
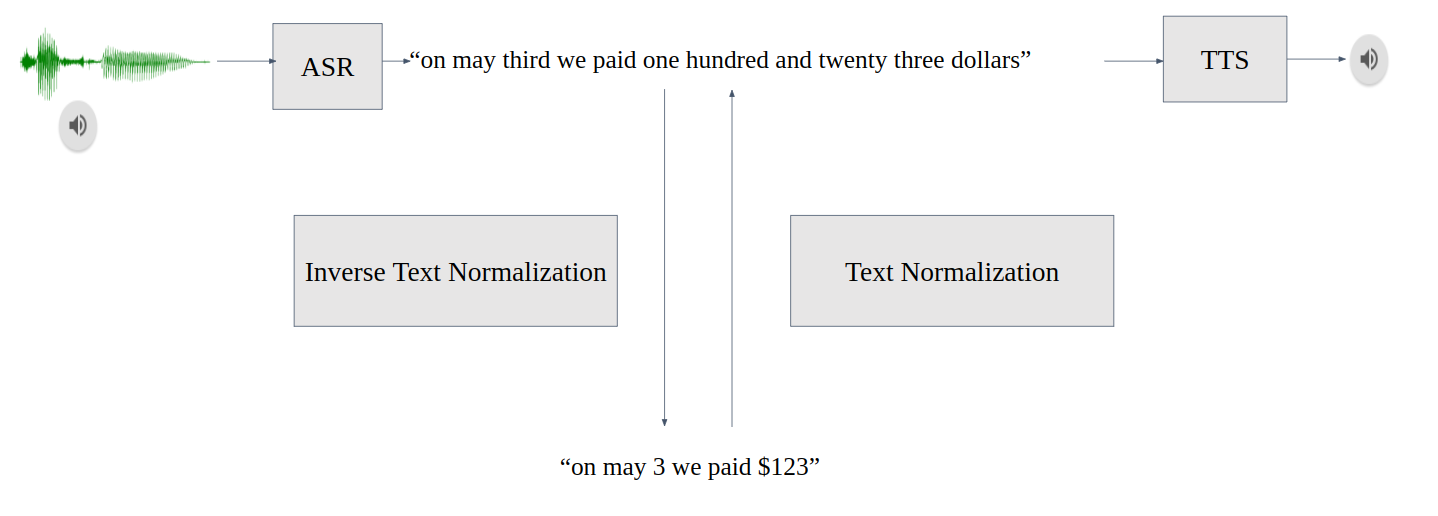
Text normalization (TN) converts text from written form into its verbalized form, and it is an essential preprocessing step before text-to-speech (TTS). TN ensures that TTS can handle all input texts without skipping unknown symbols. For example, “$123” is converted to “one hundred and twenty-three dollars.”
Inverse text normalization (ITN) is a part of the automatic speech recognition (ASR) post-processing pipeline. ITN converts ASR model output into its written form to improve text readability. For example, the ITN module replaces “one hundred and twenty-three dollars” transcribed by an ASR model with “$123.”
ITN not only improves readability but also boosts the performance of downstream tasks such as neural machine translation or named entity recognition, as such tasks use written text during training.
TN and ITN tasks face several challenges:
- Labeled data is scarce and difficult to collect.
- There is a low tolerance for unrecoverable errors, as TN and ITN errors cascade down to subsequent models. TN and ITN errors that alter the input semantics are called unrecoverable.
TN and ITN systems support a wide variety of semiotic classes, that is, words or tokens where the spoken form differs from the written form, requiring normalization. Examples are dates, decimals, cardinals, measures, and so on.
Many state-of-the-art TN systems in production are still rule-based using weighted finite state transducers (WFST). WFSTs are a form of finite-state machines used to graph relations between regular languages (or regular expressions). For this post, they can be defined by two major properties:
- Mappings between accepted input and output expressions for text substitution
- Path weighting to direct graph traversal
In case of ambiguity, the path with the smallest sum of weights is chosen. In Figure 2, “twenty-three” is transduced to “23″ instead of “20 3.”

