPerf 마감 부서에서 설정한 Rouge 점수의 99.9% 정확도 목표를 충족합니다.
| 모델 | 배치 크기 | 추론 속도 향상 (배치 크기가 동일한 FP8 밀집 모델과 비교) |
희소화된 Llama 2 70B | 32 | 1.62배 |
| 64 | 1.52배 | |
| 128 | 1.35배 | |
| 896 | 1.30배 |
FP8: 희소화된 모든 모델에 대해 TP=1, PP=1. 고밀도 모델은 가중치 크기가 더 크기 때문에 TP=2를 필요로 함
MLPerf 설정에서는 정확도 저하가 거의 없지만 대개의 경우에는 모델 품질을 유지하기 위해 희소성과 미세 조정을 결합하는 것이 일반적입니다. Model Optimizer는 FSDP를 포함한 인기 있는 병렬 처리 기술과 호환되는 희소성 인식 미세 조정을 위한 API를 제공합니다. 그림 4는 미세 조정과 함께 SparseGPT를 사용하면 손실 저하를 최소화할 수 있음을 보여줍니다.

구성 가능한 모델 최적화 API
기존에는 하나의 모델에 양자화 및 희소성과 같은 다양한 최적화 기술을 적용할 때 중요한 다단계 접근 방식이 필요했습니다. 이러한 문제점을 해결하기 위해 Model Optimizer는 개발자가 여러 최적화 단계를 쌓을 수 있도록 구성 가능한 API를 제공합니다. 그림 5의 코드 스니펫은 희소성과 양자화를 Model Optimizer 구성 가능 API와 결합하는 방법을 보여줍니다.

또한 Model Optimizer는 재현성을 최대한 높여야 하는 모든 실험을 대상으로 모델 상태 정보를 검색하고 모델 수정 사항을 완전히 복원하는 한 줄 API와 같은 여러 가지 유용한 기능을 함께 제공합니다.
시작하기
이제 NVIDIA TensorRT Model Optimizer를 NVIDIA PyPI에 nvidia-modelopt로 설치할 수 있습니다. 추론 최적화를 위한 예제 스크립트 및 레시피에 액세스하려면 GitHub의 NVIDIA/TensorRT-Model-Optimizer를 방문하세요. 자세한 내용은 TensorRT Model Optimizer 설명서를 참조하십시오.
도움 주신 분들
TensorRT Model Optimizer 개발을 지원한 Asma Kuriparambil Thekkumpate, Kai Xu, Lucas Liebenwein, Zhiyu Cheng, Riyad Islam, Ajinkya Rasane, Jingyu Xin, Wei-Ming Chen, Shengliang Xu, Meng Xin, Ye Yu, Chen-han Yu, Keval Morabia, Asha Anoosheh 및 James Shen을 포함한 엔지니어들의 헌신과 수고에 특별한 감사의 인사를 드립니다. (순서는 기여도 수준을 반영하지 않습니다)
관련 리소스
- GTC 세션: TensorRT-LLM 및 TensorRT에서 양자화를 통한 생성형 AI 추론 최적화
- GTC 세션: 추론 성능 최적화 및 데스크톱과 워크스테이션에 새로운 LLM 기능 통합
- GTC 세션: 텍스트 생성을 위해 TensorRT-LLM으로 LLM 최적화 및 확장하기
- SDK: TensorRT
- SDK: TensorFlow-TensorRT
- SDK: Torch-TensorRT