
3GPP の第 5 世代 (5G) セルラー規格では、レイヤー 1 (L1) または物理レイヤー (PHY) は、無線アクセス ネットワーク (RAN) の作業負荷の中で最も計算量の多い部分です。PHY には、チャネル推定や等化、変調/復調、前方誤り訂正 (FEC) などの高度なアルゴリズムによる最も複雑な数学演算が含まれます。これらの機能は、5G の低遅延要件と異なる無線条件でのシグナル インテグリティを維持するために、高い計算密度を必要とします。
従来、このレイヤーは、例えばデジタル信号処理 (DSP) コアを備えた専用の特定用途向け集積回路 (ASIC) など、専用のハードウェアを使って実装されてきました。しかし、このアプローチにはいくつかの欠点があります。性能を拡張できないこと、ハードウェアとソフトウェアの組み合わせが密であること、単一ベンダーのソリューションに閉じていることです。これらはすべて、RAN の展開と運用にかかるコストの高さにつながります。
このような課題に対処するため、業界は x86 CPU ベースの商用オフザシェルフ (COTS) サーバーを使用した仮想化 RAN (vRAN) やオープン RAN (O-RAN) アーキテクチャに向けて進化してきました。これによってコストを削減でき、ハードウェアとソフトウェアの分離によってイノベーション サイクルが加速し、クラウドネイティブ アーキテクチャへの道が開けると期待されています。
しかし、L1 には複雑な信号処理が必要なため、x86 CPU ベースの COTS サーバーで望ましい vRAN の性能を達成するのは困難です。この L1 性能ギャップに対処するため、一部の業界関係者は固定機能アクセラレータを構築しています。例えば、ディスクリート ASIC、フィールド プログラマブル ゲート アレイ (FPGA)、統合システムオンチップ (SoC) などがあります。
固定機能アクセラレータは、CPU の性能を補完し、vRAN L1 パイプラインからオフロードされ選択された一連の機能の処理を高速化しながら、L1 処理の大部分を CPU 内に保持します。これは、業界ではルックアサイド アクセラレーションと呼ばれる高速化方法です。
多くの点で、固定機能ルックアサイド アクセラレータベースの vRAN プラットフォームは、アプライアンスのようなマクロ基地局アーキテクチャ モデルにタイムスリップしたようなもので、拡張性と敏捷性に欠けています。私たちの業界が必要としているのは、オープン RAN の重要な理念である相互運用性とマルチベンダー ソリューションをサポートしながら、プログラム可能性、性能、ソフトウェアの拡張性を提供できる完全ソフトウェア デファインドの vRAN です。
人工知能と機械学習 (AI/ML) が 5G 以降の状況を形成する重要な原動力の 1 つとして台頭する中、業界にとって、将来を見据えた vRAN プラットフォームを採用することも同様に重要です。既存の RAN インフラの上に拡張機能として AI/ML のような新機能を有効にする準備を整える必要があります。
NVIDIA Aerial プラットフォーム
NVIDIA Aerial プラットフォームは、5G 向けの NVIDIA Aerial vRAN スタック、AI フレームワーク、およびアクセラレーテッド コンピューティング インフラを統合します。このプラットフォームは、GPU の高度なプログラム可能性と並列処理能力を利用することで、重要な利点を提供します。このプラットフォームは、2 つの点で従来の固定機能ルックアサイド アクセラレーション アプローチとは異なります:
- 固定機能アクセラレータを使用しない
- L1 機能のサブセットを選択的にアクセラレータにオフロードするのではなく、NVIDIA Aerial は、インライン アクセラレーションと呼ばれるアプローチで、GPU 内に L1 処理パイプライン全体を実装します。
