

This post gathers best practices based on our experiences so far using NVIDIA RTX ray tracing in games. The practical tips are organized into short, actionable items for developers working on ray tracing today. They aim to provide insight into what kind of solutions lead to good performance in most cases. To find the optimal solution for a specific case, I always recommend profiling and experimenting.
Common abbreviations and short terms used in this post:
- AABB: Axis-aligned bounding box
- AS: Acceleration structure
- BLAS: Bottom-level acceleration structure
- Geometry: A geometry in a BLAS
- Instance: An instance of a BLAS in a TLAS
- TLAS: Top-level acceleration structure
Acceleration structures
This section focuses on the building and management of ray-tracing acceleration structures, which is the starting point for using ray tracing for any purpose. Topics include:
- General tips
- Maximizing GPU utilization when building
- Memory allocations
- Organizing geometries into BLASes
- Build preference flags
- Dynamic BLASes
- Non-opaque geometries
- Particles
General tips
Consider async compute for AS building. Especially in hybrid rendering, where G-buffer or shadow maps are rasterized, it’s potentially beneficial to execute AS building on async compute.
Consider worker threads for generating AS building command lists. Generating AS building commands can include a considerable amount of CPU-side work. It can be directly in the AS build calls or in some related task like the culling of the objects. Moving the CPU work to one or more worker threads is potentially beneficial.
Cull instances for TLAS. Typically, including the entire scene in the TLAS is not optimal. Instead, cull instances depending on the situation. For example, consider culling based on an expanded camera frustum. Maximum distance can often be less than the far plane distance in rasterization. You can also consider instance size when culling so that smaller instances are culled at a shorter distance.
Use appropriate Level of Detail (LOD) for instances. Like in rasterization, using the most detailed geometry LOD for everything is typically suboptimal. LODs used for far-away objects can be simpler. In hybrid rendering, using the same LOD for rasterization and ray tracing can be considered. It’s an efficient way to avoid self-intersection artifacts such as surface shadowing itself.
Also consider using lower-detail LODs in ray tracing, especially to reduce the updating cost of dynamic BLASes. If the LODs between rasterization and ray tracing don’t match, enabling back face culling is often needed in ray tracing to prevent the self-intersections. For more information about LODs in ray tracing, and how to implement stochastic LODs, see Implementing Stochastic Levels of Detail with Microsoft DirectX Raytracing.
Flag geometries or instances as opaque whenever possible. Flagging instances or geometries as opaque allows uninterrupted hardware intersection search and prevents invocation of the any-hit shader. Do this whenever possible. Enable the use of any-hit shaders only for those geometries that need it; for example, to do alpha testing.
Use triangle geometries when possible. Hardware excels in performing ray-triangle intersections. Ray-box intersections are accelerated too, but you get the most out of the hardware when tracing against triangle geometries.
Maximizing GPU utilization when building
Batch vertex deformations and BLAS builds. Consecutively execute all vertex deformation calls that produce triangles used as input for BLAS building and all BLAS build calls. Do not place resource barriers between consecutive calls. This allows the driver to parallelize the calls to an extent. All BLAS build calls need unique scratch memory to allow execution without barriers.
The individual UAV barriers for each resource holding BLASes are not needed. Instead, you can have a single global UAV barrier before TLAS build to ensure all BLAS builds are completed, regardless of the resource where they reside.
Consider merging small vertex deformation calls. Often, calls that output deformed vertices for one geometry or instance are lightweight and do not fill the entire GPU even when executed without barriers between consecutive calls. Merging the processing of several geometries or instances to happen in one call can increase GPU utilization and result in better performance.
Memory allocations
Pool small allocations. BLASes can be small, sometimes only a few kilobytes. Using a separate committed resource to store each such small BLAS is not optimal. Instead, pool them with larger resources. Pooling saves memory and often increases performance. One option is to use placed resources in a large resource heap.
Alternatively, many BLASes can be stored in a single buffer by manually suballocating sections from the buffer. This allows even tighter backing of BLASes into memory as the suballocations only have to follow 256-byte alignment. Regardless of the pooling mechanism, avoid memory fragmentation to keep the benefits achieved by pooling. For more information, see Managing Memory for Acceleration Structures in DirectX Raytracing.
