Across several verticals, question answering (QA) is one of the fastest ways to deliver business value using conversational AI. Informally, QA is the task of mapping a user query to an answer from a given context. This open-ended definition is best understood through an example:
Question: Where are the headquarters of NVIDIA?
Context: “NVIDIA Corporation (en-VID-ee-\u0259) is an American multinational technology company incorporated in Delaware and based in Santa Clara, California. It designs graphics processing units (GPUs) for the gaming and professional markets, as well as system on a chip units (SoCs) for the mobile computing and automotive market. Its primary GPU product line, labeled \”GeForce\”, is in direct competition with Advanced Micro Devices’ (AMD) \”Radeon\” products. NVIDIA expanded its presence in the gaming industry with its handheld Shield Portable, Shield Tablet, and Shield Android TV and its cloud gaming service GeForce Now.
In addition to GPU manufacturing, NVIDIA provides parallel processing capabilities to researchers and scientists that allow them to efficiently run high-performance applications. They are deployed in supercomputing sites around the world. More recently, it has moved into the mobile computing market, where it produces Tegra mobile processors for smartphones and tablets as well as vehicle navigation and entertainment systems. In addition to AMD, its competitors include Intel and Qualcomm.”
Answer: Santa Clara, California
The example is easy to answer with a deep learning (DL) model. The context, pulled from the Wikipedia extract, is used by the DL model to find the span that corresponds to the answer. There are a wide array of open datasets and models to solve this simple task, the most frequently used being the Stanford Question Answering Dataset (SQuAD). Oftentimes, this is called open-domain QA.
NVIDIA NeMo already provides a great example of applying a state-of-the-art QA model to this task. However, it does assume that you already have the context. There is a lot of great R&D being done on this “first phase” of collecting the contexts for a given question in the form of DPR (dense-passage retrieval). However, what if you don’t have a dataset that looks like the training material on which these open-domain IR models are trained (namely, Wikipedia)? Instead, what if you just have a collection of facts that you want to answer questions about?
In this post, we cover an alternative approach towards QA that relies on a knowledge graph rather than contextual text to answer a question. Using a neural machine translation model trained to convert a question to a graph query, we can effectively access rich features stored within a knowledge graph.
Tackling knowledge graphs with MK-SQuIT and NeMo
Knowledge graphs are convenient structures that can store vast collections of connected data in the form of facts. They are flexible and dense structures that house node attributes as well as inter-relational features. A popular open knowledge graph is Wikidata, boosting close to 100M items.
The caveat, however, is that searching through rich representations of data becomes increasingly complex. That raises the barrier of entry and make these databases inaccessible to lay users. Querying them requires using SPARQL or other graph-oriented query languages, which are far removed from the natural way users would like to query for facts. This is doubly so if users expect to query with natural language, as they would with the question, “Where are the headquarters of NVIDIA?”.
Thanks to advancements in neural machine translation models, we can consider this problem in the form of translation between natural language and query language. A model that can learn this translation then enables open QA over a knowledge graph of facts. This approach is often applied for the Text2SQL problem, where a model is trained to translate from text to SQL. Because we are dealing with knowledge graphs and the SPARQL query language, the problem you are solving in this post is Text2SPARQL.
Generating synthetic Text2Sparql data
Current state-of-the-art query translation models require thousands of hand-labeled examples from going from a natural language to a query language. This can be costly and take weeks or months to accomplish. Moreover, as the knowledge graph evolves with new content, the translation model requires additional hand-labeled examples, which slows down quick iterations in production. This challenge is what motivates many to move towards the open domain QA approach. However, if you can synthetically generate a dataset, then these problems disappear.
Introducing MK-SQuiT
To generate the dataset, why not automate as many components as possible, injecting semantic rules into the process to produce a high-quality dataset? In our recent preprint, we introduced MK-SQuIT (Synthesizing Questions using Iterative Template-filling). It is a (nearly) fully automated, open-source generation framework for creating synthetic English to SPARQL query pairs.
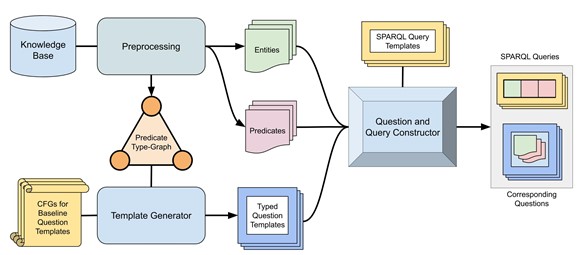
Our provided dataset generation library pulls entities and predicates from a given knowledge base in Resource Description Format (RDF) and assembles them into natural language questions. Simultaneously, a graph query is constructed using the semantics tied to the predicates in the knowledge base. We use the simple predicate-argument structure of interrogative sentence types to generate natural language questions paired with their respective SPARQL query.