NVIDIA Aerial vRAN スタックは、完全にプログラム可能、ソフトウェアデファインド、AI 対応、クラウドネイティブな 5G vRAN です。NVIDIA Aerial がどのようにスタートしたかは、2019 Mobile World Congress の NVIDIA cuBB GPU Accelerated 5G vRAN セッションをご覧ください。
この記事では、GPU ベースのインライン アーキテクチャである NVIDIA Aerial の利点をご紹介します。プログラム可能なインライン アクセラレーションが、高性能でエネルギー効率に優れ、高い拡張性でクラウドネイティブな vRAN を実現するための重要な基盤である理由をご説明します。
ルックアサイドとインライン アクセラレーション モデルを理解する
まずはじめに、ルックアサイドとインライン アクセラレーション モデルの一般的な動作原理を見ていきましょう。
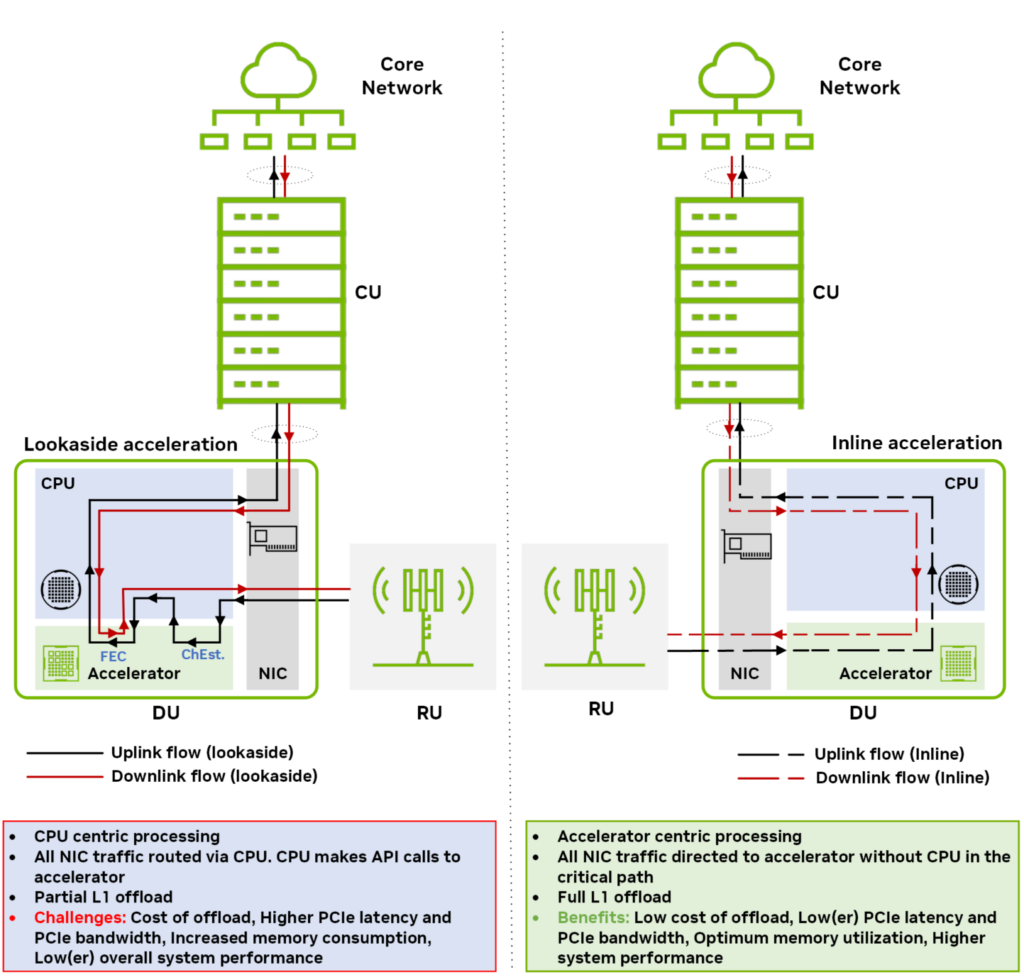
図 1 は、2 つの異なるアクセラレーション モデルのダウンリンクとアップリンク方向のデータ フローを示しています: ルックアサイドとインライン。詳細については、「オープン無線アクセス ネットワークのためのハードウェア により高速化: 現代の概要」を参照してください。
ルックアサイド アクセラレーション モデルでは、ホスト CPU はデータ処理のオフロードをアクセラレータに要求し、処理が終了すると結果を受信します。ルックアサイド アプローチでは、CPU とアクセラレータの間で往復のデータ転送が必要です。オフロードする機能ブロックが複数あり、連続していない場合 (たとえば、FEC デコードとチャネル推定)、ホストからデバイスへのデータ転送のオーバーヘッドと、その結果生じるメモリ帯域幅の消費が著しく大きくなります。
インライン アクセラレーション モデルでは、CPU をクリティカル パスに関与させることなく、アクセラレータがネットワーク インターフェイス カード (NIC) と直接データを交換します。インライン モデルで完全な L1 アクセラレーションを行う場合は、L1 処理全体がアクセラレータにオフロードされます。
インライン アクセラレーションでは、ルックアサイド アクセラレーションとは異なり、ホストとデバイス間で冗長なデータ転送を行ったり来たりする必要はありません。その結果、メモリと PCIe 帯域幅がより効率的に使用されます。
プログラム可能なインライン アクセラレーションは vRAN に最適
2 つのアクセラレーション アプローチに基づく vRAN ソリューションを詳しく見てみましょう:
- 固定機能アクセラレータを備えたルックアサイド
- プログラム可能なアクセラレータを備えたインライン
このセクションでは、それぞれの利点と制限に注目し、プログラム可能なアクセラレータを使用するインライン アプローチが、固定機能アクセラレータを使用するルックアサイドと比較して、vRAN に適している理由を説明します。
- ルックアサイドのオフロード費用は遅延と性能に影響する
- ルックアサイドのサービス品質保証は複雑さを増す
- PCIe デバイスとして統合されたルックアサイド アクセラレータは、インライン アクセラレータと同等ではない
- 固定機能アクセラレータは本質的にクラウド ネイティブではない
- 固定機能アクセラレータは拡張性に欠ける
- 固定機能アクセラレータは敏捷性に欠ける
ルックアサイドのオフロード費用は遅延と性能に影響する
ルックアサイド アクセラレーションでは、CPU とアクセラレータ間の PCIe インターフェイスを介したリクエスト/レスポンス処理により、オフロードの費用が発生します。複数の前後処理が発生する場合 (非連続機能のセットをオフロードするため)、ルックアサイド アクセラレーションは CPU サイクル消費と遅延の両方を増加させ、消費電力 1 ワット当たりの性能と費用当たりの性能に影響を与えます。
