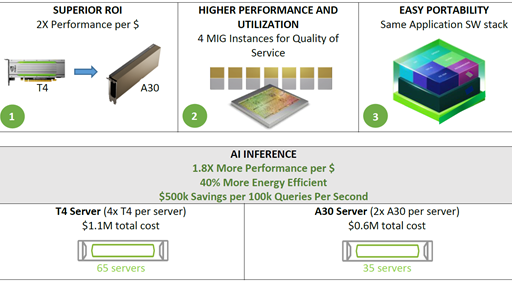
NVIDIA T4 was introduced 4 years ago as a universal GPU for use in mainstream servers. T4 GPUs achieved widespread adoption and are now the highest-volume NVIDIA data center GPU. T4 GPUs were deployed into use cases for AI inference, cloud gaming, video, and visual computing.
At the NVIDIA GTC 2023 keynote, NVIDIA introduced several inference platforms for AI workloads, including the NVIDIA T4 successor: the NVIDIA L4 Tensor Core GPU. The L4 GPU is now the universal, energy-efficient accelerator designed to meet AI needs for video, visual computing, graphics, virtualization, generative AI, and numerous applications for edge computing.
In this post, we walk through how mainstream servers with the L4 GPUs provide more AI video performance and enable more video streams compared to the previous generation (T4). You will find proven results for use cases ranging from video streaming to drug discovery and learn how you can experience the difference of running an AI workload on the L4 GPU today.
Ada Lovelace architecture L4 Tensor Core GPU
The NVIDIA L4 GPU is based on the NVIDIA Ada Lovelace architecture and has the following features:
- Fourth-generation Tensor Cores
- Third-generation RT cores
- Shader execution re-ordering (SER)
- Hardware-accelerated image and video processing engines, including AV1 encode/decode
- Deep learning super sampling (DLSS 3)
- 24 GB GDDR6 memory
This versatile GPU comes in a PCIe single-slot low-profile form factor with a 72 W power envelope.
More performance for generative AI
The demand for accelerated computing is increasing more than ever as generative AI capabilities and use cases make customer lives more convenient and experiences more immersive. The L4 GPU improves these experiences by delivering up to 2.7x more generative AI performance than the previous generation.
With the NVIDIA AI platform and full-stack approach, the L4 GPU is optimized for inference at scale for a broad range of AI applications. Inference is where AI goes to work in the real world, touching every product, service, and interaction.
Innovators push the boundaries of what is possible. From video recommendations to AI-generated avatars, they are building AI models with rapidly increasing complexity to cover more use cases than ever.
4X faster graphics performance
With third-generation RT cores and AI-powered DLSS 3, the NVIDIA L4 GPU delivers nearly 4x higher performance for AI-based avatars, NVIDIA Omniverse virtual worlds, cloud gaming, and virtual workstations. It enables you to build real-time cinematic-quality graphics and incredibly detailed scenes for an immersive visual experience that would not be possible with CPUs.
Real-time AI video pipeline performance
As of today, 80% of consumer internet traffic is video. Whether streaming live to millions of viewers, enabling users to build creative stories, or delivering immersive AR/VR experiences, servers equipped with the L4 GPUs enable hosting up to 1000+ AV1 video streams at 720p30 for mobile applications concurrently. The performance was measured with an AV1 low-latency encode with a p1 preset.
Plus, the L4 GPU can stream in multiple resolutions and formats to multiple platforms, enabling simultaneous broadcasting on more channels including on social media platforms.
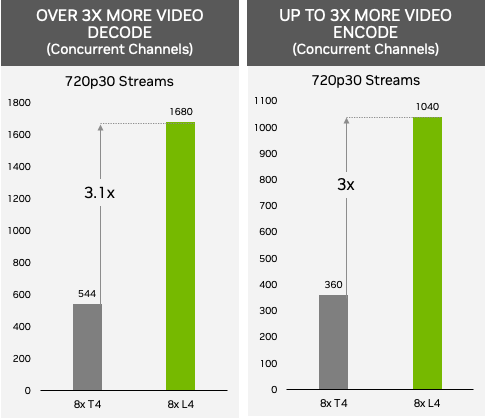
Measured performance. Video-Decode: NVIDIA L4 (H.264 720p30) vs NVIDIA T4 (H.264 720p30) using FFMPEG 5.0.1. Video Encode (low-latency p1 preset): NVIDIA L4 (AV1 720p30) vs NVIDIA T4 (H.264 720p30) using FFMPEG 5.0.1
With the fourth-generation Tensor Core technology, added FP8 precision support, 1.5x larger GPU memory, NVIDIA L4 GPUs paired with the CV-CUDA library take video content understanding to a new level.