This approach lends several key benefits:
- The synthetic dataset generation can provide large datasets with little human input.
- Generating datasets synthetically can guarantee certain standards of quality, variability, and query validity.
- Generated queries match the level of syntactic and semantic rigor of the source knowledge base.
- After setup, generation is extremely fast and can be run in a matter of minutes on a modern laptop.
We have provided a sample dataset generated from Wikidata consisting of 110K queries (100K training, 10K testing). However, our code is extensible to other natural languages and graph query languages allowing for use with most graph databases.
The following sections provide a more detailed explanation of the entire process. To reproduce the results shown in the example, you can download the Docker container from the NGC catalog, a GPU-optimized hub for AI software such as containers, pretrained models, and application frameworks, built to speed up your AI workflows. For more information, see the MK- MeetKai/MK-SQuIT GitHub repo.
Creating a dataset with MK-SQuIT
To begin, download the generation source code:
git clone https://github.com/MeetKai/MK-SQuIT.git cd MK-SQuIT
First, you must extract raw entity and property data from a database, such as Wikidata. An entity refers to a node and its metadata, and a property refers to relational attributes. These raw values are saved to JSON files as specific formats: *-5k.json for entities and *-props.json for properties.
# Set some variables in your terminal:
DATA_DIR="./data" # Set data path
OUT_DIR="./out" # Set output path
ENTITY_ID="*-5k.json" # Glob identifier for entity data -> {domain}-5k.json
PROPERTY_ID="*-props.json" # Glob identifier for property data -> {domain}-5k.json
PREPROCESSED_ENT_ID="*-5k-preprocessed.json" # Glob identifier for preprocessed property data
PREPROCESSED_PROP_ID="*-props-preprocessed.json" # Glob identifier for preprocessed property data
# Run a script for get requests that saves the JSON responses
python -m scripts.gather_wikidata --data-dir $DATA_DIR
Raw data must then be cleaned and annotated before being fed into the pipeline. Most importantly, this step converts property labels into part-of-speech tags to assist with coherent mapping within a template. For example, the property set in location would be labeled as VERB_NOUN allowing the pipeline to easily insert the property within the context of a sentence. A typing field is also added to each property in the format [domain] ->. Further information is included in the next section.
python -m scripts.preprocess --data-dir $DATA_DIR \ --ent-id $ENTITY_ID \ --prop-id $PROPERTY_ID
You should now have several files:
*-5k-preprocessed.jsonand*-props-preprocessed.json: Preprocessed entity and property valuespos-examples.txt: Samples of part-of-speech tags that are sorted by the number of occurrences within the data. This is an optional file used to help with template generation, if you were to write your own templates.
The unfilled typing field must now be annotated to include [domain] -> [type]. To understand how the type should be specified, we briefly cover its purpose. When you are considering how to link properties together, consider the types of properties or entities to which they would refer. For example, location of and location at are referring to a place. Build during and created at are referring to time. To a certain extent, these typing labels are subjective, but they allow the pipeline to string together much more coherent statements.
After the preprocessed property values have been labeled, you can aggregate their metadata into a type-list-autogenerated.json file. This is used for the pipeline and is the last requirement before generating the dataset.
python -m scripts.generate_type_list --data-dir $DATA_DIR --prop-id $PREPROCESSED_PROP_ID
At this point, you are ready to generate the dataset with the following files:
- Entity data:
*-5k-preprocessed.json - Property data:
*-props-preprocessed.json - Type metadata list:
type-list-autogenerated.json
Run the following command:
python -m mk_squit.generation.full_query_generator --data-dir $DATA_DIR \ --prop-id $PREPROCESSED_PROP_ID \ --ent-id $PREPROCESSED_ENT_ID \ --out-dir $OUT_DIR
You now have the generated dataset, with data like the following:
| english | sparql | unique hash
| What is the height of Getica's creator? | SELECT ?end WHERE { [ Getica ] wdt:P50 / wdt:P2048 ?end . } | 0ea54cd5187baf7239c8f2023ae33bb3001c5a49 |
We’d also like to note that the addition of domains, such as corporations, is not difficult. Raw data must be gathered, as in the example, and some care must be taken to annotate the types. The data can then be fed to the same scripts to easily repurpose the dataset.
Fine-tuning a Text2Sparql model with NeMo
The final step is to train an actual model to perform the translation task. Using NeMo, you can quickly fine-tune a baseline model with the added bonuses of being able to easily tune hyperparameters and effortlessly scale out to multiple GPUs.