オフロードの費用を削減するために、アクセラレータ ドライバーは複数のリクエストを組み合わせたり、バッチ処理したりすることがあります。しかし、これは望ましくないバッファとキューを引き起こし、様々なユーザー データ フローの遅延を著しく増大させます。
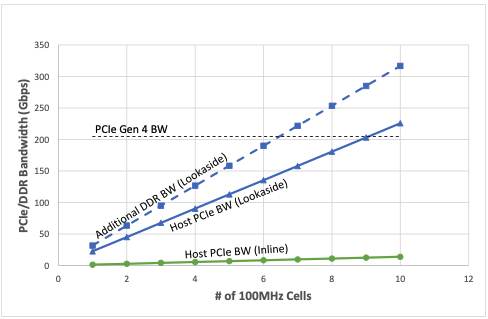
図 2 は、サポートされる 4-送信-4-受信 (4T4R) 100MHz セルの数が増えるにつれて、予想されるホスト PCIe とダブル データ レート帯域幅 (DDR BW) の消費量 (Gbps) を示しています。このグラフは、ルックアサイド アクセラレータを使用した場合、4 つのダウンリンク (DL) レイヤーと 2 つのアップリンク (UL) レイヤー (各 100MHz セル) をサポートするために必要な処理帯域幅の合計が大幅に悪化することを示しています。インライン アクセラレータと比較すると、約 40 倍の帯域幅が消費されます。
また、セル数が増えるにつれて、PCIe Gen4 技術では必要な帯域幅を維持できなくなり、ルックアサイド アクセラレータをサポートするために PCIe Gen5 技術が必要になることも特筆すべき点です。
ルックアサイドのサービス品質保証は複雑さを増す
さまざまなユーザー データ フローに対するきめ細かな QoS サポートは、ルックアサイド アクセラレータのもう 1 つの課題です。QoS のニーズを満たすために PCIe インターフェイス全体で必要とされる複雑なキューイング アーキテクチャは、性能の低下を招き、アクセラレータにキューイングされたリクエストのテール レイテンシに影響を与える可能性があります。
一例として、VoIP (Voice over Internet Protocol)、IoT (Internet of Things)、eMBB (Enhanced Mobile Broadband)、URLLC (Ultra-Reliable Low-Latency Communications) アプリケーションの混合ユーザー データ フローをサポートする DU システムについて考えてみましょう。ルックアサイド モデルでは、VoIP や URLLC のパケットが、アクセラレータにキューイングされた eMBB データの大きなブロックの後ろに滞留すると、大きな遅延とジッターが発生し、QoS が低下します。すべての処理がルックアサイド アクセラレータを通過する必要があるため、このような現象が時間の経過とともに蓄積され、結果として性能が大幅に低下します。
ルックアサイド PCIe インターフェイス全体の QoS 保証と iCal スケジューリングによって、これらの問題に対処する方法があります。しかし、これはハードウェアとソフトウェアの両方を複雑化させ、コストとエネルギー消費の増加、およびセル容量の減少をもたらします。
ルックアサイドと比較して、インライン アクセラレータを導入することによるセル容量と電力効率の利点をさらに実証するために、以下のシステム構成の 2 つの指標に関して両アクセラレーション モードの性能を評価しました: 100 MHz、4T4R、4 DL/2 UL レイヤー:
- サポートされる 100MHz セル数
- MHz*レイヤー/ワット
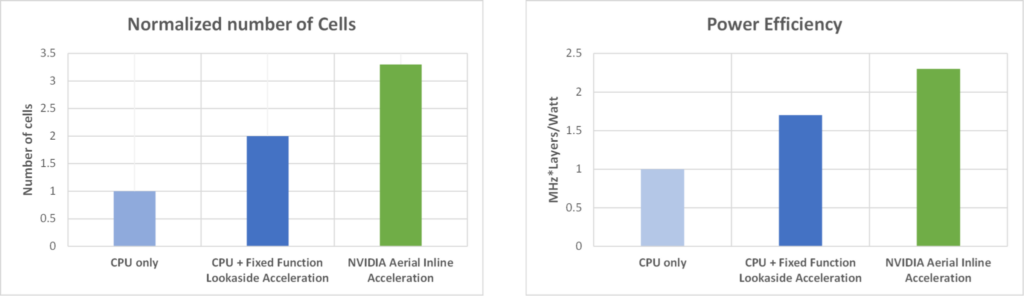
図 3 は、左側にサポートされるセル数 (正規化) 、右側に MHz* レイヤー/ワットの指標を示した性能比較です。各指標について、インライン アクセラレータを導入した場合のセル容量と電力効率の利点は、固定機能のルックアサイド アクセラレータとアクセラレータなし (つまり CPU のみ) と比べて明らかです。