Consider compacting static BLASes. Compacting BLASes saves memory and can increase performance. Reduction in memory consumption depends on the geometries but can be up to about 50%. As the compacted size needs to be read back to the CPU after the BLAS build has been completed on GPU, this is most practical for BLASes that are only built one time. Remember to pool small allocations and avoid memory fragmentation to get the maximum benefit from compaction. For more information, see Tips: Acceleration Structure Compaction.
Organizing geometries into BLASes
Consider splitting a BLAS when there is a lot of empty space in an instance’s world-space AABB. World-space AABBs are used to test whether a ray potentially hits an instance and traversing its associated BLAS is required. A significant amount of empty space can lead to unnecessary traversal through the BLAS.
Geometries that move independently should usually be in their own BLASes. Merging them into a single BLAS can lead to an AABB with lots of empty space, and unnecessary rebuilding of the BLAS instead of simply changing transformations of the independent instances.
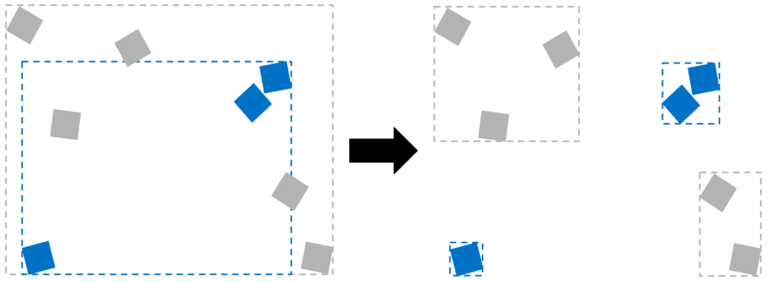
Consider merging BLASes when instance world-space AABBs overlap significantly. When world-space AABBs of instances overlap, each ray going through that region must process separately all the overlapping BLAS instances to find potential intersections. Traversing through one merged BLAS would be more efficient.
Tracing performance against a BLAS doesn’t depend on the number of geometries in it. Geometries merged into a single BLAS can still have unique materials.
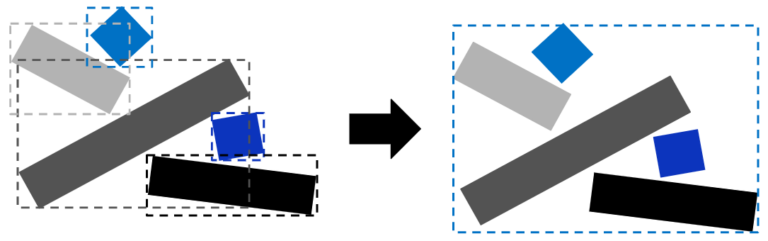
Instantiate BLASes when possible. Instancing BLASes saves memory. It can also increase ray-tracing performance. Instances can have unique materials and transformations. In the case where the AABBs of the instances overlap a lot, replicating and merging them into a single BLAS as multiple geometries can still be a better choice, despite the increased memory consumption.
Avoid elongated triangles in geometries. Long, thin triangles have non-optimal bounding volumes with lots of empty space. They easily overlap with many other bounding volumes. This leads to non-optimal performance when tracing a ray against the geometry.
The driver can mitigate the issues to an extent depending on the geometry. The first such triangle isn’t likely to cause problems, but too many triangles do cause a problem, so I recommend avoiding them when possible; for example, by splitting them into smaller triangles.
Don’t include sky geometry in TLAS. A skybox or skysphere would have an AABB that overlaps with everything else and all rays would have to be tested against it. It’s more efficient to handle sky shading in the miss shader rather than in the hit shader for the geometry representing the sky.
Build preference flags
For TLAS, consider the PREFER_FAST_TRACE flag and perform only rebuilds. Often, this results in best overall performance. The rationale is that making the TLAS as high quality as possible regardless of the movement occurring in the scene is important and doesn’t cost too much.
For static BLASes, use the PREFER_FAST_TRACE flag. For all BLASes that are built only one time, optimizing for best ray-trace performance is an easy choice.
