OpenVDB is the Academy Award–winning, industry standard library for sparse dynamic volumes. It is used throughout the visual effects industry for simulation and rendering of water, fire, smoke, clouds, and a host of other effects that rely on sparse volume data. The library includes a hierarchical, dynamic data structure and a suite of tools for the efficient storage and manipulation of sparse volumetric data discretized on three-dimensional grids. The library is maintained by the Academy Software Foundation (ASWF). For more information, see VDB: High-Resolution Sparse Volumes with Dynamic Topology.

Despite the performance advantages offered by OpenVDB, it was not designed with GPUs in mind. Its dependency on several external libraries has made it cumbersome to leverage the VDB data on GPUs, which is exactly the motivation for the topic of this post. We introduce you to the NanoVDB library, and provide some examples of how to use it in the context of ray tracing and collision detection.
Introduction to NanoVDB
The NanoVDB library, originally developed at NVIDIA, is a new addition to the ASWF’s OpenVDB project. It provides a simplified representation that is completely compatible with the core data structure of OpenVDB, with functionality to convert back-and-forth between the NanoVDB and the OpenVDB data structures, and create and visualize the data.
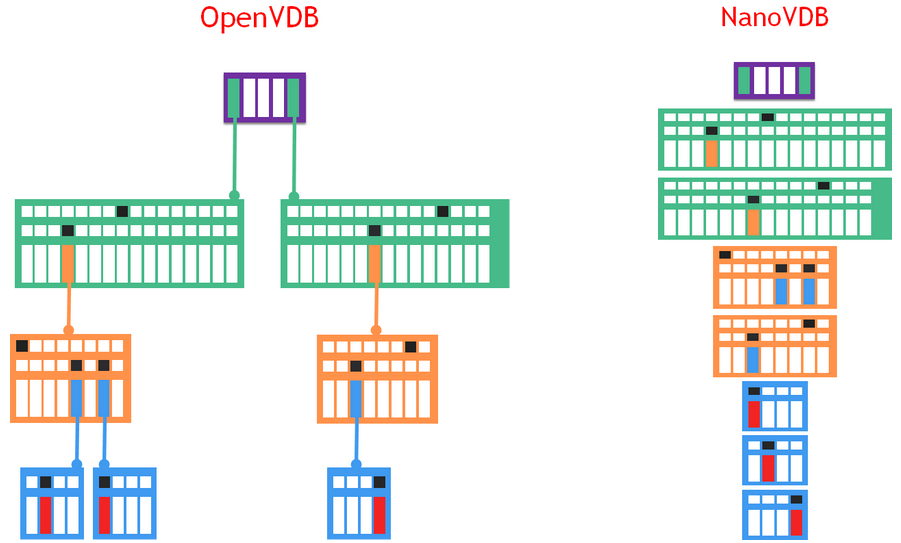
NanoVDB employs a compacted, linearized, read-only representation of the VDB tree structure (Figure 1), which makes it suitable for fast transfer and fast, pointer-less traversal of the tree hierarchy. The data stream is aligned for efficiency and can be used on GPUs and CPUs alike.
Creating a NanoVDB grid
Although the NanoVDB grid is a read-only data structure, the library includes functionality to generate or load data into it.
All of the OpenVDB grid classes—LevelSets, FogVolumes, PointIndexGrids and PointDataGrids—are supported in the NanoVDB representation, and can be loaded directly from an OpenVDB file, that is, a .vdb file. Data can also be loaded or saved to or from NanoVDB’s own file format, which is essentially a dump of its in-memory stream with additional metadata for efficient inspection.
