Enterprises across industries are leveraging natural language process (NLP) solutions—from chatbots to audio transcription—to improve customer engagement, increase employee productivity, and drive revenue growth.
NLP is one of the most challenging tasks for AI because it must understand the underlying context of text without explicit rules in human language. Building an AI-powered solution from start to finish can also be daunting. First, datasets must be curated and preprocessed. Next, models must be trained and tested for inference performance, and then deployed into usable, customer-facing applications.
At each step along the way, developers constantly face time-consuming challenges, such as building efficient pipelines, optimizing for the targeted hardware, and ensuring accuracy and stability while working within a project’s schedule and budget.
NVIDIA NGC
The NVIDIA NGC catalog is the hub of GPU-optimized AI/ML software that can be deployed across on-premises, cloud, edge, and hybrid environments. In addition to the monthly updated, performance-optimized, deep learning frameworks, NGC also offers state-of-the-art pretrained models and model scripts for various use cases, including NLP, text-to-speech, recommendation engines, and translations.
Google Cloud AI Platform
Google Cloud AI Platform (CAIP) is a fully managed, end-to-end machine learning platform. It provides managed services for training and prediction for hassle-free development with built-in enterprise security to help you get to production faster. CAIP does the heavy lifting so you can focus on your models.
This post provides step-by-step instructions to build a question answering (QA) service using NGC and NVIDIA A100-powered GCP instances. CAIP supports up to 16 cores for A100 GPUs. You can take advantage of the NGC deep learning framework containers, pretrained models, and TensorRT to quickly train and optimize models and then run the service to get answers with Triton Inference Server.
Build, optimize, and deploy the QA service
Through the following sections, you create a QA service with Bidirectional Encoder Representations from Transformers (BERT). BERT pretrains deep bidirectional representations of human language from unlabeled text and can be fine-tuned to any form of application by adding one additional output layer at the end of the neural network. Figure 1 shows the process of pretraining and fine-tuning.
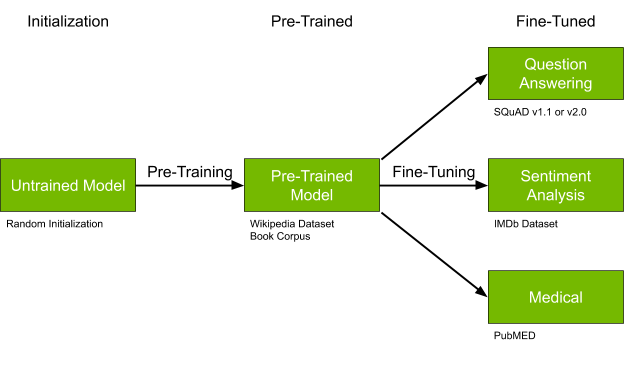
In this post, you fine-tune BERT for QA. Figure 2 shows a sample question-answer pair from Stanford Question Answering Dataset (SQuAD). When it’s fine-tuned and given a question and the context, the fine-tuned BERT model should be able to return an answer, highlighted in color. From there, you further optimize the fine-tuned BERT for better performance and finally deploy it for QA service.

Prepare the dataset and scripts
From scratch, BERT pretraining can take days or weeks, unless you have access to many GPUs. Thanks to NGC, you can download a pretrained BERT model created by NVIDIA. For this post, you use the Stanford Question Answering Dataset (SQuAD) to train the QA model.
Use the following commands to collect and organize the assets. You can either run these commands in a GCP Cloud Shell session to store assets in Google Cloud Storage or download locally and use the user interface to upload.
Download the pretrained BERT checkpoint and BERT configuration files from NGC:
$ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_pretraining_amp_lamb/versions/19.03.0/zip -O bert_tf_files.zip $ unzip bert_tf_files.zip -d bert_tf_pretraining_lamb_16n_v1
Download the SQuAD v1.1 dataset:
$ wget https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json $ wget https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json $ wget https://worksheets.codalab.org/rest/bundles/0xbcd57bee090b421c982906709c8c27e1/contents/blob/
Download the scripts from NGC:
$ wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/bert_gcaip/versions/v1.0/zip -O bert_gcaip_v1.0.zip
After you download the assets, organize the folder:
gtc-bert-demo (GCS directory) ├── checkpoint │ ├── bert_tf_pretraining_lamb_16n_v1 ├── output ├── squad │ ├── v1.1 │ ├──dev-v1.1.json │ ├──evaluate-v1.1.py │ ├──train-v1.1.json ├── trt_deployment ├── trt_engine
Fine-tune BERT for QA
In 2020, Google Cloud debuted a custom container feature, allowing you to run your own Docker containers with any pre-installed ML frameworks on CAIP. With the custom container feature, you follow a three-step process:
- Build the custom container for a training job.
- Push the container to the Google Cloud Registry (GCR).
- Submit the training job to CAIP.
Use the following commands in Cloud Shell to build a custom container for a training job and push it to GCR:
$ wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/bert_gcaip/versions/v1.0/zip -O bert_gcaip_v1.0.zip
$ unzip bert_gcaip_v1.0.zip -d bert_on_caip
$ cd bert_on_caip/ngc_bert_finetuning
Inside the directory are several files. You must modify the build.sh script so that it points to your project.