For dynamic BLASes, choose between using the PREFER_FAST_TRACE or PREFER_FAST_BUILD flags, or neither. For BLASes that are occasionally rebuilt or updated, the optimal build preference flag depends on many factors. How much is built? How expensive are the ray traces? Can the build cost be hidden by executing builds on async compute? To find the optimal solution for a specific case, I recommend trying different options.
Dynamic BLASes
Reuse the old BLAS when possible. Whenever you know that vertices of a BLAS have not moved after the previous update, continue using the old BLAS.
Update the BLAS only for visible objects. When instances are culled from the TLAS, also exclude their culled BLASes from the BLAS update process.
Consider skipping updates based on distance and size. Sometimes it’s not necessary to update a BLAS on every frame, depending on how large it is on the screen. It may be possible to skip some updates without causing noticeable visual errors.
Rebuild BLASes after large deformations. BLAS updates are a good choice after limited deformations, as they are significantly cheaper than rebuilds. However, large deformations after the previous rebuild can lead to non-optimal ray-trace performance. Elongated triangles amplify the issue.
Consider rebuilding updated BLASes periodically. It can be non-trivial to detect when a geometry has been deformed too much and would require a rebuild to restore optimal ray-trace performance. Simply periodically rebuilding all BLASes can be a reasonable approach to avoid significant performance implications, regardless of deformations.
Distribute rebuilds over frames. Because rebuilds are considerably slower than updates, many rebuilds on a single frame can lead to stuttering. To avoid this, it’s good practice to distribute the rebuilds over frames.
Consider using only rebuilds with unpredictable deformations. In some cases, when the geometry deformation is large and rapid enough, it’s beneficial to omit the ALLOW_UPDATE flag when building the BLAS and always just rebuild it. If needed, using the PREFER_FAST_BUILD flag to reduce the cost of rebuilding can be considered. In extreme cases, using the PREFER_FAST_BUILD flag results in better overall ray-tracing performance than using the PREFER_FAST_TRACE flag and updating.
Avoid triangle topology changes in BLAS updates. Topology changes in an update mean that triangles degenerate or revive. That can lead to non-optimal ray-trace performance if the positions of the degenerate triangles do not represent the positions of the revived triangles. Occasional topology changes in “bending” deformations are typically not problematic, but larger topology changes in “breaking” deformations can be.
When possible, prefer having separate BLAS versions or using inactive triangles for different topologies caused by “breaking” deformations. A triangle is inactive when its position is NaN. If those alternatives are not possible, I recommend rebuilding the BLAS instead of updating after topology changes. Topology changes through index buffer modifications are not allowed in updates.
Non-opaque geometries
Minimize the non-opaque area when possible. Invoking any-hit shader, typically for performing alpha testing, for non-opaque triangles interrupts hardware intersection search. When possible, minimizing the area not marked as opaque is a simple way to increase performance. Using more triangles to define the non-opaque area more accurately is likely a good trade-off.
Consider splitting to opaque and non-opaque geometries. When a well-defined part of geometry triangles can be considered fully opaque, splitting them into a separate geometry and marking it as opaque can be considered. The different geometries can still reside in the same BLAS.
Particles
Consider representing billboard particles as triangle geometries. One option for representing billboard particles in BLASes is to output the billboards as triangles, rotating part of the billboards 90 degrees along the vertical axis to different orientations. This allows utilization of the triangle intersection hardware while providing a reasonable approximation for the visual boundaries of the particles.
Consider alpha testing instead of blending. Depending on particle type, using alpha testing in secondary rays for particles that are blended when rendering primary visibility may offer reasonable visual quality. This approach works best for particles with clear boundaries. For particles representing things like smoke or fog, this is likely not applicable. For more information, see Ray Traced Reflections in ‘Wolfenstein: Youngblood’.
Avoid using degenerate triangles for dead particles. Degenerate triangles in updated BLASes can make the structure non-optimal for ray tracing. For particle systems with a dynamic number of live particles, I recommend considering other solutions like rebuilding the BLAS on each frame with the correct particle count.