For the example dataset, we’ve found that using a pretrained BART model to initialize the weights produces solid predictions. The syntax of the SPARQL queries is an extension of regular SPARQL. Some post-processing may be required, depending on the database used to fulfill the queries. In this case, you omit entity names from the training set because the size of the dataset would be, at minimum, the number of possible entities, which is potentially massive. As such, predicted queries contain entities in their natural language form rather than as an entity ID. Resolving entities is not difficult and we’ve have provided an example at the end of this section to do so.
For generation, you configure the model to use a greedy search, but we expect a well-configured beam search to perform better. Results are then passed through minor post-processing and evaluated on the BLEU and ROUGE metrics.
To train and evaluate the network locally, several shell scripts download and execute tutorial code from NeMo.
Clone the MK-SQuIT repository if you haven’t already:
git clone https://github.com/MeetKai/MK-SQuIT.git pip install -r requirements.txt cd MK-SQuIT/model
Install the latest version of NeMo and download the example scripts:
./setup.sh
Optionally, update the train and evaluation parameters inside this script and execute it to set environment variables:
./params.sh
Download and reformat example data, then train:
./train.sh
Generate predictions and scores:
./evaluate.sh
That’s it!
Here are some predictions from the model:
- Single-entity:
- Question: Who is the mother of the director of Pulp Fiction?
- Query:
?end WHERE { [ Pulp Fiction ] wdt:P5 / wdt:P25 ?end . }
- Multi-entity:
- Question: Is John Steinbeck the author of Green Eggs and Ham?
- Query:
ASK { BIND ( [ John Steinbeck ] as ?end ) . [ Green Eggs and Ham ] wdt:P50 ?end . }
- Count:
- Question: How many awards does the producer of Fast and Furious have?
- Query:
SELECT ( COUNT ( DISTINCT ?end ) as ?endcount ) WHERE { [ Fast and Furious ] wdt:P162 / wdt:P166 ?end . }
Here are some common metrics across the two test datasets, test-easy and test-hard:
| Dataset | BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | ROUGE-W | |-----------|---------|---------|---------|---------|---------| | test-easy | 0.98841 | 0.99581 | 0.99167 | 0.99581 | 0.71521 | | test-hard | 0.59669 | 0.78746 | 0.73099 | 0.78164 | 0.48497 |
BART performs nearly flawlessly on the easy test set. As expected, there is a dip in scores for the hard-set as the model is challenged with more complex logical requirements, noisy perturbations, and additional unseen slot domains. The key is to extend your dataset with real data that comes in when you have a Text2SPARQL system responding to real user queries.
To complete the demonstration, we cover entity resolution, a process where natural language entity names are converted to their WikiData IDs. This can be easily performed with a fuzzy text matcher, such as rapidfuzz. As an example, a utility class is included in the MK-SQuIT repo and can be used as follows:
# Python script
import requests
from mk_squit.utils.entity_resolver import EntityResolver
resolver = EntityResolver(data_dir="./data") # Load entity data
example_prediction = "SELECT ?end WHERE { [1,1,1-trifluoro-2-chloro-2-bromoethane] wdt:P31 ?end . }"
example_query = resolver.resolve(example_prediction)
# SELECT ?end WHERE { wd:Q32921 wdt:P31 ?end . }
url = "https://query.wikidata.org/sparql"
response = requests.get(url, params = {"format": "json", "query": example_query})
print(response.json())
You get back five results:
- http://www.wikidata.org/entity/Q11173 (chemical compound)
- http://www.wikidata.org/entity/Q12140 (medication)
- http://www.wikidata.org/entity/Q35456 (essential medicine)
- http://www.wikidata.org/entity/Q909194 (inhalational anaesthetic)
- http://www.wikidata.org/entity/Q72941151 (developmental toxicant)
This tells you that 1,1,1-trifluoro-2-chloro-2-bromoethane is the name of a chemical compound used in some medications. Keep in mind that not all queries return a result, as the data or properties may not exist within Wikidata. That’s it for the entire process!
Getting started
Getting started is easy. We have provided several ways of exploring this project and reproducing our results:
- Download the Text2Sparql NGC container.
- Install NeMo.
- Follow the notebook tutorial.
- Run the train and evaluation scripts.
To interactively explore ahttps://ngc.nvidia.com/catalog/containers/partners:mk-squit example dataset or walk through the MK-SQuIT pipeline, we recommend using the NGC container.
Conclusion
Synthetic natural languages to query datasets have much room for improvement, but we believe they have the potential to revolutionize the accessibility of knowledge graphs. We hope you’ve found this post helpful and perhaps even found some inspiration from it. Feel free to check out other things we work on at MeetKai, read more about us at our blog, or get started by downloading the container from the NGC catalog. You can also view the following resources:
