
Building on the past decade’s development of OpenVDB, the introduction of NVIDIA NeuralVDB is a game-changer for developers and researchers working with extremely large and complex datasets.
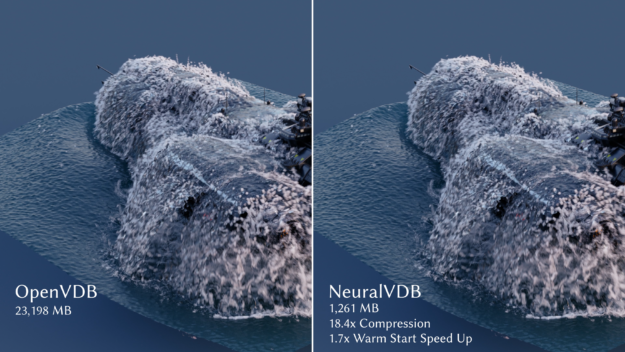
The pre-release version of NVIDIA NeuralVDB brings AI and GPU optimization to OpenVDB, delivering up to a 100x reduction in memory footprint for smoke, clouds, and other sparse volumetric data.
By dramatically reducing memory requirements, accelerating training, and enabling temporal coherency, NeuralVDB can unlock new possibilities for scientific and industrial use cases. This includes massive, complex volume datasets for AI-enabled medical imaging, large-scale digital twin simulations, and more.
Introducing NeuralVDB
Sparse volumetric data can be found across a growing range of use cases. Medical, industrial, robotics, graphics, and other fields demand high-resolution real-time simulations at unprecedented magnitudes. However, corresponding memory demands can conflict with hardware constraints.
NeuralVDB solves this issue by offering incredibly efficient memory representations at the cost of small to negligible quality loss, enabling volumetric applications at extreme resolutions.
NeuralVDB is a set of tools and APIs for compact representations of high-resolution space volumetric data. It improves on OpenVDB, which is an open industry standard for the efficient storage and processing of high-resolution volumes. It also builds on the GPU acceleration of NVIDIA NanoVDB, introduced last year, adding machine learning to deliver compact neural representations that dramatically reduce its memory footprint.
In fact, NeuralVDB reduces the memory footprint of OpenVDB by 1–2 orders of magnitude, at the cost of a user-controlled and typically unperceivable loss of details. This enables you to transmit and share large, complex volumetric datasets much more efficiently.
To do this, NeuralVDB employs hierarchical neural representations in the form of lossless classifiers for the tree topology and lossy regressors for the sparse values. This approach combines the best of two worlds. It uses neural networks to maximize the compression ratio of 3D data while maintaining the spatial adaptivity offered by the higher-level VDB data structure.

The combination enables a VDB tree to focus on coarse, upper-node-level topology information, while multiple neural networks compactly encode fine-grain topology and value information at the voxel and lower-tree levels. This also applies to animated volumes, even maintaining temporal coherency and improving performance with the novel temporal encoding feature.
Learn more by watching the NeuralVDB presentation from GTC 2022 on NVIDIA On-Demand.
What’s included in NeuralVDB Early Access
NVIDIA is looking for developers who are interested in testing this early version of NeuralVDB and willing to provide feedback to help improve features in advance of an open-source release later this year. The Early Access Program gives you access to the pre-release version of the NeuralVDB SDK as well as example config files and documentation.
This SDK includes the following key features:
NeuralVDB Converter
- Codec application to convert OpenVDB or NanoVDB files into NeuralVDB files, or the reverse
- Batch encode/decode time-series VDBs with temporal encoding
NeuralVDB Library
- Library containing a set of C++ APIs for VDB object encoding/decoding
- An API to perform random queries from an in-memory NeuralVDB object
How to get started
NeuralVDB is the next evolution of the VDB library, offering significant efficiency improvements for simulating and rendering sparse volumetric data. The pre-release version is available now through the NVIDIA NeuralVDB Early Access Program. Register now to download the SDK and experience the power that the AI-accelerated NeuralVDB can offer your sparse volume workflows.