Consider representing mesh particles as instances in TLAS. For particles rendered as triangle meshes, having a unique instance for each particle can be a reasonable solution. This is true when the particles get distributed around the scene so that individual rays do not often hit many instances. Instances should share the base mesh BLAS. Also, consider compacting the BLAS.
Hit shading
This section focuses on the shading of ray hits. Even seasoned graphics developers may benefit from fresh ideas when they start developing ray-tracing shaders, as the optimal solutions may differ from those in rasterization. Topics include:
- General tips
- Minimizing divergence
- Any-hit shader
- Shader resource binding
- Inline ray tracing
- Pipeline states
General tips
Keep the ray payload small. Registers are used to hold payload values and they reduce the number of registers otherwise available to hit shaders. I recommend avoiding careless payload usage, though adding complex code to pack values is rarely beneficial.
Use the payload access qualifiers. This feature becomes available in HLSL Shader Model 6.6. It allows specifying which shader stages write or read each field in the payload and makes it possible for the compiler to better optimize register usage, which can lead to higher occupancy and better performance. For maximum potential benefit, define the qualifiers for each field as accurately as possible. For more information, see DirectX-Specs on GitHub.
Consider writing a safe default value to unused payload fields. When some shader doesn’t use all fields in the payload, which are required by other shaders, it can be beneficial to still write a safe default value to the unused fields. This allows the compiler to discard the unused input value and use the payload register for other purposes before writing to it.
Terminate rays on the first hit when possible. When resolving the correct closest hit is not required (as for shadow rays), flagging rays with RAY_FLAG_ACCEPT_FIRST_HIT_AND_END_SEARCH or gl_RayFlagsTerminateOnFirstHitEXT is a simple and efficient optimization.
Use face culling only when required for correctness. Unlike in rasterization, enabling back- or front-face culling does not improve performance. Instead, it slightly slows ray traversal. Use them only when it is required to get the correct rendering result.
Minimize live state across ray-trace calls. Variables that are initialized before a TraceRay or traceRayExt call and used after it are live states that must be maintained across the call while invoking hit and miss shaders. The driver has a few different options to do it, but they all have a cost.
I recommend trying to minimize the amount of live state. Identifying such variables is not always trivial. NVIDIA and Microsoft are working together on a compiler feature for the automatic detection of a live state.
Avoid deep recursion. Deep, non-uniform ray recursion can get expensive.
Minimizing divergence
Use a separate hit shader for each material model. Reducing code and data divergence within hit shaders is helpful, especially with incoherent rays. In particular, avoid übershaders that manually switch between material models. Implementing each required material model in a separate hit shader gives the system the best possibilities to manage divergent hit shading.
When the material model allows a unified shader without much divergence, you can consider using a common hit shader for geometries with various materials.
Consider simplified shading. Often, replicating all features used in rendering primary visibility for shading specular reflection or indirect diffuse illumination is not necessary. Leaving out features does not always result in a significant visual difference. Alternately, the visual improvement does not justify the rendering cost. The more incoherent the rays, the less accurate replication of primary visibility features is typically required. Also, as the hit distance grows, the shading can sometimes be further simplified.
Avoid direct conversion from vertex and pixel shaders. The approach that leads to optimal performance in hit shading is different from what is optimal for rasterization. In rasterization, having separate shader permutations for even small code differences can be beneficial. In hit shading, both reducing the divergence within individual hit shaders and the number of the separate hit shaders are helpful. Generally, I don’t recommend converting vertex and pixel shaders directly to hit shaders.
Consider moving common code outside of hit and miss shaders. When all hit shaders have a common part, I recommend moving that code away from hit shaders; for example, to the ray generation shader. Sometimes, there can be common code also in hit-and-miss shaders, such as when the approximation for the next bounce in hit shaders is the same as the approximation done for the first bounce in miss shader. Again, I recommend moving that common code outside of hit-and-miss shaders.
Any-hit shader
Prefer unified and simplified any-hit shaders. An any-hit shader is potentially executed a lot during ray traversal, and it interrupts the hardware intersection search. The cost of any-hit shaders can have a significant effect on overall performance. I recommend having a unified and simplified any-hit shader in a ray-tracing pass. Also, the full register capacity of the GPU is not available for any-hit shaders, as part of it is consumed by the driver for storing the ray state.