The L4 GPU delivers 120x higher AI video performance than CPU-based solutions for the entire end-to-end pipeline. This enables enterprises to gain real-time insights to provide personalized content, improve search relevance, detect objectionable content, and implement smart space solutions.
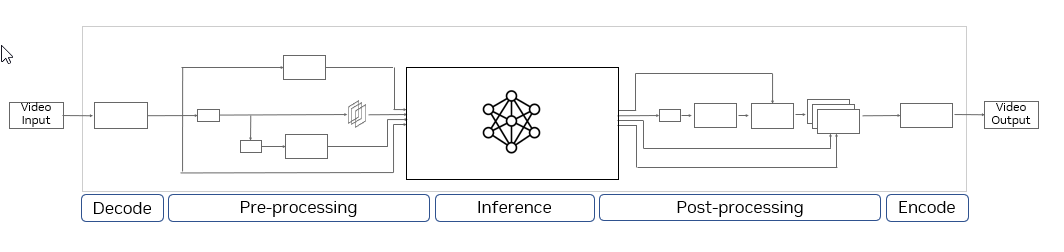
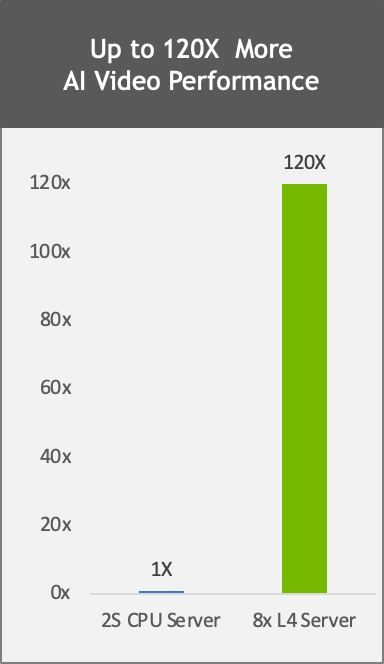
Measured performance: 8x L4 vs. 2S Intel 8380 CPU server performance comparison, end-to-end video pipeline with CV-CUDA pre- and post-processing, decode, inference (SegFormer), encode, TRT 8.6 vs. CPU only pipeline using OpenCV 4.7, PyT inference.
High-energy efficiency for AI video
As AI and video become more pervasive, the demand for efficient, cost-effective computing is increasing more than ever. NVIDIA L4 GPUs deliver up to 120x better AI video performance, resulting in over 99% better energy efficiency and cost of ownership compared to traditional CPU-based infrastructure. This enables enterprises to reduce rack space and significantly lower the overall carbon footprint while making their data centers capable of scaling to many more users.
The energy saved by switching from CPUs to NVIDIA L4s in a 5MW data center can power nearly 6,000 homes for 1 year or the carbon offset from 500,000 trees grown over 10 years.
Customer success stories
Here are some use cases and insights from early access customers as they evaluated the L4 GPU with their current solutions.
Snap
Snap’s visual messaging application, Snapchat, uses NVIDIA GPUs to transcode massive amounts of video, ultimately delivering the best video quality possible for their community.
“Snapchat’s video transcoding pipeline processes millions of videos each day, with a focus on delivering the best possible quality to 750 million monthly active Snapchatters.
Snap’s transcoding team partnered with NVIDIA to leverage GPU acceleration and managed to reduce the cost of HEVC transcoding by 80%. Their team is excited by the potential of AV1 support in the NVIDIA L4 GPU and, based on early testing, is seeing significant quality improvement and bandwidth reduction, with similar throughput as GPU HEVC transcoding,” said Jiayao Yu, engineering manager for Snap’s Media Delivery Platform.
Kuaishou
Kuaishou provides a world-leading, content community and social platform. Hundreds of millions of users around the world use Kuaishou to create short videos, edit them with special effects, and share them to their followers.
There are several critical services in Kuaishou that are using the NVIDIA inference platforms A10 and L4 GPUs:
- The recommendation system for livestreaming content uses GPUs to improve predictions of users’ click-through rate (CTR) on live content with reasonable infrastructure cost. The workflow has multiple stages, including decoding the incoming livestream video, capturing key frames, performing any necessary audio and video demux and image processing, and then finally using a transformer-based large-scale model to understand multi-modal content and improve the CTR.