The following code example converts from an OpenVDB file:
openvdb::io::File file(fileName); auto vdbGrid = file.readGrid(gridName); auto handle = nanovdb::openToNanoVDB(vdbGrid);
Although loading from existing OpenVDB data is the typical use case, the included GridBuilder tool allow you to construct NanoVDB grids directly in memory. Some functions for simple primitives are provided to get you started:
// generate a sparse narrow-band level set (i.e. truncated signed distance field) representation of a sphere. auto handle = nanovdb::createLevelSetSphere(50, nanovdb::Vec3f(0));
The following example shows how to generate a small, dense volume (Figure 2) using a lambda function:
nanovdb::GridBuilder builder(0);
auto op = [](const nanovdb::Coord& ijk) -> float {
return menger(nanovdb::Vec3f(ijk) * 0.01f);
};
builder(op, nanovdb::CoordBBox(nanovdb::Coord(-100), nanovdb::Coord(100)));
// create a FogVolume grid called "menger" with voxel-size 1
auto handle = builder.getHandle<>(1.0, nanovdb::Vec3d(0), "menger", nanovdb::GridClass::FogVolume);

Grid handles
The GridHandle is a simple class that holds ownership of the buffer that it allocates, allowing for easy scoping (RAII) of grids.
It also serves to encapsulate the opaque grid data. Even though the grid data itself is templated on a data type such as float, the handle provides a convenient way of accessing the metadata of a grid without knowing what its data type might be. This is useful, as you can determine the GridType purely from the handle.
The following code example verifies that you have a 32-bit floating-point grid containing a level set function:
const nanovdb::GridMetaData* metadata = handle.gridMetaData();
if (!metadata->isLevelSet() || !metadata->gridType() == GridType::Float)
throw std::runtime_error("Not the right stuff!");
Grid buffers
NanoVDB has been designed to support many different platforms, CPU, CUDA and even graphics APIs. To enable this, the data structure is stored inside a flat contiguous memory buffer.
It is simple to make this buffer resident on the CUDA device. For complete control, you could allocate device memory using the CUDA APIs, and then upload the handle’s data into it.
void* d_gridData; cudaMalloc(&d_gridData, handle.size()); cudaMemcpy(d_gridData, handle.data(), handle.size(), cudaMemcpyHostToDevice); const nanovdb::FloatGrid* d_grid = reinterpret_cast<const nanovdb::FloatGrid*>(d_gridData);
NanoVDB’s GridHandle is templated on the buffer type, which is a wrapper for its memory allocation. It defaults to HostBuffer that uses host system memory; however, NanoVDB also provides CudaDeviceBuffer for easy creation of a CUDA device buffer.
auto handle = nanovdb::openToNanoVDB<nanovdb::CudaDeviceBuffer>(vdbGrid); handle->deviceUpload(); const nanovdb::FloatGrid* grid = handle->deviceGrid<float>();
After the data stream is interpreted as a NanoGrid type, the methods can be used to access the data in the grid. For more detailed information, see the documentation for the API in question. Essentially, it mirrors the foundational subset of the read-only methods in OpenVDB.
auto hostOrDeviceOp = [grid] __host__ __device__ (nanovdb::Coord ijk) -> float {
// Note that ReadAccessor (see below) should be used for performance.
return grid->tree().getValue(ijk);
};
It is possible to construct custom buffers for handling different memory-spaces. For more information about examples of creating buffers that can interoperate with graphics APIs, see the samples in the repository.
Rendering

Because NanoVDB grids provide a compact, read-only VDB tree, they work well for rendering tasks. Ray trace a VDB grid into an image. Use a ray-per-thread, and generate rays using a custom rayGenOp functor that takes a pixel offset and creates a world-space ray. The complete code is available in the repository examples.
Given the fact that sampling along a ray exhibits spatial coherency, it can be accelerated by using a ReadAccessor. This caches the tree-traversal stack as the ray steps forward, allowing for bottom-up tree-traversal, which is much faster than a traditional top-down traversal that involves the relatively slow, unbounded root node.
auto renderTransmittanceOp = [image, grid, w, h, rayGenOp, imageOp, dt] __host__ __device__ (int i) {
nanovdb::Ray<float> wRay = rayGenOp(i, w, h);
// transform the ray to the grid's index-space...
nanovdb::Ray<float> iRay = wRay.worldToIndexF(*grid);
// clip to bounds.
if (iRay.clip(grid->tree().bbox()) == false) {
imageOp(image, i, w, h, 1.0f);
return;
}
// get an accessor.
auto acc = grid->tree().getAccessor();
// integrate along ray interval...
