
Note: As of January 6, 2025, VILA is now part of the Cosmos Nemotron VLM family.
NVIDIA is proud to announce the release of NVIDIA Cosmos Nemotron, a family of state-of-the-art vision language models (VLMs) designed to query and summarize images and videos from physical or virtual environments. Cosmos Nemotron builds upon NVIDIA’s groundbreaking visual understanding research including VILA, NVILA, NVLM and more. This new model family represents a significant advancement in our multimodal AI capabilities and the incorporation of innovations such as multi-image analysis, video understanding, spatial-temporal reasoning , in-context learning, and zero/few-shot tasks.
In this post, we describe how Cosmos Nemotron performs against other models to deliver edge AI 2.0.
Initial versions of edge AI involved deploying compressed AI models onto edge devices. This phase, known as Edge AI 1.0, focused on task-specific models. The challenge with this approach lay in the need to train different models with different datasets, where negative samples are hard to collect and outlier situations are difficult to handle. This process was time-consuming and highlighted the need for more adaptable AI solutions with better generalization.
Edge AI 2.0: The rise of generative AI
Edge AI 2.0 marks a shift towards enhanced generalization, powered by foundational visual language models (VLMs).
VLMs such as Cosmos Nemotron demonstrate incredible versatility, understanding complex instructions and swiftly adapting to new scenarios. This flexibility positions them as vital tools in a wide array of applications. They can optimize decision-making in self-driving vehicles, create personalized interactions within IoT and AIoT environments, event detection, and enhance smart home experiences.
The core strength of VLMs lies in their world knowledge acquired during language pre-training and the ability for users to query them with natural language. This leads to dynamic processing abilities for AI-powered smart cameras without needing to hardcode bespoke vision pipelines.
VLM on the edge: Cosmos Nemotron and NVIDIA Jetson Orin
To accomplish edge AI 2.0, a VLM must be high-performance and easy to deploy. Cosmos Nemotron achieves both by using the following:
- A carefully designed training pipeline with a high-quality data mixture
- AWQ 4bit quantization with negligible accuracy loss

Cosmos Nemotron is a visual language model that brings visual information into LLMs. The Cosmos Nemotron model consists of a visual encoder, LLM, and projector that bridges the embeddings from the two modalities. To leverage powerful LLMs, Cosmos Nemotron uses a visual encoder to encode images or video as visual tokens and then input these visual tokens into LLM as if they are a foreign language. This design can handle an arbitrary number of interleaved image-text inputs.
Cosmos Nemotron’s success stems from its enhanced pretraining recipe. We observed three major findings after ablated study on visual language model pretraining choices:
- Freezing LLMs during pre-training can achieve decent zero-shot performance but lacks in-context learning capability, which requires unfreezing the LLM.
- Interleaved pre-training data is beneficial, whereas image-text pairs alone are not optimal.
- Re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks but also boosts VLM task accuracy.
We observed that the pre-training process unlocked several interesting capabilities for the model:
- Multi-image reasoning, despite the model only seeing single image-text pairs during SFT (supervised fine tuning)
- Stronger in-context learning capabilities
- Enhanced world knowledge
For more information, see the On Pre-training for Visual Language Models and Efficient Frontier Visual Language Models paper, and the NVLabs/cosmos-nemotron GitHub repo.
NVIDIA Jetson Orin offers unparalleled AI compute, large unified memory, and comprehensive AI software stacks, making it the perfect platform to deploy Cosmos Nemotron on energy-efficiency edge devices. Jetson Orin is capable of fast-inferencing any generative AI models powered by the transformer architecture, leading the edge performance on MLPerf.
AWQ quantization
To deploy Cosmos Nemotron on Jetson Orin, we integrated Activation-aware Weight Quantization (AWQ) to enable 4-bit quantization. AWQ enables us to quantize Cosmos Nemotron to 4-bit precision with negligible accuracy loss, paving the way for VLMs to transform edge computing while upholding performance standards.
Despite advancements like AWQ, deploying large language and visual models on edge devices remains a complex task. Four-bit weights lack byte alignment and demand specialized computation for optimal efficiency.
TinyChat is an efficient inference framework designed specifically for LLMs and VLMs on edge devices. TinyChat’s adaptable nature enables it to run on various hardware platforms, from NVIDIA RTX 4070 laptop GPUs to NVIDIA Jetson Orin, attracting significant interest from the open-source community.
Now, TinyChat expands its reach to support VILA, enabling the vital understanding and reasoning of visual data. TinyChat delivers exceptional efficiency and flexibility in combining textual and visual processing, empowering edge devices to execute cutting-edge, multi-modal tasks.