Optimize access to material data. In any-hit shaders, optimal access to material data is often crucial. A series of dependent memory accesses is a common pattern. Load vertex indices, vertex data, and sample textures. When possible, removing indirections from that path is beneficial.
When blending, remember the undefined order of hits. Hits along ray are discovered and the corresponding any-hit shader invocations happen in undefined order. This means that the blending technique must be order-independent. It also means that to exclude hits beyond the closest opaque hit, ray distance must be limited properly. Additionally, you may need to flag the blended geometries with NO_DUPLICATE_ANYHIT_INVOCATION to ensure the correct results. For more information, see Chapter 9 in Ray Tracing Gems.
Shader resource binding
Prefer the global root table (DXR) or direct descriptor access (Vulkan) when possible. Often, resources used by ray generation and miss shaders can be conveniently bound just like for compute shaders instead of binding through shader records. Also, hit shader resources that are used regardless of what was hit can typically be bound like that too. Having the same resource bound in all hit records is not optimal.
Consider bindless resources for hit shaders. Resources in unbounded descriptor tables (DXR) or unsized descriptor arrays (Vulkan), indexed by the hit-specific system values such as InstanceIndex or gl_InstanceID or values stored directly in the hit records (root constants in DXR) can be an efficient way to provide resources to hit shaders.
Consider root descriptors for index and vertex buffers. (DXR) As an alternative to unbounded descriptor tables, storing index and vertex buffer addresses directly in the hit records as root descriptors can be efficient. Out-of-bounds checks are not implicitly performed when accessing resources through root descriptors. Root descriptor addresses must follow a four-byte alignment. Precomputing an offset to 16-bit indices to the base address may break the alignment.
Use Root Signature version 1.1 and static descriptors when possible. (DXR) Root Signature 1.1 allows the driver to expect that descriptors are static; that is, they are not modified by the application after command lists have been recorded. This enables some potentially beneficial optimizations in the driver, especially when root descriptors are not used for accessing buffers. As with root descriptors, out-of-bounds checks are not implicitly performed with static descriptors. Additionally, both static and root descriptors must not be null.
Consider constructing shader tables on GPU. When there are many geometries and many ray-tracing passes, hit tables can grow large and uploading them can consume a considerable amount of time. Instead of uploading entire hit tables constructed on CPU, upload only the required new information on each frame, such as material indices for currently visible instances, and then execute a hit table construction pass on the GPU to be more efficient.
A large part of the information needed in the table construction can reside permanently in the GPU memory, such as hit group identifiers, vertex buffer addresses, and offsets for geometries.
Inline ray tracing
Consider thread group size 8×8 or larger. As a rule of thumb for compute shaders doing inline ray tracing, thread group size 8×8 can be used. Usually, it is efficient that the number of threads in a group is multiple of the GPU wave size. The wave size in NVIDIA GPUs is 32 threads.
However, using thread groups with only one wave limits the thread occupancy due to a limit in the number of groups simultaneously in execution. Having two waves in a group doubles the potential occupancy. The shader register and group shared memory consumption can also set limits to the occupancy. When the other factors allow, maximum thread occupancy can be reached starting from groups of three waves.
A practical choice for group size could then be 16×8 threads. Increasing the size much beyond this is usually not beneficial. Experimenting with different sizes reveals the optimal one for a specific case. The optimal size may be different for different hardware generations.
Avoid divergent shading with inline ray tracing. As hit shaders are not invoked based on hits, all shading happens inline in the shader that casts rays. Having divergent code paths or data accesses in the shader chosen based on hits can slow down the shading, especially with incoherent rays. When multiple different shading models are required, using DispatchRays or vkCmdTraceRaysKHR is a better choice.
Use the hit-specific system values for bindless resource access with inline ray tracing. As bindings in hit records are not available, geometry-specific bindings must be provided by other means. Accessing resources in unbounded descriptor tables based on the hit-specific system values such as InstanceContributionToHitGroupIndex and GeometryIndex is a good practice.