PCIe デバイスとして統合されたルックアサイド アクセラレータは、インライン アクセラレータと同等ではない
ルックアサイド アクセラレータを CPU に統合したことで、インライン アーキテクチャになったという意見もありますが、それは見当違いです。
統合は限られた電力の最適化をもたらしつつ、コンポーネントの価格を下げるかもしれませんが、CPU に統合された FEC のような固定機能ルックアサイド アクセラレータは、依然として PCIe デバイスとして機能し、DPDK BBDEV を通してアクセスされます。実質的な効果として、固定機能ルックアサイド アクセラレータが個別のコンポーネントであろうと、CPU に統合されていようと、同じ非効率性が存在します。
実際、ルックアサイド アクセラレータを統合すると、特定の CPU Stock Keeping Unit (SKU) の管理、機能の優先順位の調整、CPU 費用の増加など、新たな問題が発生します。
固定機能アクセラレータは本質的にクラウド ネイティブではない
クラウド コンピューティングの重要な原則は、インフラ リソースをアプリケーション間で共有することで、利用率を高め、より優れた規模の経済を実現することです。
固定機能アクセラレータ (FPGA ベース、低密度パリティ検査 (LDPC)、SoC ベースの L1 High-PHY など) は専用です。固定機能アクセラレータが 5G vRAN で使用されていない場合、それは他のアプリケーションで使用されない無駄なリソースとなります。
一般的な 5G ネットワークの平均利用率は 50% 未満です。つまり、固定機能のルックアサイド アクセラレータは、50% 以上の時間使用されることなく、クラウドに放置されることになります。一方、GPU のような汎用的でプログラム可能なアクセラレータは、大規模言語モデル (LLM) の学習や推論、コンピューター ビジョン、分析など、他のアプリケーションに再利用することができます。Data Plane
Development Kit Baseband Device (DPDK BBDEV) は、ルックアサイド アクセラレーションで一般的に使用されているアプリケーション プログラミング インターフェイス (API) です。クラウドネイティブな展開には適していません。DPDK には、高性能なネットワーク内アプライアンスのために設計された、以下のような多くの構成要素があります:
- 巨大なページ テーブル
- 事前に割り当てられたバッファ
- ピン止めされたメモリ
- Single-Root Input/Output Virtualization (SR-IOV)
- キュー中心のエンキュー-デキュー操作
ただし、これらの機能は、基盤となるハードウェアとの強い親和性を生み出し、真のクラウドネイティブな方法でシームレスな移植性とワークロードの移動を可能にするものではありません。
固定機能アクセラレーターは拡張性に欠ける
FEC LDPC、離散フーリエ変換 (DFT)、逆離散フーリエ変換 (iDFT)、その他の選択されたベースバンド レイヤー 1 機能のような固定機能アクセラレータの大きな欠点は、ある構成やユース ケースには適切なサイズかもしれませんが、別の構成には最適ではないということです。
FEC LDPC を例にしてみましょう。4T4R アンテナ、DDDSUUDDDD チャネル構成 (D: ダウンリンク、U: アップリンク、S: スペシャル)、4 DL/2 UL レイヤーを持つ典型的な 5G 周波数範囲1 (FR1) サブ 6 GHz システムでは、LDPC デコーダーは UL スロットの物理アップリンク共有チャネル (PUSCH) ワークロードの約 25 %を構成する場合があります。