float transmittance = 1.0f;
for (float t = iRay.t0(); t < iRay.t1(); t+=dt) {
float sigma = acc.getValue(nanovdb::Coord::Floor(iRay(t)));
transmittance *= 1.0f - sigma * dt;
}
imageOp(image, i, w, h, transmittance );
};

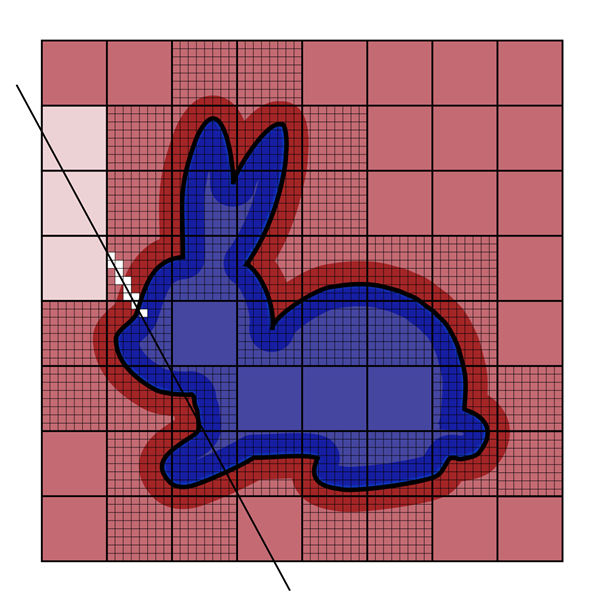
Because ray-intersections with level set grids is a common task, NanoVDB implements a ZeroCrossing function and uses a hierarchical DDA (HDDA) as an efficient way to empty-space skip as part of the root-searching along the ray (Figure 5). For more information about the HDDA, see Hierarchical Digital Differential Analyzer for Efficient Ray-Marching in OpenVDB. Here is the code example:
...
auto acc = grid->tree().getAccessor();
// intersect with zero level-set...
float iT0;
nanovdb::Coord ijk;
float v;
if (nanovdb::ZeroCrossing(iRay, acc, ijk, v, iT0)) {
// convert intersection distance (iT0) to world-space
float wT0 = iT0 * grid->voxelSize();
imageOp(image, i, w, h, wT0);
} else {
imageOp(image, i, w, h, 0.0f);
}
...
Collision detection
Collision detection and resolution are other tasks that lend themselves well to NanoVDB, as they typically require efficient lookup of signed distance values to a solid collision object. Narrow-band level set representations are ideal as they compactly encode the inside/outside topology information (required for collision detection) with a sign. Furthermore, the closest-point transform (required for collision resolution) is easily computed from the gradient of the level set function.
The following code example is a function for handling collisions. The use of the ReadAccessor is useful because the gradient calculation used for the collision-resolution involves multiple fetches in the same spatial vicinity.
auto collisionOp = [grid, positions, velocities, dt] __host__ __device__ (int i) {
nanovdb::Vec3f wPos = positions[i];
nanovdb::Vec3f wVel = velocities[i];
nanovdb::Vec3f wNextPos = wPos + wVel * dt;
// transform the position to a custom space...
nanovdb::Vec3f iNextPos = grid.worldToIndexF(wNextPos);
// the grid index coordinate.
nanovdb::Coord ijk = nanovdb::Coord::Floor(iNextPos);
// get an accessor.
auto acc = grid->tree().getAccessor();
if (tree.isActive(ijk)) { // are you inside the narrow band?
float wDistance = acc.getValue(ijk);
if (wDistance <= 0) { // are you inside the levelset?
// get the normal for collision resolution.
nanovdb::Vec3f normal(wDistance);
ijk[0] += 1;
normal[0] += acc.getValue(ijk);
ijk[0] -= 1;
ijk[1] += 1;
normal[1] += acc.getValue(ijk);
ijk[1] -= 1;
ijk[2] += 1;
normal[2] += acc.getValue(ijk);
normal.normalize();
// handle collision response with the surface.
collisionResponse(wPos, wNextPos, normal, wDistance, wNextPos, wNextVel);
}
}
positions[i] = wNextPos;
velocities[i] = wNextVel;
};
Again, the complete code is available in the repository.