Currently, NVIDIA NeMo offers the following option for TN and ITN systems:
- Context-independent WFST-based TN and ITN grammars
- Context-aware WFST-based grammars + neural LM for TN
- Audio-based TN for speech datasets creation
- Neural TN and ITN
WFST-based grammar (systems 1, 2, and 3)
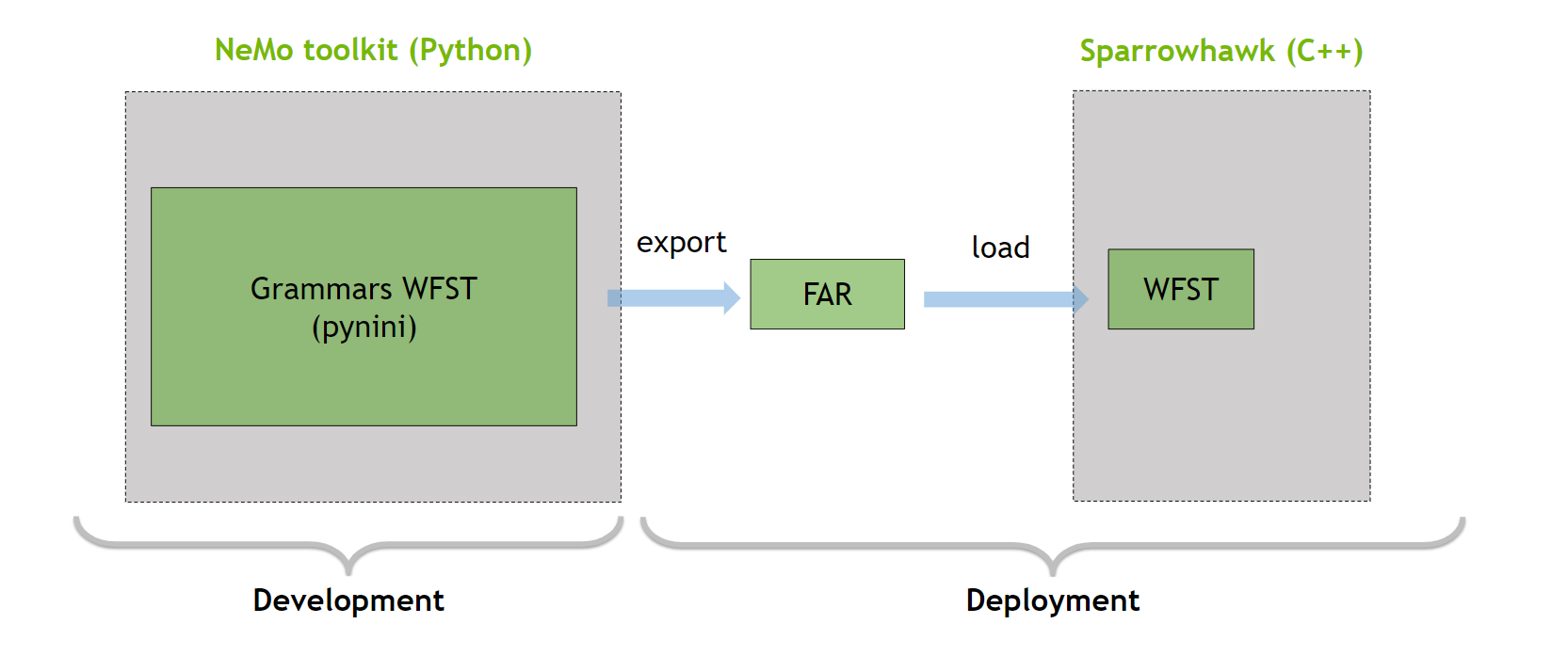
The NeMo Text Processing package is a Python framework that relies on the Python package Pynini to write and compile normalization grammars. For more information about the latest supported languages, see Language Support Matrix. For more information about how to extend or add your language grammar, see Grammar customization.
Pynini is a toolkit built on top of OpenFst, and it supports the export of the grammars into an OpenFST Archive File (FAR) (Figure 3). The FAR file can be used in a C++ production framework, which is based on Sparrowhawk.
