
NVIDIA cuDSS is a first-generation sparse direct solver library designed to accelerate engineering and scientific computing. cuDSS is increasingly adopted in data centers and other environments and supports single-GPU, multi-GPU and multi-node (MGMN) configurations.
cuDSS has become a key tool for accelerating computer-aided engineering (CAE) workflows and scientific computations across multiple domains such as structural engineering, fluid dynamics, electromagnetics, circuit simulation, optimization, and AI-assisted engineering problems.
This post highlights some of the key performance and usability features delivered in cuDSS v0.4.0 and cuDSS v0.5.0, as summarized in Table 1. cuDSS v0.4.0 achieves a significant performance boost for factorization and solve steps, while also introducing several new features, including the memory prediction API, automatic hybrid memory selection, and variable batch support. cuDSS v0.5.0 adds host execution mode, which is particularly beneficial for smaller matrices, and demonstrated substantial performance improvements using hybrid memory mode and host multithreading for analysis phase, an area that is typically challenging to parallelize effectively.
| cuDSS v0.4.0 release | cuDSS v0.5.0 release |
| PIP wheel and Conda support Factorization and solve performance improvements (up to 10x) for single and multi-GPU when factors have dense parts Memory prediction API Automatic normal/hybrid memory mode selection Variable (non-uniform) batch support (variable N, NNZ, NRHS, LD) | Host execution mode (parts of computations on the host) for smaller matrices Host multithreading (currently only for the reordering) with user-defined threading backend New pivoting approach (static pivoting with scaling) Improved performance and memory requirements for hybrid memory mode |
Feature highlights
This section focuses on notable usability enhancements and performance improvements.
Memory prediction API
The memory prediction API is important for users who need to know the precise amount of device and host memory required by cuDSS before reaching the most memory-intensive phase (numerical factorization).
It is especially useful in scenarios where device memory may be insufficient—either when solving large linear systems or when the application has a limited memory budget for cuDSS. In either case, it is recommended to enable hybrid memory mode before the analysis phase.
Note that if hybrid memory mode is enabled but everything fits within the available device memory (whether based on the user-defined limit or GPU capacity), cuDSS will automatically detect this and switch to the faster default memory mode.
A typical call sequence for solving a linear system with cuDSS is as follows:
- Analysis (reordering and symbolic factorization)
- Numerical factorization (where the values of the factors are allocated and computed)
- Solving
With the introduction of memory prediction, users can now query the amount of device and host memory required for the chosen mode (either default or hybrid memory) after the analysis phase, as well as the minimum memory required for hybrid memory mode. As the sample below demonstrates, the query is a single call of cudssDataGet with CUDSS_DATA_MEMORY_ESTIMATES that writes an output in a small fixed-size array.
/*
* After cudssExecute(..., CUDSS_PHASE_ANALYSIS, ,,,)
*/
int64_t memory_estimates[16] = {0};
cudssDataGet(cudssHandle, solverData, CUDSS_DATA_MEMORY_ESTIMATES,
&memory_estimates, sizeof(memory_estimates);
/* memory_estimates[0] - permanent device memory
* memory_estimates[1] - peak device memory
* memory_estimates[2] - permanent host memory
* memory_estimates[3] - peak host memory
* memory_estimates[4] - minimum device memory for the hybrid memory mode
* memory_estimates[5] - maximum host memory for the hybrid memory mode
* memory_estimates[6,...,15] - reserved for future use
*/
To see the full sample code that makes use of this feature, visit the NVIDIA/CUDALibrarySamples GitHub repo.
Non-uniform batch API
In scenarios where the application requires solving multiple linear systems, and each system individually is not large enough to fully saturate the GPU, performance can be enhanced through batching. There are two types of batching: uniform and non-uniform. Unlike uniform batches, non-uniform batches do not impose restrictions on the dimensions or sparsity patterns of the matrices.
cuDSS v0.4.0 introduces support for non-uniform batches. The opaque cudssMatrix_t objects can represent either a single matrix or a batch of matrices and thus the only part that needs to be changed is how the matrix objects are created and modified.
To create batches of dense or sparse matrices, v0.4.0 introduced new APIs cudssMatrixCreateBatchDn or cudssMatrixCreateBatchCsr. For modifying the matrix data are the similarly added APIs cudssMatrixSetBatchValues and cudssMatrixSetBatchCsrPointers as well as cudssMatrixGetBatchDn and cudssMatrixGetBatchCsr. cuDSS v0.5.0 modifies cudssMatrixFormat_t which can now be queried using cudssMatrixGetFormat to determine whether cudssMatrix_t object is a single matrix or a batch.
Once the batches of matrices are created, they can be passed to the main calls of cudssExecute in the exact same way as if they were single matrices. The sample below demonstrates the use of new batch APIs to create batches of dense matrices for the solution and right-hand sides, and a batch of sparse matrices for As.