他の構成は変えずに、システムの寸法を 4T4R から 64T64R のアンテナ構成 (マッシブ MIMO) に拡張する場合、PUSCH パイプラインの LDPC デコーダの計算負荷は、それに比例して増加しないことが判明しました。実際、この高次元システムでは、LDPC はアップリンク全体のワークロードの約 10% を占めているに過ぎません。
なぜこのようなことが起こるのでしょうか? それは、LDPC デコーダーの複雑さがレイヤー数に対して線形にしか拡大しないのに対し、チャネル推定や検出などの他のアルゴリズムは超線形に拡大するからです。このため、これらの機能を固定機能アクセラレーション ロジックに実装した場合、リソースの使用率や消費電力の観点から、最適とは言えない設計になりやすいのです。
固定機能アクセラレーターは敏捷性に欠ける
固定機能アクセラレータは、仕様の特定のリリース向けに設計されているため、3GPP のリリースに合わせて (例えば新機能で) 進化させることが困難です。固定機能アクセラレータ上で実行される複雑なアルゴリズムのアップグレードは困難で (特にハードウェアで実装された場合)、時間の経過に伴い改善が抑制されます。また、ハードウェアのバグ修正は解決に問題があり、多くの場合、費用のかかる交換が唯一の解決策となります。
要約すると、固定機能のルックアサイド アクセラレーションには、性能と遅延への影響、エネルギー効率の低下、プログラム可能性と拡張性の欠如といった欠点があり、これらの問題は、通信事業者の設備投資と運用コストの増加に直結するのです。
次に、プログラム可能性とインライン アクセラレーションの原則を活用することで、先に取り上げた問題の多くに対処する、NVIDIA による別のアプローチについて説明します。このソリューションは、業界をリードする vRAN への道を切り拓きます。
NVIDIA Aerial: vRAN のためのプログラム可能な GPU ベースのインライン アクセラレーション
NVIDIA は、プログラム可能な GPU への完全な L1オフロードのためにインライン アーキテクチャを使用するよく考えられたアーキテクチャのアプローチを取りました。このアーキテクチャでは、Bluefield DPU を使用し、データ パス内の CPU を使用せずに、すべてのフロントホール拡張共通公衆無線インターフェイス (eCPRI) のデータ トラフィックを GPU に取り込みます。
なぜ GPU なのか? を問うのは当然です。 5G PHY の信号処理要件は、集中的な行列演算によって複雑化され、計算上困難なものです。GPU アーキテクチャの大規模な並列性は、このクラスのワークロードをサポートする適切なハードウェア リソースをもたらします。
開発者の観点から見ると、GPU は、世界で最も商業的に成功した並列プログラミング フレームワークである CUDA を使用してプログラムされています。このため、計画、設計、開発、最適化、テスト、保守などを含むソフトウェア ライフサイクル管理のための成熟したツールや広範なライブラリを使用することができ、あなたの作業がよりシンプルになります。このことは、計算が複雑な AI や機械学習の分野で GPU が広く採用されていることからも証明されています。
2 つ目の疑問は、なぜインラインなのか? ということです。インライン アーキテクチャは、CPU とのやりとりなしに、vRAN L1 処理を GPU に完全にオフロードします。オフロードのためのインターフェイスは、Small Cell Forum (SCF) で開発された業界標準の Functional Application Platform Interface (FAPI) です。完全なオフロードにより、ホスト PCIe インターフェイスを介した CPU とアクセラレータ間のルックアサイド モデルによる複雑で非効率なピンポン効果も回避され、先に説明した性能向上と遅延軽減が実現します。