Our initial version of TN/ITN system #1 does not take context into account, as that would make the rules significantly more complex, which requires extensive linguistic knowledge and deteriorates latency. If an input is ambiguous, for example, “1/4” in “The train leaves on 1/4” compared to “1/4 of a cup,” system #1 chooses the normalization deterministically without considering the context.
The system extends system #1 and incorporates context during normalization. The system outputs multiple normalization options in case of contextual ambiguity, which is rescored using a pretrained language model using Masked Language Model Scoring (Figure 4).

- WFST generates all possible normalization forms and assigns weights to each option.
- Pruning normalization options with weights higher than the threshold value “401.2″. In this example, we dropped “one/four”. It has a higher weight as it was not fully normalized.
- LM rescoring picks the best among the remaining options.
This approach is similar to shallow fusion for ASR and combines the benefits of the rule-based and neural system. The WFST still limits unrecoverable errors while the neural language model resolves contextual ambiguity without the need for extensive rules or hard-to-get data. For more information, see Text normalization.
| Dataset | Number of sentences | Det WFST | Duplex | WFST + LM |
| EngConf | 231 | 68.83 | 55.41 | 94.37 |
| GoogleTN | 7551 | 97.29 | 99.07 | 97.79 |
| LibriTTS | 7677 | 98.65 | 90.40 | 99.01 |
Table 1 compares the WFST+LM approach in terms of sentence accuracy with the previous system #1 (DetWFST) and a purely neural-based system (Duplex) on three datasets. Later in this post, we provide more details on system #4.
Overall, the WFST+LM model is most effective, particularly on EngConf, a self-collected dataset with ambiguous examples.
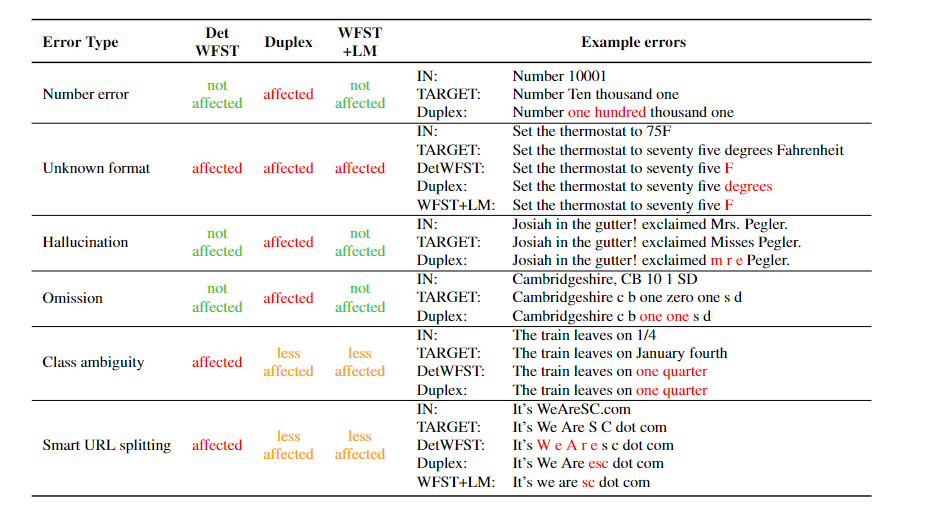
Figure 5 shows how susceptible the three methods are to errors. While the neural method is most affected by unrecoverable errors, such as hallucinations or omissions, WFST+LM is least affected by those and class ambiguity.