/*
* For the batch API, scalar arguments like nrows, ncols, etc.
* must be arrays of size batchCount of the specified integer type
*/
cudssMatrix_t b, x;
cudssMatrixCreateBatchDn(&b, batchCount, ncols, nrhs, ldb, batch_b_values, CUDA_R_32I, CUDA_R_64F, CUDSS_LAYOUT_COL_MAJOR);
cudssMatrixCreateBatchDn(&x, batchCount, nrows, nrhs, ldx, batch_x_values, CUDA_R_32I, CUDA_R_64F, CUDSS_LAYOUT_COL_MAJOR);
cudssMatrix_t A;
cudssMatrixCreateBatchDn(&A, batchCount, nrows, ncols, nnz, batch_csr_offsets, NULL, batch_csr_columns, batch_csr_values, CUDA_R_32I, CUDA_R_64F, mtype, mview, base);
/*
* The rest of the workflow remains the same, incl. calls to cudssExecute() with batch matrices A, b and x
*/
To see the full sample code that makes use of this feature, visit the NVIDIA/CUDALibrarySamples GitHub repo.
Host multithreading API
Although most of the compute- and memory-intensive parts of cuDSS are executed on the GPU, some important tasks are still executed on the host. Prior to v0.5.0, cuDSS did not support multithreading (MT) on the host, and host execution was always single-threaded. The new release introduces support for arbitrary user-defined threading runtimes (such as pthreads, OpenMP, and thread pools), offering flexibility similar to how support was introduced for user-defined communication backends in the MGMN mode in cuDSS v0.3.0.
Among the tasks executed on the host, reordering (a critical part of the analysis phase) often stands out, as it can take a significant portion of the total execution time (analysis plus factorization plus solve). To address this common bottleneck in direct sparse solvers, cuDSS v0.5.0 introduces both general MT support on the host and a multithreaded version of reordering. Note that this is available only for the CUDSS_ALG_DEFAULT reordering algorithm.
As with the MGMN mode, the new MT mode is optional and does not introduce any new dependencies to the user application if not used. Enabling this feature in your application is simple—just set the name of the shim threading layer library using cudssSetThreadingLayer and (optionally) specify the maximum number of threads that cuDSS is allowed to use, as shown in the following sample:
/*
* Before cudssExecute(CUDSS_PHASE_ANALYSIS)
* thrLibFileName - filename to the cuDSS threading layer library
* If NULL then export CUDSS_THREADING_LIB = ‘filename’
*/
cudssSetThreadingLayer(cudssHandle, thrLibFileName);
/*
* (optional)Set number of threads to be used by cuDSS
*/
int32_t nthr = ...;
cudssConfigSet(cudssHandle, solverConfig, CUDSS_CONFIG_HOST_NTHREADS,
&nthr, sizeof(nthr);
To see the full sample code that makes use of this feature, visit the NVIDIA/CUDALibrarySamples GitHub repo.
Host execution
While the primary objective of cuDSS is to enable GPU acceleration for sparse direct solver functionality, for tiny and small matrices (which typically don’t have enough parallelism to saturate a GPU) an extensive use of the GPU can bring a non-negligible overhead. This can sometimes even dominate the total runtime.
To make cuDSS a more universal solution, v0.5.0 introduces the host execute mode, which enables factorization and solve phases on the host. When enabled, cuDSS will use a heuristic size-based dispatch to determine whether to perform part of the computations (during factorization and solve phases) on the host or on the device.
Additionally, when hybrid execution mode is enabled, users can pass host buffers for the matrix data which saves the needless memory transfers from the host to the device. Host execution mode doesn’t give cuDSS capabilities of a fully-fledged CPU solver, but helps to optionally remove the unwanted memory transfers and improve performance for small matrices.
The following sample demonstrates how to turn on hybrid execution mode.
/*
* Before cudssExecute(CUDSS_PHASE_ANALYSIS)
*/
int hybrid_execute_mode = 1;
cudssConfigSet(solverConfig, CUDSS_CONFIG_HYBRID_EXECUTE_MODE,
&hybrid_execute_mode, sizeof(hybrid_execute_mode);
To see the full sample code that makes use of this feature, visit the NVIDIA/CUDALibrarySamples GitHub repo.
Performance improvements of cuDSS v0.4.0 and v0.5.0
cuDSS v0.4.0 and v0.5.0 introduced significant performance improvements across several types of workloads.
In v0.4.0, the factorization and solve steps are accelerated by detecting when parts of the triangular factors become dense and leveraging more efficient dense BLAS kernels for those parts. The speedup achieved through this optimization depends largely on the symbolic structure of the factors, which in turn is influenced by the original matrix and the reordering permutation.
Figure 1 illustrates the performance improvement of v0.4.0 over v0.3.0, based on a large collection of matrices from the SuiteSparse Matrix Collection, analyzed on the NVIDIA H100 GPU.