Dockerfile—Builds a container with the Python scripts to fine-tune BERT. It is based on NVIDIA TensorFlow Docker image optimized for GPUs.build.sh—Pulls BERT for TensorFlow resources from NGC, which are copied inside the container. It prompts Docker to build the container and eventually pushes it to Google Cloud Registry.run.sh—Gets called when the container is launched. The script includes parameters and commands to initialize the fine-tuning process. To modify the training parameters, make changes to the file before building the container.
After you update the build script, run it inside Cloud Shell.
$ bash build.sh
After the container is built and pushed to the GCR, you can use the following command to submit a training job to CAIP.
$ gcloud ai-platform jobs submit training <job_name> \ --master-image-uri <image uri pushed to GCR> \ --region <region> \ --master-accelerator count=8,type=<gpu accelerator> --master-machine-type <compute machine type> \ --scale-tier custom
Use the following example parameters:
<job_name> = bert-fine-tuning<image uri pushed to GCR> = gcr.io/<your project>/gtc_demo_bert:latest<region> = us-central1<gpu accelerator> = nvidia-tesla-a100<master machine type> = a2-highgpu-8g
It kicks off the training job with eight NVIDIA A100 GPUs. Monitor the progress and check logs from the Jobs menu on the CAIP page. With eight NVIDIA A100 GPUs, it takes about 20 minutes to finish the fine-tuning job. The completion of the training job creates a saved checkpoint in GCS that is used in the optimization step.
Optimize the pretrained BERT QA model with TensorRT
NVIDIA TensorRT is an SDK for high-performance deep learning inference, built on CUDA, optimizing model neural networks to deliver low latency and high throughput. TensorRT, like the BERT model in the fine-tuning section, can be directly pulled from NGC to be put in use. You can use the same custom container feature on CAIP to run an optimization process.
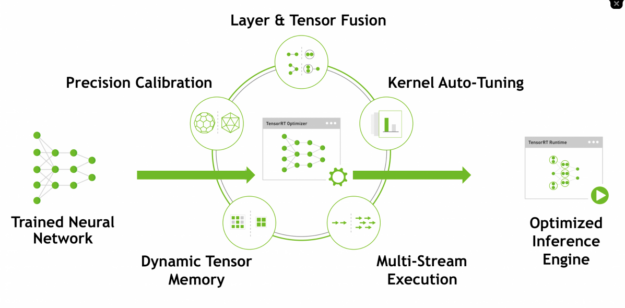
Included in the optimization directory are the Dockerfile, build script and run script.
Dockerfile—Builds a container based on NVIDIA TensorRT Docker image.build.sh—Pulls the TensorRT GitHub repo, builds the container, and pushes it to GCR.run.sh—Gets called when the container is launched. The script prompts the Python script to use TensorRT to create the TensorRT engine, an optimized inference engine based on the BERT model created in fine-tuning process.
To run the build script, run the following commands in Cloud Shell:
$ cd ngc_trt_optimization $ bash build.sh
After the container is built and pushed to the GCR, use the following command to submit an optimization job in the form of a custom container to CAIP:
$ gcloud ai-platform jobs submit training <job_name> \ --master-image-uri <image uri pushed to GCR> \ --region <region> \ --master-accelerator count=1,type=<gpu accelerator> \ --master-machine-type <compute machine type> \ --scale-tier custom
Use the following parameters:
<job_name> = bert-optimization<image uri pushed to GCR> = gcr.io/<your project>/gtc_demo_trt_bert:latest<region> = us-central1<gpu accelerator> = nvidia-tesla-t4<master machine type> = n1-highmem-8
You may notice the changes in the master-accelerator count and the type values. TensorRT needs the same GPU to be used for engine creation and inference. For both operations, use the NVIDIA T4 GPU, designed for deep learning inference.
Deploy the BERT QA model for inference with Triton Inference Server
Triton Inference Server is an open source, inferencing software that lets you deploy trained AI models on any CPU or GPU-powered systems running on-premises or in the cloud. It supports any frameworks of your choice, such as TensorFlow, TensorRT, PyTorch, ONNX, or a custom framework. The models that it serves can be saved on local or cloud storage. Thanks to the custom container feature also debuted on AI Platform Prediction, you can use Triton as a serving software for your AI model on CAIP.