I recommend avoiding indirections in accessing index, vertex, and material data when possible. For example, reading a resource index from a buffer based on a system value like InstanceID for selecting an index buffer may cause latency that is difficult to hide.
Prefer the compile-time ray flags. Both compile-time and runtime ray flags can be used with inline ray tracing. I recommend preferring the compile-time flags when possible, as they may enable beneficial compile-time optimizations.
Monitor the register consumption of the query objects. After initialization, the query objects must hold state for the ray traversal when the shader is executing code that may continue the traversal. This consumes registers and complex user code may limit occupancy sooner than usual. The situation is similar to executing any-hit shaders in a DispatchRays or vkCmdTraceRaysKHR pass. Variables initialized before using the query object and used after that may consume additional registers.
Consider thread group reordering to improve coherency. When using inline ray tracing from a compute shader, the default row major assignment of the dispatched thread groups to GPU for execution often does not result in optimal performance. Coherency of the memory accesses done by the thread groups simultaneously in execution on GPU can be improved by manually reordering the thread groups. For more information, see Parallel Shader Compilation for Ray Tracing Pipeline States.
Pipeline states
Consider one state object per ray generation shader. I recommend having a separate state object for each DispatchRays or vkCmdTraceRaysKHR call compiled with only the shaders required in that pass. It can help in optimizing the register consumption and allows the optimal setting of pipeline configuration values described later in this post.
Set MaxTraceRecursionDepth, MaxRecursionDepth, MaxPayloadSizeInBytes, and MaxAttributeSizeInBytes as small as possible. Setting these higher than necessary may have an unnecessarily negative performance impact. When using inline ray tracing within a DispatchRays or vkCmdTraceRaysKHR call, those ray-trace calls don’t count towards the maximum recursion depth.
Use SKIP_PROCEDURAL_PRIMITIVES, SKIP_AABBS, and SKIP_TRIANGLES whenever possible. These pipeline state flags allow simple but potentially effective optimizations in state compilation.
Consider shader collections for parallel compilation and sharing. (DXR) When you are managing many shaders, shader collections may allow multi-threaded compilation of state objects and sharing of compiled code between state objects. For more information, see Parallel Shader Compilation for Ray Tracing Pipeline States.
When automatic bind point assignment is needed, consider the compiler options. (DXR) By default, automatic bind point assignment for shader resources is not used when compiling shader libraries. If that is required, there are a couple useful compiler options. First, /auto-binding-space enables automatic bind point assignment in a given register space. Also, all functions not marked with the keyword static are considered library exports by default.
When using /auto-binding-space, resources accessed by any exported function consume bind points regardless of whether they are used in the final state object. To limit the bind point consumption to only the functions really needed, /exports can be used to limit the library exports.
Consider AddToStateObject for incremental building. It allows the incremental building of state objects based on existing objects, which can be useful when managing dynamic content with many shaders.
Manually manage the stack if applicable. Use the API’s query functions to determine the stack size required per shader and apply app-side knowledge about the call graph to reduce memory consumption and increase performance.
A good example is expensive reflection shaders shooting secondary shadow rays, which are known by the app to only use trivial hit shaders with low stack requirements. The driver can’t know this call graph in advance, so the default conservative stack size computation over-allocates memory.
Tools
Consider implementing a heatmap. To discover performance issues related to specific BLASes, or shading of specific geometries, NVIDIA offers a convenient API for implementing a heatmap for visualizing the processing cost of each pixel. This can be useful for improving the performance of your ray-tracing passes. For more information, see Profiling DXR Shaders with Timer Instrumentation.
Use NVIDIA Nsight Graphics for profiling and debugging. Learn more about inspecting acceleration structures, shader tables, and profiling ray-tracing passes.
For more information about how to use Nsight Graphics most efficiently, see the following posts:
- Optimizing VK/VKR and DX12/DXR Applications Using Nsight Graphics: GPU Trace Advanced Mode Metrics
- The Peak-Performance-Percentage Analysis Method for Optimizing Any GPU Workload
Consider updating to the latest version of the Microsoft Shader Compiler. (DXR) For new features and optimization, it’s often worthwhile to update to the latest available version of the Microsoft Shader Compiler.