Audio-based TN (system 3)
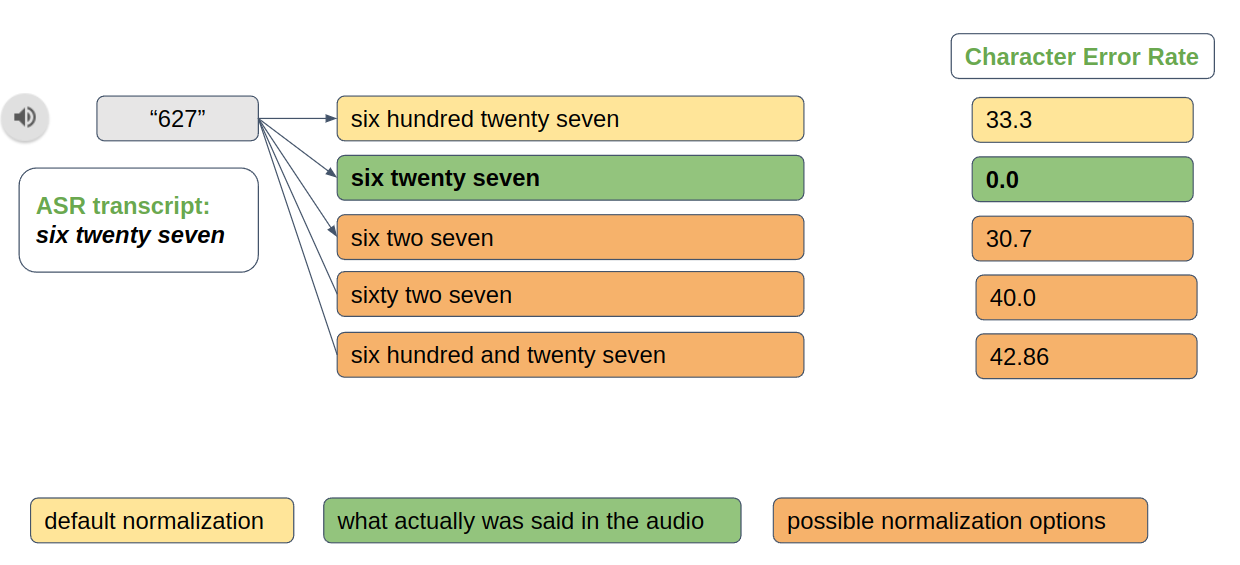
Text normalization also comes in handy during the creation of new speech datasets. For instance, “six two seven” and “six twenty-seven” are both valid normalization options of ”627”. However, you must select the option that best reflects what is actually said in the corresponding audio. Audio-based text normalization provides such functionality (Figure 6).
Neural TN and ITN model (system 4)
One significant advantage of neural systems compared to rule-based systems is they are easy to scale if training data for a new language exists. Rule-based systems require much effort to create and may work slowly on some inputs due to combinatorial bursts.
As an alternative to the WFST solution, NeMo hosts a seq2seq Duplex model for TN/ITN and a tagger-based neural model for ITN.
Duplex TN and ITN
Duplex TN and ITN is a neural-based system that can do both TN and ITN. At a high level, the system consists of two components:
- DuplexTaggerModel: A transformer-based tagger for identifying semiotic spans in the input (for example, spans about times, dates, or monetary amounts). [NEED LINK]
- DuplexDecoderModel: A transformer-based seq2seq model for decoding the semiotic spans into their appropriate forms (for example, spoken forms for TN and written forms for ITN).
The term duplex refers to the fact that this system can be trained to do both TN and ITN. However, you can also specifically train the system for only one of the tasks.
Thutmose tagger
The Duplex model is a sequence-to-sequence model. Unfortunately, such neural models are prone to hallucinations that could lead to unrecoverable errors.
The Thutmose Tagger model regards ITN as a tagging task and mitigates hallucination issues (Figures 7 and 8). Thutmose is a single-pass token classifier model that assigns a replacement fragment to every input token or marks it for deletion or copying without changes.
NeMo provides a method of dataset preparation, based on granular alignment of ITN examples. The model is trained on the Google Text Normalization dataset and achieves state-of-the-art sentence accuracy on both English and Russian test sets.
Tables 2 and 3 summarize evaluation results for two metrics:
- Sentence accuracy: An automatic metric that matches each prediction with multiple possible variants of the reference. All errors are divided into two groups: digit error and other error. Digit error occurs when at least one digit differs from the closest reference variant. Other error means a non-digit error is present in the prediction, for example, a punctuation or letter mismatch.