- Another system uses natural language processing (NLP) and ViT and Swin vision transformers to recognize text in video to enhance video search relevance.
- The ad delivery and e-commerce systems recommend livestreams and videos to users for promoting commercial goods. The AI and video analytics capabilities of the L4 GPU accelerate the systems’ understanding of commercial brands and product features such that their targeting become more relevant to users. Last year, in 2022, the eCommerce gross merchandise value (GMV) was over 100B dollars.
“The Kuaishou recommendation system serves a community having over 360 million daily users who contribute millions of UGC videos every day,” said Yue YU, senior vice president at Kuaishou. “Compared to CPUs under the same total cost of ownership, NVIDIA GPUs have been increasing the system end-to-end throughputs by 11x and reducing latency by 20%.”
Descript
Descript, a generative AI-powered video editing application hosted on Google Cloud, helps people quickly edit blogs, documentaries, and video content. Descript’s AI-powered features and intuitive interface fuel YouTube and TikTok channels, top podcasts, and businesses using video for marketing, sales, and internal training and collaboration. Using Descript, editors can benefit from AI’s ability to automatically remove filler words, suggest subtitles, add captions, and more.
“L4 testing with Descript’s video and audio transcription pipeline showed a 150% increase in performance compared to T4. This will enable us to support 50% more users with text-based editing using the same number of servers,” said Kundan Kumar, Head of AI, Descript.
WOMBO
WOMBO is a leading mobile app developer and one of the leaders in generative AI image creation in the consumer space. WOMBO Dream, their main app has been downloaded more than 55M times and they average 3M images generated per day. They are running today doing image inferencing using stable diffusion on NVIDIA GPUs and recently evaluated the L4 GPU.
“WOMBO relies upon the latest AI technology for people to create immersive digital artwork from user prompts, letting them create high-quality, realistic art in any style with just an idea,” said Ben-Zion Benkhin, CEO, WOMBO. “NVIDIA L4 inference platforms will enable us to offer a better, more efficient image-generation experience for users seeking to create and share unique artwork.“
Schrödinger molecular simulation for drug discovery
Schrödinger uses GPUs for free energy perturbation (FEP+) calculations to simulate protein-ligand interactions in silico. Their digital chemistry platform is used by drug discovery researchers all over the world.
Schrödinger and NVIDIA work together to optimize the performance of molecular dynamics simulations. Molecular dynamics calculations occur on time scales that are computationally demanding to simulate. The hardware used determines whether a simulation takes days, hours, or minutes.
Schrödinger has evaluated its GPU-accelerated molecular dynamics simulations over multiple generations of NVIDIA GPUs: the NVIDIA Pascal, NVIDIA Volta, NVIDIA Turing, and NVIDIA Ampere architectures. They find that the new NVIDIA Ada Lovelace architecture L4 GPUs provide the best price per performance for molecular dynamics simulations.
CP All
CP All is the sole licensed operator of over 11,000 7-Eleven convenience stores across Thailand. Gosoft, CP All’s IT services company, deployed customer service bots built on the NVIDIA conversational AI platform to help answer common questions and track orders. The bots understand and speak Thai with 97% accuracy, according to Areoll Wu, deputy general manager of CP All. Typically, Gosoft receives 250,000 calls per day.
“Providing a great customer experience to millions of our users is of utmost importance to us. That’s why we are thrilled to use NVIDIA L4 and Riva for our Thai end-to-end Conversational AI (ASR+NLP+TTS) service. It delivers up to 3x better performance and more than 50% reduction in latency, enabling us to make our services better than ever before,” says Areoll Wu, Deputy General Manager CP All Public Company Limited (Thailand).
How to access NVIDIA L4 GPUs?
There are several options available, with the list of platforms set to expand throughout 2023.
- Google Cloud Platform (GCP) is the first cloud platform to announce NVIDIA L4 instances, currently accessible through private preview.
- They are available from a global network of more than 30 computer makers, including Advantech, ASUS, Atos, Cisco, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo, QCT, and Supermicro.
- You can also access L4 GPUs through NVIDIA LaunchPad and learn more through our free, hands-on workshops and NVIDIA AI Enterprise labs.
Learn more about NVIDIA GPU cloud instances in the Accelerate your AI/ML and HPC Workloads with Google Cloud GTC 2023 session.