Benchmarks
The following tables show the benchmark results for VILA 1.5-3B. It does great for both image QA and video QA benchmarks at its size. You can also see that AWQ 4-bit quantization doesn’t lose accuracy and by integrating with Scaling on Scales (S2), it can perceive images with higher resolutions and further boost the performance.
| Model | Precision | VQA-V2 | VizWiz | GQA | VQA – T | ScienceQA – I | MME | SEED- I | MMMU val | MMMU test |
| VILA-1.5-3B-S2 | fp16 | 79.8 | 61.3 | 61.4 | 63.4 | 69.6 | 1432 | 66.5 | 33.1 | 31.3 |
| VILA1.5-3B | fp16 | 80.4 | 53.5 | 61.5 | 60.4 | 69 | 1442 | 67.9 | 33.3 | 30.8 |
| VILA1.5-3B | int4 | 80 | 53.8 | 61.1 | 60.4 | 67.8 | 1437 | 66.6 | 32.7 | 31.1 |
| Model | ActivityNet | MSVD | MSR-VTT | TGIF | Perception Test |
| VILA1.5-3B | 50.2 | 76.6 | 57.5 | 51.7 | 39.3 |
Deploying on Jetson Orin and NVIDIA RTX
With the increasing prevalence of cameras and vision systems being used in real-world environments, inferencing Cosmos Nemotron on edge devices is an important task. Depending on the model size, you can choose from the seven Jetson Orin modules ranging from entry AI to high-performance. This gives you the ultimate flexibility to build generative AI applications for smart home devices, medical instruments, autonomous robots, and video analytics that users can reconfigure and query dynamically.
Figure 3 shows the end-to-end multimodal pipeline performance for running Cosmos Nemotron on Jetson AGX Orin and Jetson Orin Nano, with both achieving interactive rates on video streams.