Benchmarks
NanoVDB was developed to run equally well on both the host and device. Using the extended lambda support in modern CUDA, you can easily run the same code on both platforms.
This section includes benchmarks comparing the performance of raytracing and collision detection on both Intel Thread-Building-Blocks and NVIDIA CUDA. The timings are shown in milliseconds, and were generated on a Xeon E5-2696 v4 x2 – (88 CPU threads), compared to an NVIDIA RTX 8000. The FogVolume used was the bunny_cloud, and the LevelSet was the dragon dataset. Both are downloadable from the OpenVDB website. Rendering was performed at a resolution of 1024 x 1024. The collision test simulated 100 million ballistic particles.
While the benchmark (Figures 6 and the following table) shows the benefit of NanoVDB’s efficient representation for speeding up OpenVDB on the CPU, it really highlights the benefit of using GPU for read-only access to the VDB data for collision detection and raytracing.
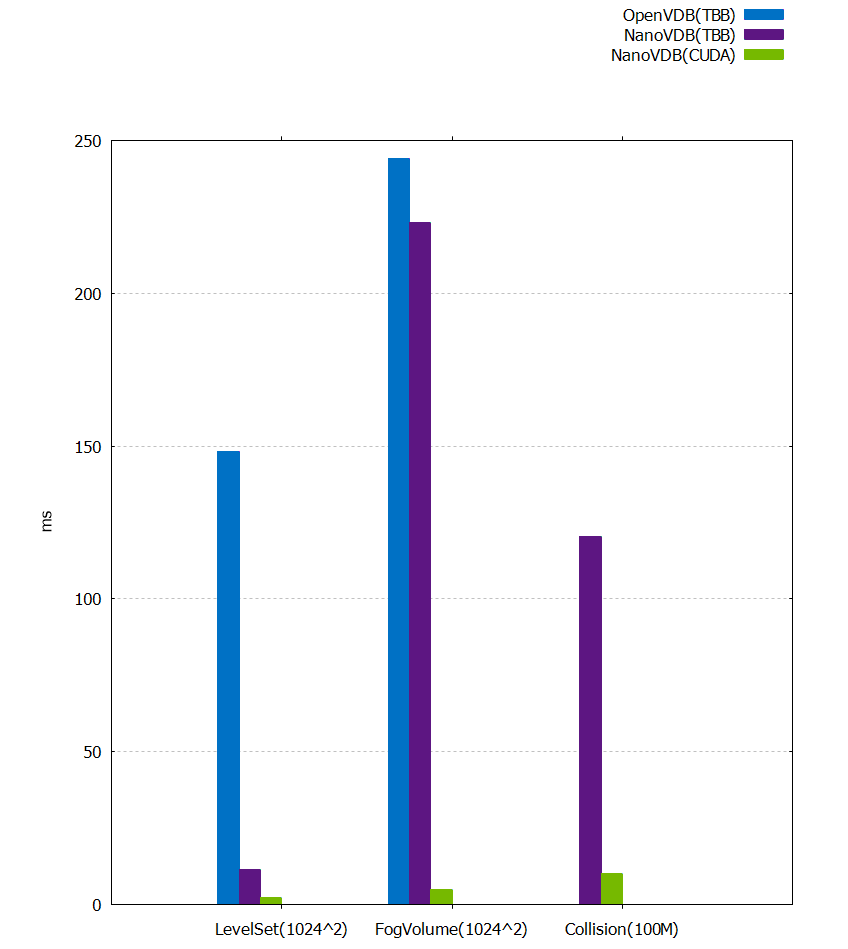
| OpenVDB (TBB) | NanoVDB (TBB) | NanoVDB (CUDA) | CUDA Speed-up | |
| LevelSet | 148.182 | 11.554 | 2.427 | 5X |
| FogVolume | 243.985 | 223.195 | 4.971 | 44X |
| Collision | – | 120.324 | 10.131 | 12X |
Conclusion
NanoVDB is a small yet powerful library for accelerating certain OpenVDB applications through the use of GPUs. The open source repository is available now! To download the source code, build the examples, and experience the power that the GPU-accelerated NanoVDB can offer your sparse volume workflows, see NanoVDB.
