
In ray tracing, more geometries can reside in the GPU memory than with the rasterization approach because rays may hit the geometries out of the view frustum. You can let the GPU compact acceleration structures to save memory usage. For some games, compaction reduces the memory footprint for a bottom-level acceleration structure (BLAS) by at least 50%. BLASes usually take more GPU memory than top-level acceleration structures (TLAS), but this post is also valid for TLAS.
In this post, I discuss how to compact the acceleration structure in DXR and what to know before you start implementing. Do you have your acceleration structure already working but you want to keep the video memory usage as small as possible? Read Managing Memory for Acceleration Structures in DirectX Raytracing first and then come back.
I assume that you already have your acceleration structures suballocated by larger resources and want to save more video memory by compacting them. I use DXR API in this post but it’s similar in Vulkan too.
How does compaction work?
BLAS compaction is not as trivial as adding a new flag to the acceleration structure build input. For your implementation, you can consider this process as a kind of state machine that runs over a few frames (Figure 1). The compaction memory size isn’t known until after the initial build is completed. Wait until the compaction process is completed on the GPU. Here is the brief process to compact BLAS.
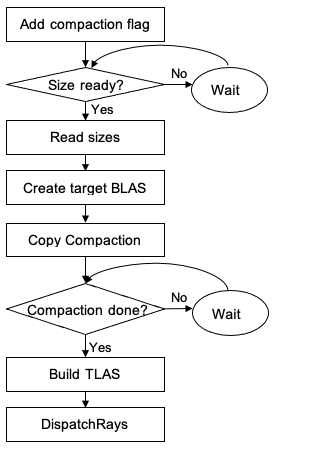
- Add the compaction flag when building the acceleration structure. For
BuildRaytracingAccelerationStructure, you must specify the_ALLOW_COMPACTIONbuild flag for the source BLAS from which to compact. - Read the compaction sizes:
- Call
EmitRaytracingAccelerationStructurePostbuildInfowith the compaction size buffer,_POSTBUILD_INFO_COMPACTED_SIZEflag and the source BLASes that are built with the_ALLOW_COMPACTIONflag. This computes the compaction buffer size on the GPU, which is then used to allocate the compaction buffer. The compaction size buffer is a buffer that holds the size values when it’s ready. - You can pass the post build info structure in your source
BuildRaytracingAccelerationStructureinstead of callingEmitRaytracingAccelerationStructurePostbuildInfo. - The API doesn’t directly return the size that you want to use, as it’s calculated from the GPU.
- Use appropriate synchronization (for example, fence/signal) to make sure that you’re OK to read back the compaction size buffer.
- You can use
CopyResourceandMapto read back the content of the compaction size buffer from GPU to CPU. There could be a couple of frames of delay for reading the size if you execute the command buffer and submit the queue one time per frame. - If the compaction size buffer isn’t ready to be read, then you can keep using the original BLAS for the rest of your rendering pipeline. In the next frames, you keep checking the readiness and continue the following steps.
- Call
- Create a new target BLAS resource with the known compaction size. Now you know the size and you can make your target BLAS resource ready.
- Compact it with
Copy:- Copy from the source BLAS to the target BLAS using
CopyRayTracingAccelerationStructurewith the_COPY_MODE_COMPACTflag. Your target BLAS has the compacted content when it’s finished in GPU. - Make sure that your source BLAS has been built in the GPU already before running
CopyRayTracingAccelerationStructure. - Wait for compaction to be finished using fence/signal.
- You can also run compactions in parallel with other compactions and with other builds and refits.
- Copy from the source BLAS to the target BLAS using
- (Optional) Build a TLAS that points to the new compacted BLAS.
- Use it with
DispatchRays. You are now OK to callDispatchRaysor use inline ray tracing that uses the compacted BLAS.
Tips
Here are a few tips to help you deal with crashes, corruption, and performance issues.
Compaction count
You don’t need to compact all the BLASes in one frame because you can still call DispatchRays with the source BLASes while they’re being compacted. Limit your per-frame BLAS compaction count based on your frame budget.
Animating BLAS
It’s possible to compact animating BLASes, like for characters or particles. However, you pay the compaction cost and the delay of updates. I don’t recommend using compaction on particles and exploding meshes.
Your compacted BLAS could be outdated when it’s ready. In this case, you can refit on the compacted BLAS, if you can.
Don’t add _ALLOW_COMPACTION flag to BLASes that won’t be compacted because adding this flag isn’t free even though the cost is small.
Crashes or corruptions
If you have crashes or corruptions after your compaction-related changes, then try replacing the _COPY_MODE_COMPACT mode in your CopyRaytracingAccelerationStructure with _COPY_MODE_CLONE instead.
Specify the initial acceleration structure size instead of the compacted size. It’ll make sure that your corrupted data is not from the result of the actual compaction if you still have the same issues. It could be from using the wrong/invalid resources or being out of sync due to missing barriers or fence waiting.
Null UAV barriers
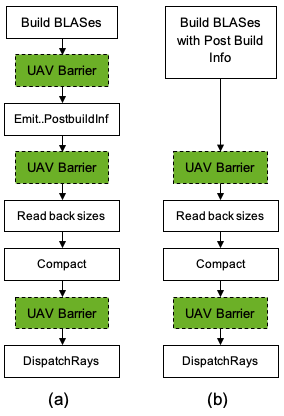
Use null UAV barriers to find why GPU crash issues happen. Keep in mind that using null UAV barriers is suboptimal and try to use more specific options. If you do use null UAV barriers, add them as follows:
- Before the
Emit..PostbuildInfocall - Before reading back the sizes
- After calling
CopyRaytracingAccelerationStructurefor compaction
A null UAV barrier is just the easiest way to make sure that you got all the resources covered, like if you accidentally use the same scratch resource for multiple BLAS builds. The null barrier should prevent those from clobbering each other. Or if you have a preceding skinning shader, you’ll be sure that the vertex positions are updated.
Figure 2 shows two usage patterns that explain where to add barriers. Those barriers are all necessary but you can try replacing them with null barriers to make sure that you didn’t miss anything.
Destroy the source BLAS
Do not destroy the source BLAS while it’s still being used. GPU memory savings can be achieved after you delete the source BLAS. Until then, you are keeping two versions of BLASes in the GPU. Destroy the resource as soon as possible after compacting it. Keep in mind that you can’t destroy them even after CopyAccelerationStructure is completed if you still have previous DispatchRays that uses the source BLAS in GPU.
Max compaction
If you don’t use the PREFER_FAST_BUILD or ALLOW_UPDATE flags, then you should get max compaction.
PREFER_FAST_BUILDuses its own compaction method and results can differ fromALLOW_COMPACTION.ALLOW_UPDATEmust leave room for updated triangles.
Conclusion
It might be more complicated than you thought, but it’s worth doing. I hope you are pleased with the compression rate and the total savings of the GPU memory. I recommend adding debug features that visualize the memory savings and the compression rate from your app to track how it goes per content.