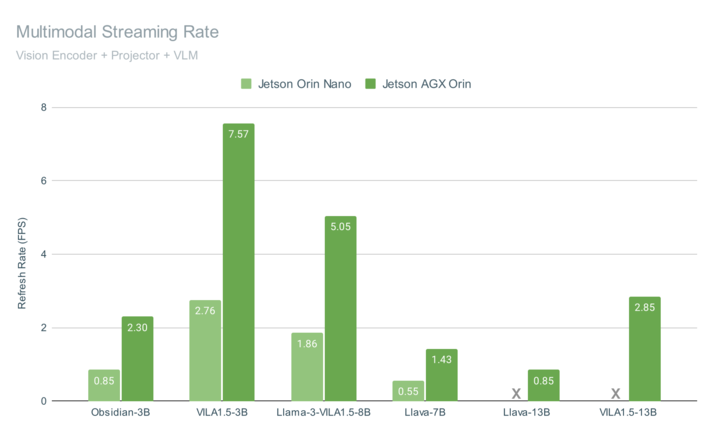
These benchmarks include the overall time to query a frame, including vision encoding (with CLIP or SigLIP), multimodal projection, assembly of the chat embeddings, and generation of the language model output with 4-bit quantization. The VILA-1.5 models include a novel adaptation that reduces the number of tokens used to represent each image embedding from 729 down to 196 tokens, which boosts performance while retaining accuracy under increased spatial resolution in the vision encoder.
This highly optimized VLM pipeline is open source and integrates advanced features such as multimodal RAG with one-shot image tagging, along with efficient re-use of the image embeddings for other vision-related tasks across the system.