- Word error rate (WER): An automatic metric commonly used in ASR.
| Test set | Metric | Duplex model | Thutmose (BERT) | Thutmose (d-BERT) |
| Default | Sent. acc. | 97.31 | 97.43 | 97.36 |
| Digit error | 0.35 | 0.31 | 0.38 | |
| Other error | 2.34 | 2.26 | 2.26 | |
| WER | 2.9 | 3.7 | 3.74 | |
| Hard | Sent. acc. | 85.34 | 85.17 | 84.71 |
| Digit error | 3.12 | 3.13 | 3.06 | |
| Other error | 11.54 | 11.70 | 12.23 | |
| WER | 9.34 | 9.02 | 9.10 |
d-BERT stands for distilBERT.
Default is the default Google Text Normalization test set.
Hard is a test set with sampling of at least 1,000 examples for each semiotic class.
| Test set | Metric | Duplex model | Thutmose (BERT) | Thutmose (d-BERT) |
| Default | Sent. acc. | 92.34 | 93.45 | 92.72 |
| Digit error | 0.51 | 0.43 | 0.52 | |
| Other error | 7.15 | 6.11 | 6.75 | |
| WER | 3.63 | 2.94 | 3.67 | |
| Hard | Sent. acc. | 81.02 | 84.03 | 81.75 |
| Digit error | 3.24 | 3.08 | 3.77 | |
| Other error | 15.74 | 12.90 | 14.48 | |
| WER | 11.76 | 7.07 | 8.05 |
One-to-one correspondence between tags and input words improves the interpretability of the model’s predictions, simplifies debugging, and enables post-processing corrections. The model is simpler than sequence-to-sequence models and easier to optimize in production settings.
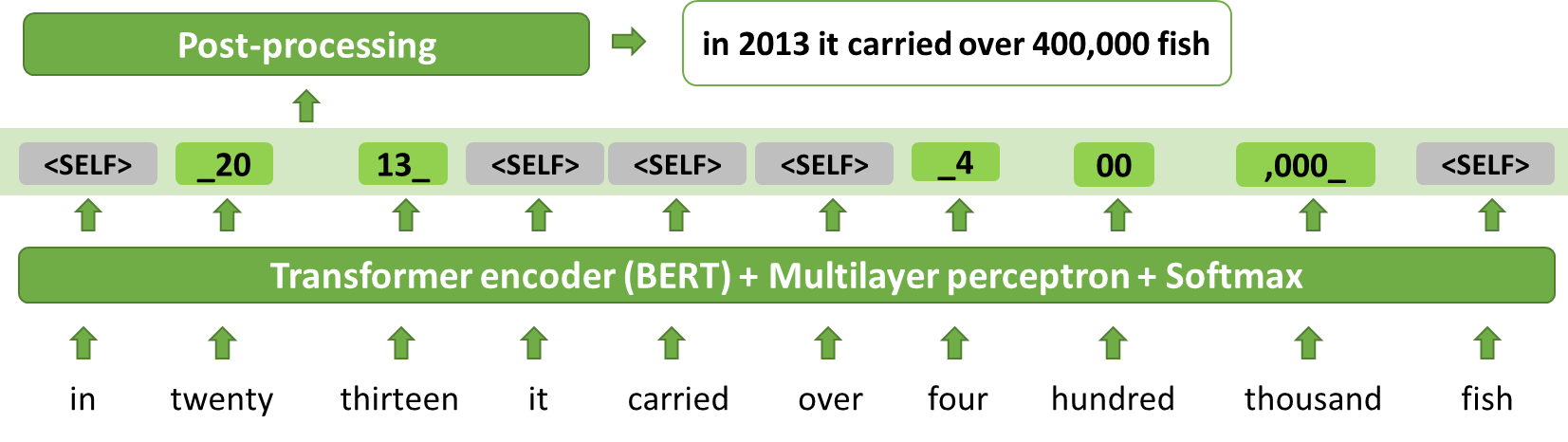
The sequence of input words is processed by the BERT-based token classifier, giving the output tag sequence. Simple deterministic post-processing gives the final output.

Conclusion
Text normalization and inverse text normalization are crucial for conversational systems and considerably affect users’ experience. This post introduced a novel way of handling TN task by combining the benefits of WFST and pretrained language models and a new neural tagging-based approach for tackling ITN task.
For more information, including code examples, tutorials, and documentation for the TN/ITN solutions discussed in this post, see the NVIDIA/NeMo GitHub repo.