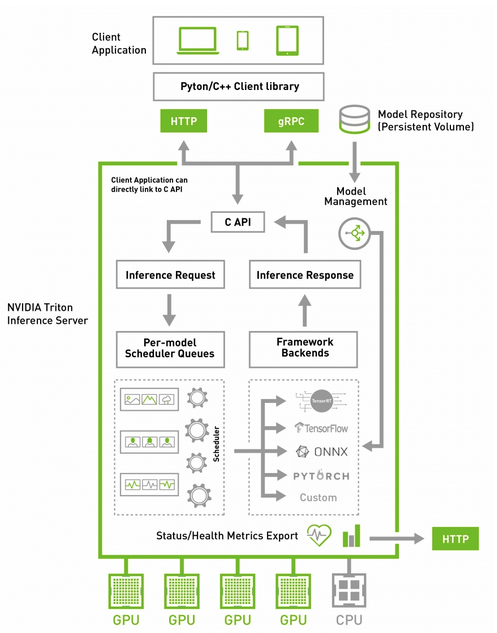
Pull the Triton Inference Server Docker image from NGC. Use the following commands in Cloud Shell:
$ docker pull nvcr.io/nvidia/tritonserver:20.08-py3 $ docker tag nvcr.io/nvidia/tritonserver:20.08-py3 gcr.io/<your project>/tritonserver:20.08-py3 $ docker push gcr.io/<your project>/tritonserver:20.08-py3
AI Platform Prediction uses a hierarchy where the model is a logical grouping of model versions. First, create a model in Cloud Shell:
$ gcloud ai-platform models create <Model Name> --region <Region>
Use the following parameters:
<Model Name> = bert<region> = us-central
Each model version needs a name that is unique within the model. In AI Platform Prediction, {Project}/{Model}/{ModelVersion} uniquely identifies the specific container and model artifact used for inference. You create a YAML file that contains the configuration of the model version that you defined for BERT QA.
import yaml
import os
os.environ[‘PROJECT_ID’]=’<project_id>’
os.environ[‘MODEL_GCS_PATH’]=’<gcs_directory> ’
os.environ[‘VERSION_NAME’]=’demo’
os.environ[‘TRITON_MODEL_NAME’]=’bert_triton’
triton_bert_version = {
"name": os.getenv("VERSION_NAME"),
"deployment_uri": os.getenv("MODEL_GCS_PATH"),
"container": {
"image": "gcr.io/"+os.getenv("PROJECT_ID")+"/tritonserver:20.08-py3",
"args": ["tritonserver",
"--model-repository=$(AIP_STORAGE_URI)",
"--strict-model-config=false"
],
"env": [
],
"ports": [
{ "containerPort": 8000 }
]
},
"routes": {
"predict": "/v2/models/"+os.getenv("TRITON_MODEL_NAME")+"/infer",
"health": "/v2/models/"+os.getenv("TRITON_MODEL_NAME")
},
"machine_type": "n1-standard-4",
"acceleratorConfig": {
"count":1,
"type":"nvidia-tesla-t4"
},
"autoScaling": {
"minNodes": 1
}
}
with open("triton_bert_version.json", "w") as f:
json.dump(triton_bert_version, f)
The YAML file defines the container URI in GCR and Triton-specific commands for inference. As shown earlier, you use an optimized TensorRT engine created in the previous step, referenced as MODEL_GCS_PATH. To register the model version in CAIP for inference, run the following command:
$ gcloud ai-platform versions create <version name> \ --model <model name> \ --accelerator count=1,type=<gpu accelerator> \ --config <config file>
Use the following parameters:
<version name> = demo<model name> = bert<gpu accelerator> = nvidia-tesla-t4<config file> = triton_bert_version.json
If successful, you now have a working Triton server with the BERT QA model, ready to serve the request.
Unlike the fine-tuning and optimization step, prediction jobs for BERT QA require extra work: pre- and post-processing of a question and the context. The Prediction section in the Jupyter notebook, /ngc_triton_bert_deployment/bert_on_caip.ipynb, covers the pre-process and payload generation in detail. After the question and context are pre-processed, you can use either a CURL command to POST the request to create a prediction job or the Google API Client Library to call the AI Platform Prediction REST APIs in Python. Use CURL to post the request:
curl -X POST <endpoint>/projects/<project id>/models/<model name>/versions/<version name>:predict \ -k -H "Content-Type: application/json" \ -H "Authorization: Bearer `gcloud auth print-access-token`" \ -d @payload.dat \ -o response.txt
Use the following parameters:
<endpoint> = https://ml.googleapis.com/v1<project id> = <your/project/id><model name> = bert<version name> = demo
If successful, you receive an answer from the given question and the context:
Context: "TensorRT is a high-performance deep learning inference platform that delivers low latency and high throughput for apps such as recommenders, speech and image/video on NVIDIA GPUs. It includes parsers to import models, and plugins to support novel ops and layers before applying optimizations for inference. Today NVIDIA is open-sourcing parsers and plugins in TensorRT so that the deep learning community can customize and extend these components to take advantage of powerful TensorRT optimizations for your apps." Question: “What is TensorRT?” Answer: “A high-performance deep learning inference platform”
Summary
To recap, you fine-tuned a pretrained BERT model for QA and optimized the fine-tuned QA engine with TensorRT with CAIP Training. You then deployed the optimized BERT QA engine with Triton Inference Server on AI Platform Prediction. You sent requests with the preprocessed question and context to the deployed BERT QA service and received the answer back.
Now is a great time to check out NGC, where you can find collections of assets to build an AI service of your own in CAIP. You can find the curated assets used in this post for Google Cloud as well. To see the demo of this solution in action, see the Building NLP Solutions with NGC Models and Containers on Google Cloud AI Platform on-demand GTC session.