NVIDIA Aerial は、完全にプログラム可能で、クラウドネイティブで、AI に対応し、高性能なエンドツーエンドの L1 High-PHY (7.2-x 分割) インライン アクセラレーションを可能にするもので、2 つの基本原則に基づいて構築されています
- アクセラレーテッド コンピューティング
- 高速 I/O
アクセラレーテッド コンピューティングは、GPU アクセラレーション 5G L1 信号処理パイプラインを提供するソフトウェア スタックであるコンポーネントの CUDA baseband (cuBB) を通じて実現されます。cuBB は、すべての PHY レイヤーの処理を高性能 GPU メモリ内に保持することで、これまでにないスループットと効率性を実現します。cuBB には、NVIDIA GPU 向けに高度に最適化された 5G L1 High-PHY アクセラレーション ライブラリ cuPHY が含まれており、GPU の巨大な計算能力と高度な並列性を利用することで、比類のない拡張性を提供します。
高速 I/O は、NVIDIA DOCA GPUNetIO モジュールを通じて実現され、GPU メモリと GPUDirect 対応 NVIDIA ConnectX SmartNIC 間で直接パケットを交換することで、最適化された I/O とパケット処理を提供します。高速 I/O 処理とダイレクト メモリ アクセス (DMA) 技術を有効にすることは、インライン アクセラレーションの可能性を最大限に引き出すために不可欠です。
この目標に向けて、NVIDIA Aerial プラットフォームは、NVIDIA DOCA GPUNetIO ライブラリで実装された GPU 中心のアプローチを採用しています。このアプローチでは、NVIDIA GPU は、GPUDirect Async Kernel-Initiated Network (GDAKIN) 通信を使用して NVIDIA SmartNIC と直接やりとりし、CPU の介入なしにネットワークの送受信操作を調整するために NIC レジスタを設定および更新します。詳細については、「NVIDIA DOCA GPUNetIO によるインライン GPU パケット処理」を参照してください。
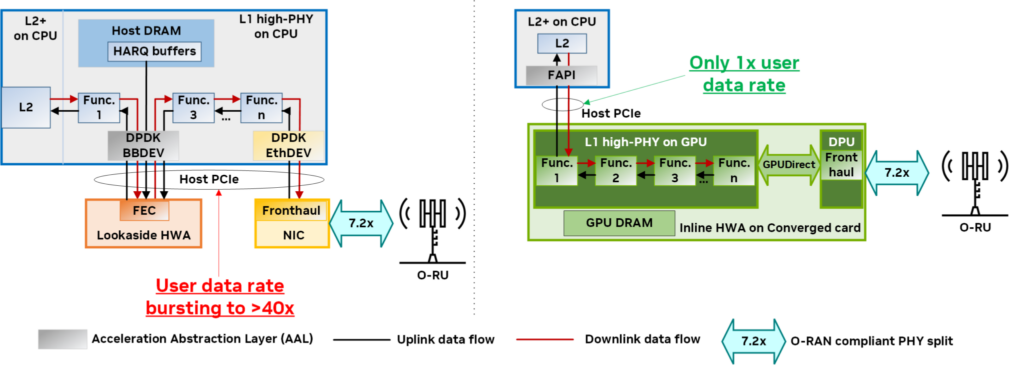
図 4 は、NVIDIA Aerial を使用した GPU ベースのインライン アクセラレー ション実装と、一般的な固定機能ハードウェア アクセラレータ (HWA) ベースのルックアサイド アクセラレーションとの間で PHY レイヤーのアーキテクチャを比較しています。右側では、NVIDIA Aerial プラットフォームは、CPU のステージング コピーやホスト PCIe 帯域幅のスロットルを必要とすることなく、L2 から L1、そしてフロントホールへのすべてで高速で効率的、かつ合理的なデータ フローを提供します。
- L2 と L1 間のより高いレベルのアクセラレーション抽象化レイヤ (AAL) (つまり FAPI)
- GPU と DPU の統合アーキテクチャ
- NVIDIA DOCA GPUNetIO および GPUDirect 技術によるインターコネクト
L1 処理パイプライン全体と対応するデータは、同じコンバージド カード上の GPU カーネルとDynamic Random-Access Memory (DRAM) 内に含まれているため、NVIDIA Aerial は、従来のルックアサイド アーキテクチャ (左) とは異なり、L2+ (例えば、ホスト DRAM やホスト PCIe) で重要な共有リソースを消費しません。