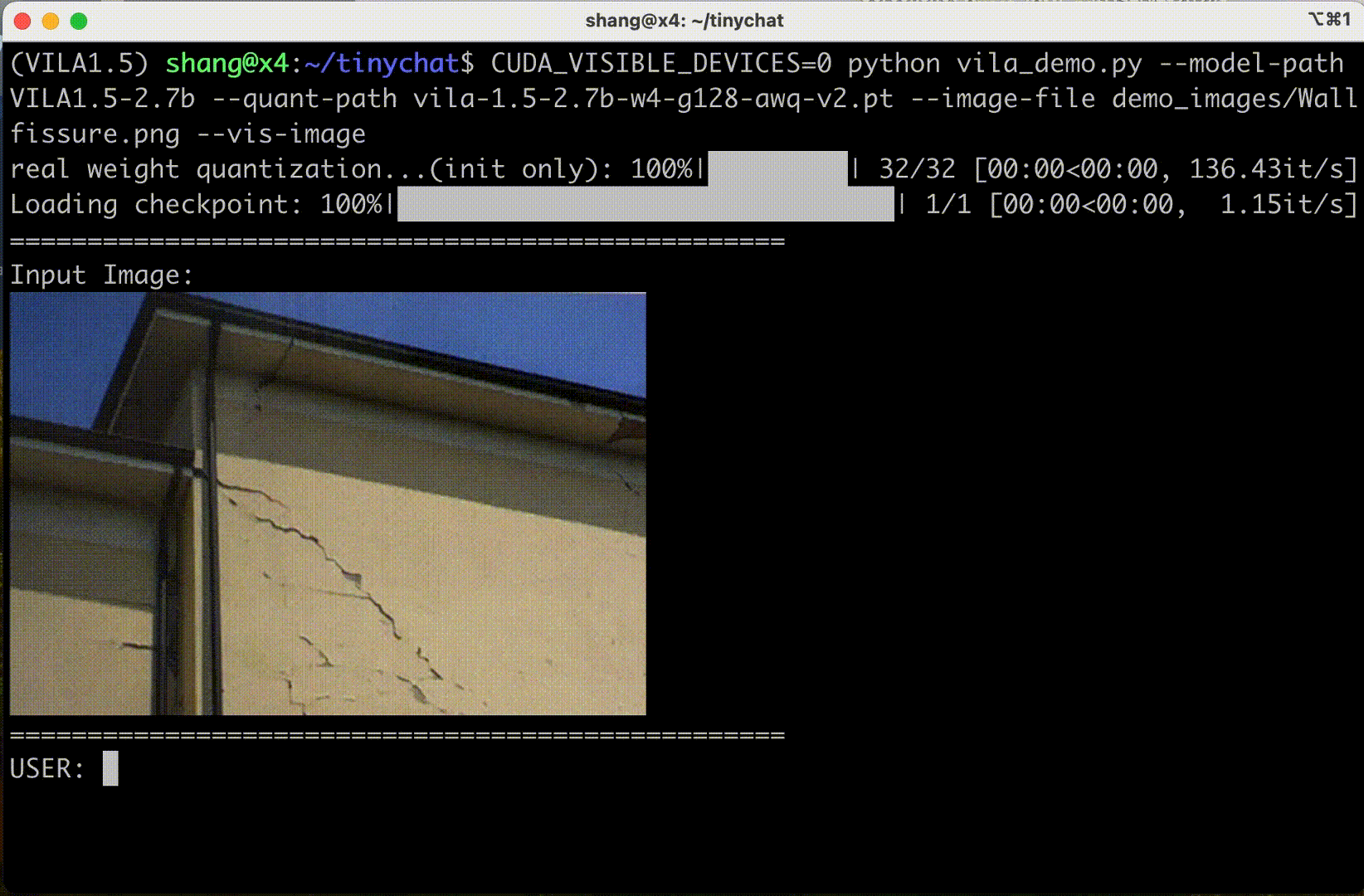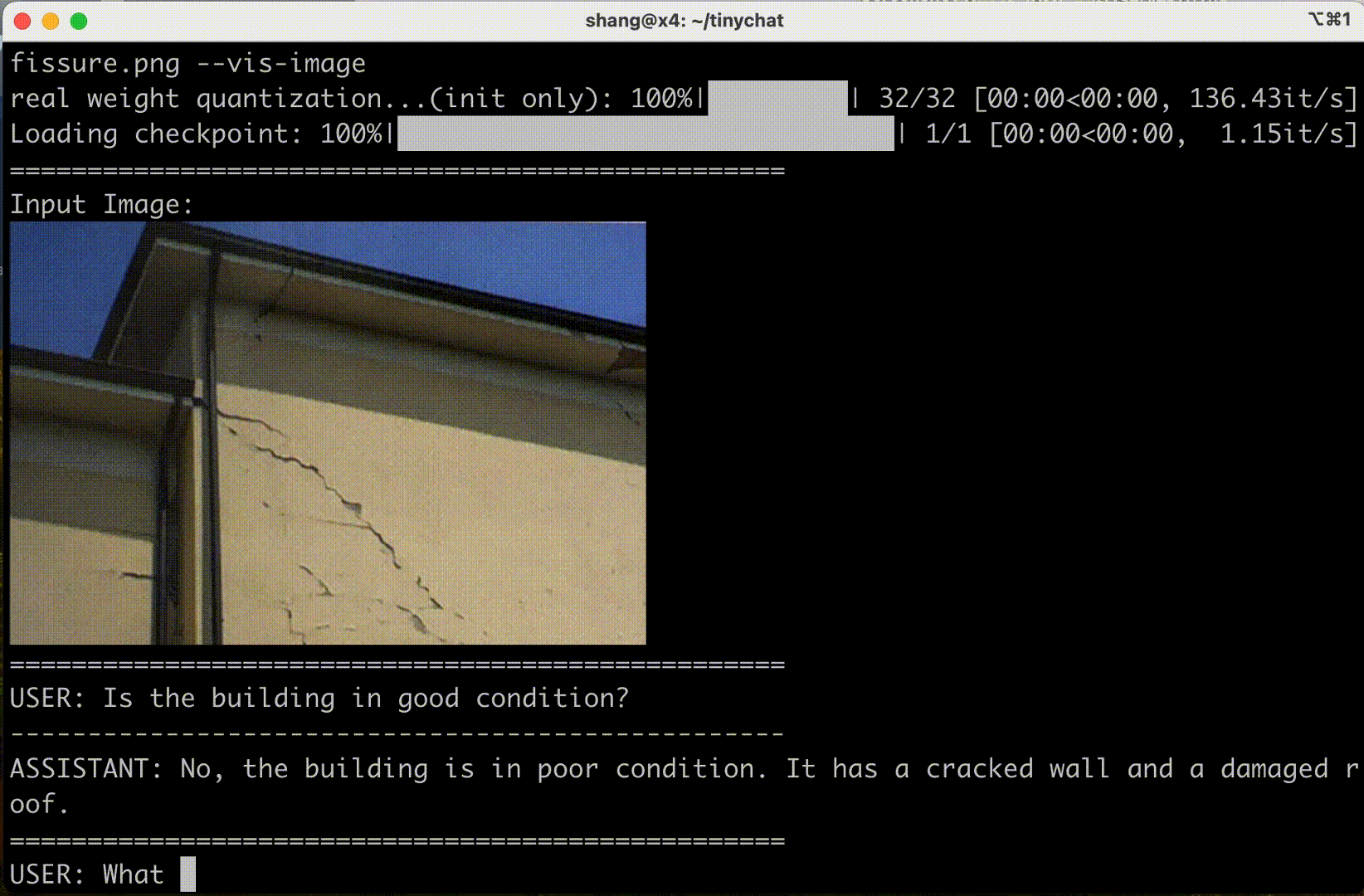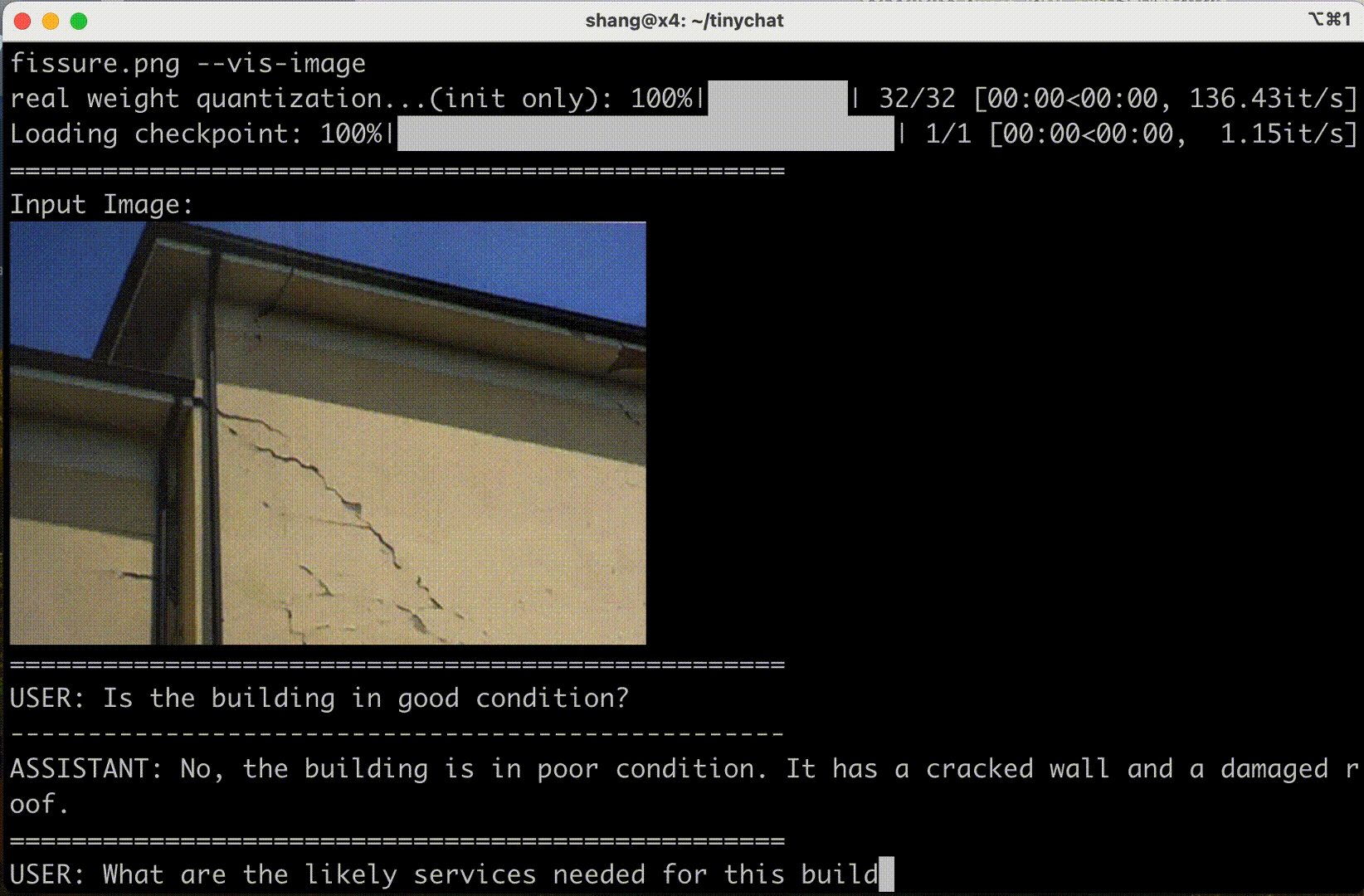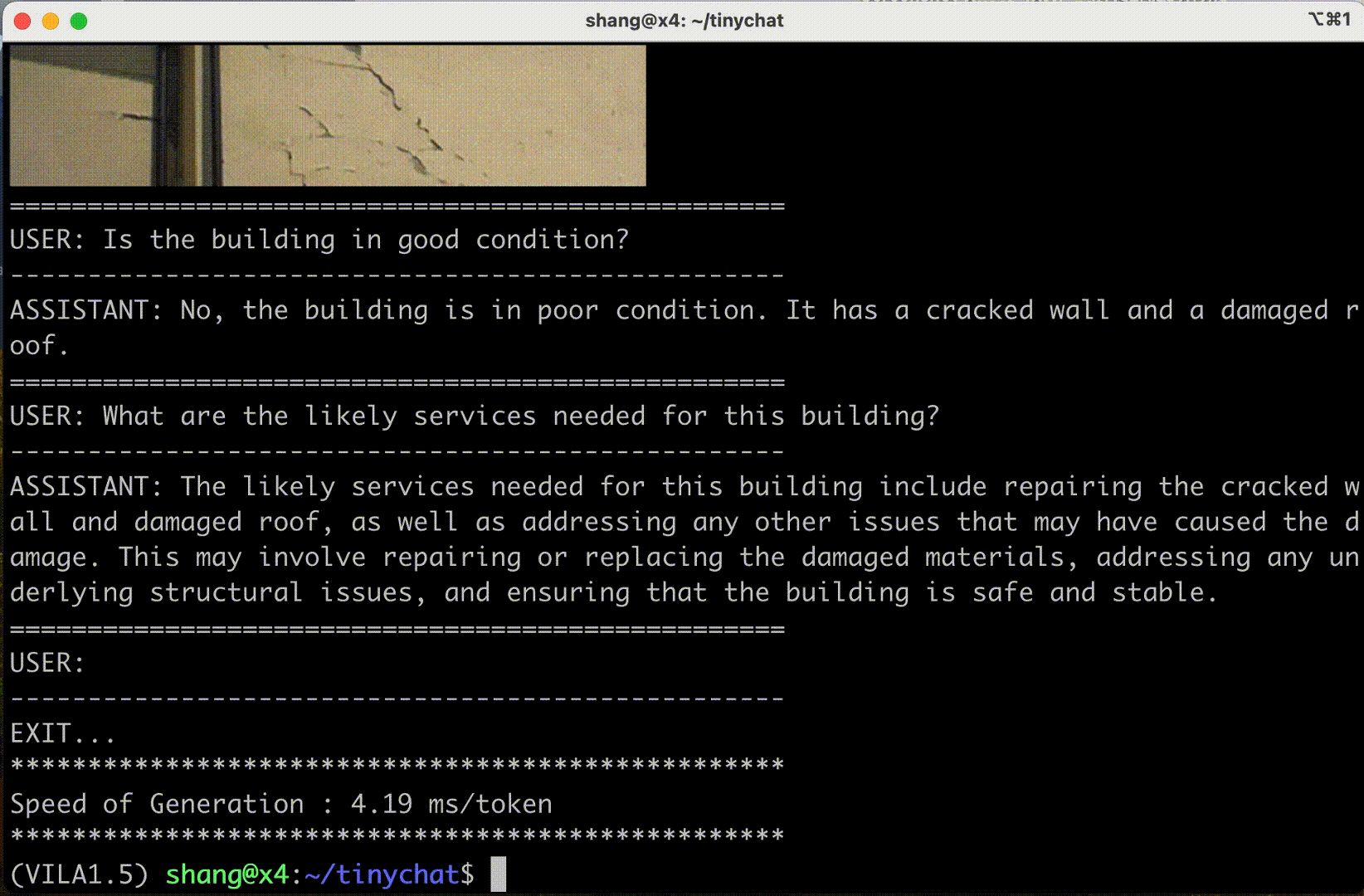
Consumer GPU experiences
Cosmos Nemotron can also be deployed in consumer GPUs such as NVIDIA RTX on laptops and PC workstations to enhance user productivity and interaction experiences.

Multi-image reasoning
TinyChat’s newest release uses Cosmos Nemotron’s impressive multi-image reasoning capabilities, enabling you to upload multiple images simultaneously for enhanced interactions. This unlocks exciting possibilities.
Figure 6 shows that Cosmo Nemotron can understand the content and order of image sequences, opening new avenues for creative applications.
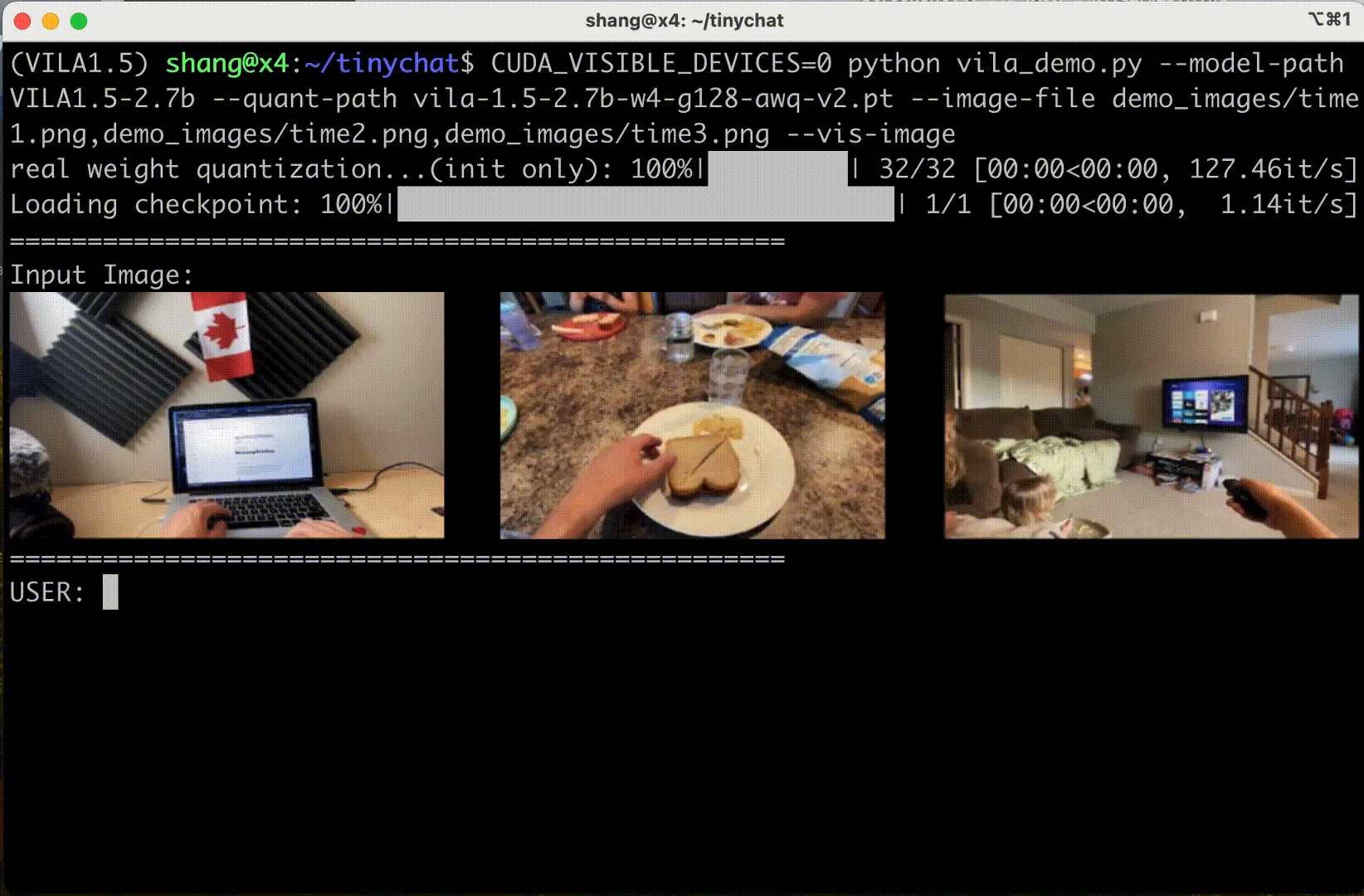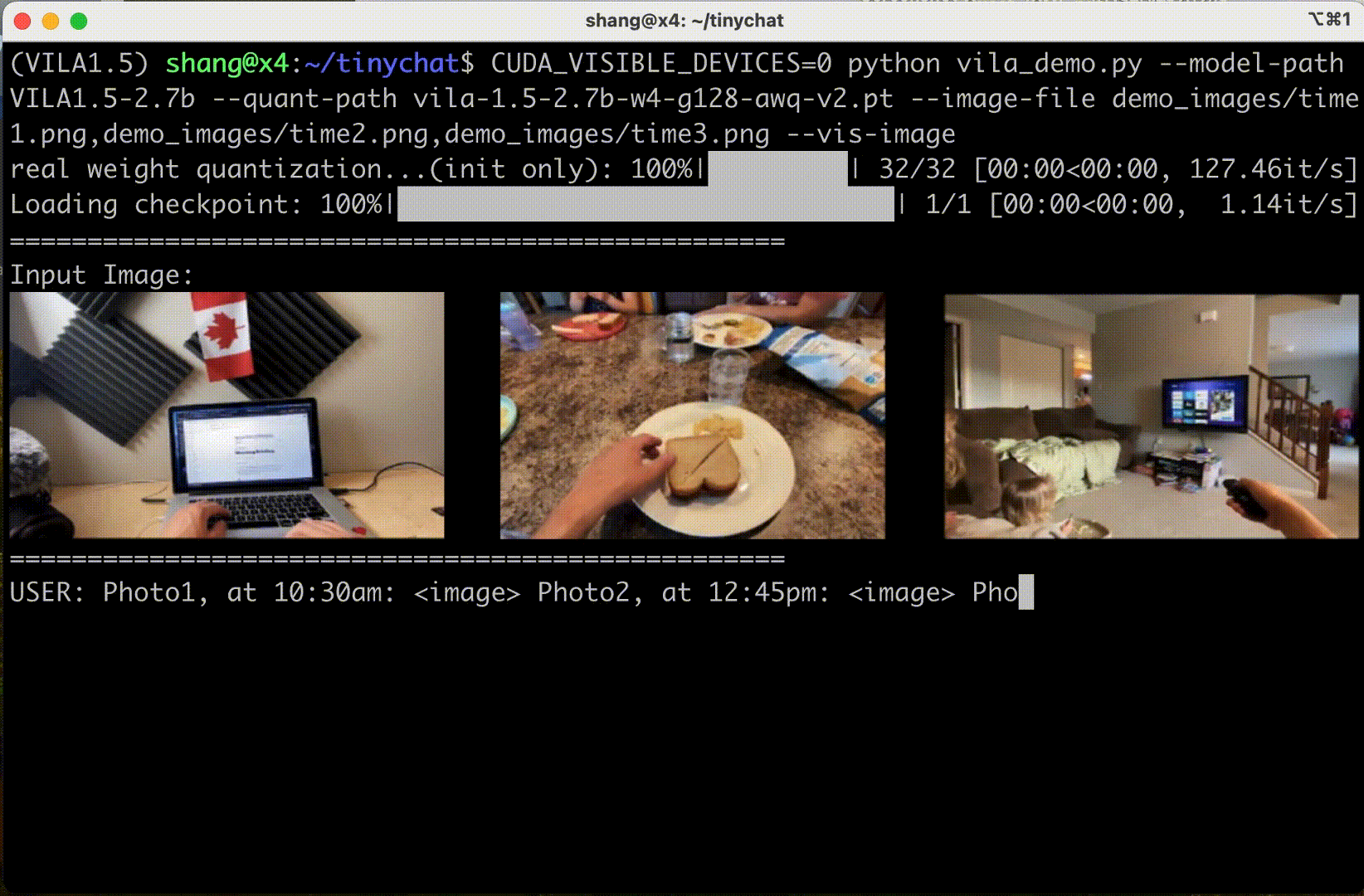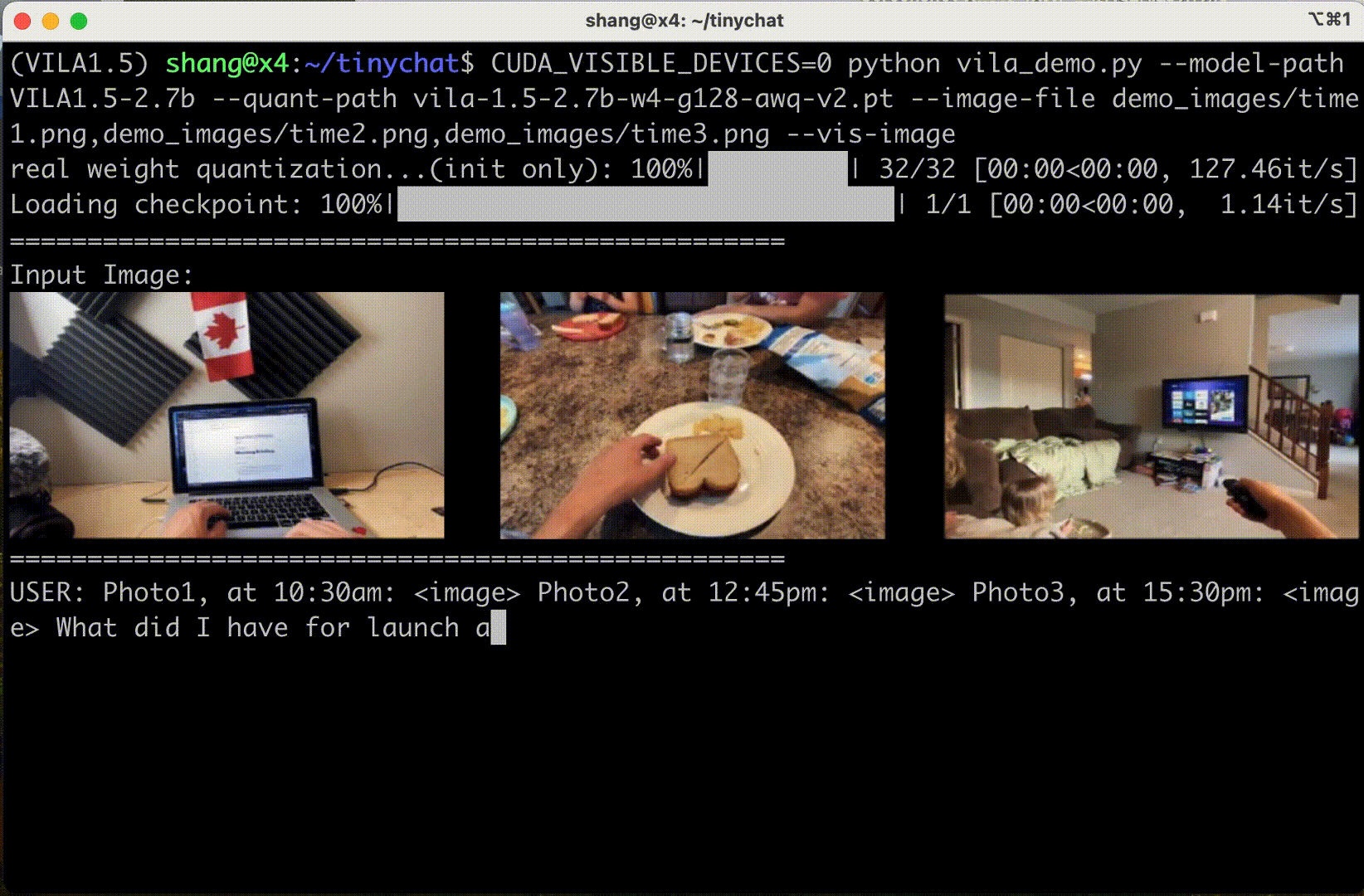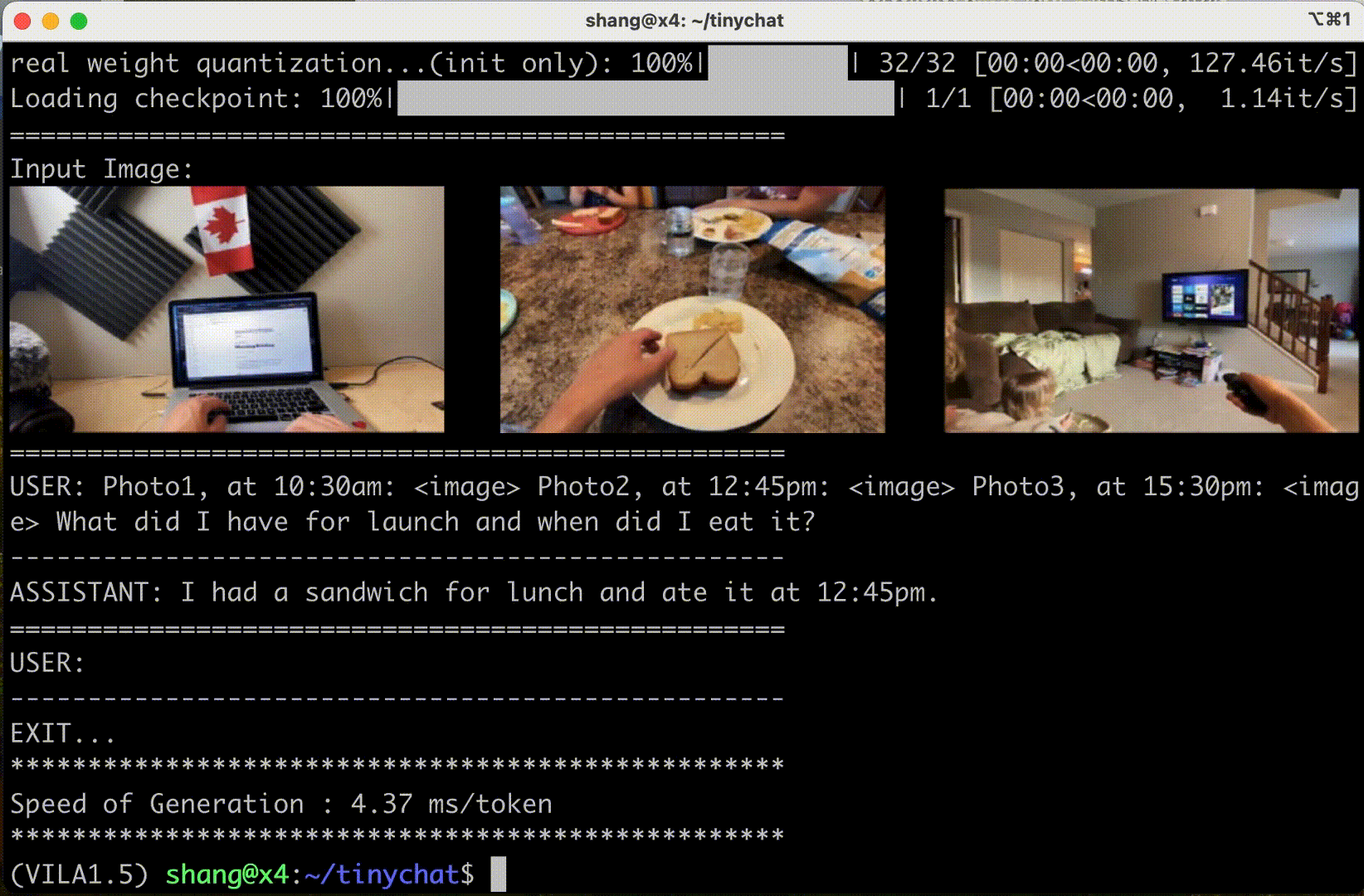
In-context learning
Cosmos Nemotron also demonstrates remarkable in-context learning abilities. Without the need for explicit system prompts, Cosmos Nemotron can seamlessly infer patterns from previous image-text pairs to generate relevant text for new image inputs.
In Figure 7, Cosmos Nemotron successfully recognizes the NVIDIA logo and, mirroring the style of previous examples, outputs NVIDIA’s most famous products.

Get started with Cosmos Nemotron
We plan to continue to innovate on Cosmos Nemotron, including extending context length, increasing resolution, and curating a better dataset for vision and language alignment.
For more information about this family of models, see the following resources.
- To get started with Cosmos Nemotron, see the /NVLabs/VILA GitHub repo.
- For a multimodal web UI where you can speak to Cosmos Nemotron with ASR/TTS running on Jetson Orin, see the llamaspeak agent tutorial.
- For streaming Cosmos Nemotron on a camera or video feed, see the Live Llava agent tutorial.
For more ideas about generative AI at the edge, see the Jetson AI Lab, especially the following videos.