より少ない CPU コア消費と、L1 ワークロード全体の処理における高度な GPU 並列性により、NVIDIA Aerial プラットフォームは、比類のない性能、拡張性、敏捷性、プログラム可能性、およびエネルギー効率で、より少ない設備投資と運用コストのソリューションを提供します。
主要な要件に対応する NVIDIA Aerial
表 1 は、5G vRAN の主な要件の一覧で、これらの要件を満たすための固定機能アクセラレータを備えたルックアサイド アーキテクチャの制限、およびこれらの欠点に対処するための GPU プログラマブル アクセラレータを備えたインライン アーキテクチャの利点を示しています。
| 要件 | 固定機能ルックアサイド アーキテクチャ | GPU プログラマブル インライン アーキテクチャ |
| 高性能と低遅延 | PCIe 上で複数のリクエストとレスポンスが発生するため、CPU 消費量が増加し、消費電力 1 ワット当たりの性能と費用当たりの性能が悪くなる。ルックアサイド リクエストのバッチ処理とキューイングにより、L1 処理の遅延が高くなる。 | L2 ↔ L1 ↔ FH の処理パイプラインを合理化し、PCIe 上でトランザクションが行ったり来たりしないため、消費電力 1 ワット当たりの性能と費用当たりの性能が向上。L1 実行時にバッファリング/キューイングがないため、L1処理の遅延が最適化されます。 |
| クラウド エコノミクス | 再利用不可:「固定」された機能のみを実行し、クラウド インフラ内の他のアプリケーションと共有できない。 | 完全にプログラム可能で汎用的なため、リソースの利用率が高い。 |
| アプリケーションの移植性 | DPDK BBDEV: ハードウェアとの親和性が高いため、移植は容易ではない。 | FAPI: L2 と L1 間のより高いレベルの抽象化による、より高い移植性。 |
| 拡張性 | 特定のシステム構成に最適化された設計。 | 完全にプログラム可能で、様々なシステム構成に対応する拡張性。 |
| 敏捷性 | プログラム可能ではなく、設計サイクルが長く、進化する規格やアルゴリズムに対応したアップデートが難しい。 | 完全にプログラム可能でソフトウェア デファインドが可能なため、進化する規格や新しいアルゴリズムに対応したアップデートが容易。 |
まとめ
この記事では、固定機能アクセラレータとルックアサイド処理モデルの非効率性に注目しました。ルックアサイド モデルが性能とエネルギー効率にどのような影響を与えるか、また拡張性に関する多くの課題をご紹介しました。
プログラム可能なアクセラレータを備えたインライン処理モデルは、固定機能ルックアサイド アクセラレーション モデルの技術的ボトルネックに対処し、さまざまな RAN 構成にわたって高い性能、エネルギー効率、拡張性を提供します。
NVIDIA Aerial は、高性能、ソフトウェア定義、COTS ベース、クラウドネイティブ、AI 対応という、新たな vRAN の主要な理念を提供する唯一の商用プラットフォームです。GPU プログラミング可能なインライン処理モデルと完全な L1 オフロードを実装し、O-RAN 標準に完全に準拠したソフトウェア アーキテクチャで、幅広い RAN 構成とユース ケースに効率的なパフォーマンスを提供します。
RAN インフラを刷新し、効率的、高性能、拡張性、敏捷性、クラウドネイティブ、完全ソフトウェア デファインド、AI 対応の vRAN の実現に協力していただける方を、NVIDIA は歓迎いたします。
翻訳に関する免責事項
この記事は、「Building Software-Defined, High-Performance, and Efficient vRAN Requires Programmable Inline Acceleration」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。