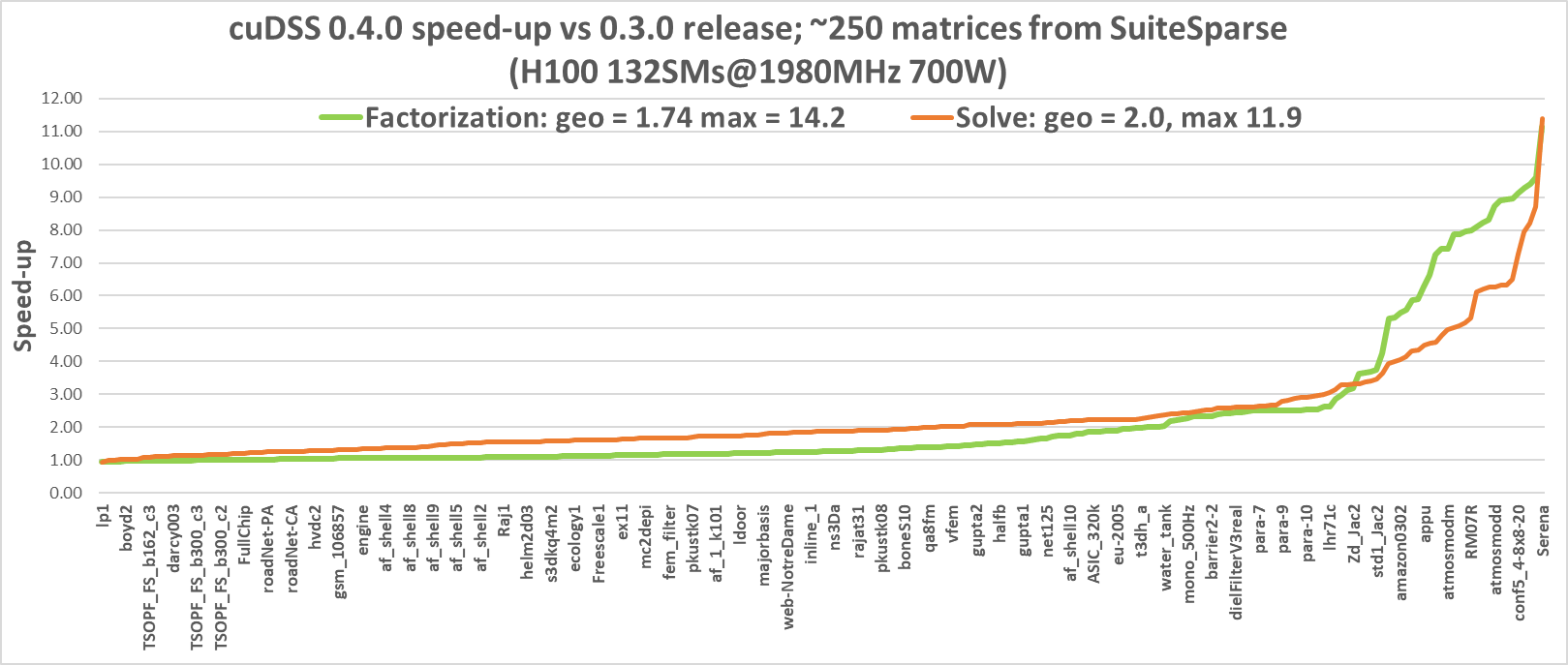
As shown in the chart, both the factorization and solve phases saw substantial improvements, with geometric means of 1.74 and 2.0, respectively. Some matrices with relatively sparse triangular factors did not show significant speedups. However, matrices like Serena, conf5_4_8x8_20 and atmosmodd (which come from various types of HPC applications) experienced speedups of more than 8x in the factorization phase and more than 6x in the solve phase.
The analysis phase also saw significant speedup, thanks to the multithreaded reordering introduced in cuDSS v0.5.0. Figure 2 compares the performance of the analysis phase between v0.5.0 and v0.4.0, using the same set of matrices from the SuiteSparse Matrix Collection.
The performance improvement arises from the fact that v0.4.0 used a single-threaded reordering implementation, while v0.5.0 leverages multiple CPU threads (cores) on the host. While it’s well-known that state-of-the-art reordering algorithms are notoriously difficult to parallelize efficiently, cuDSS v0.5.0 makes good use of multiple CPU cores, resulting in a solid geometric mean speedup of 1.98, with the maximum improvement reaching 4.82.
Note that the analysis phase includes both the (optionally multithreaded) reordering and symbolic factorization, which is performed on the GPU. Therefore, the actual speedup for the reordering part is likely even higher than what the chart indicates.

cuDSS v0.5.0 further optimizes the performance of the hybrid memory mode, which was first introduced in v0.3.0 This feature allows part of the internal arrays used within cuDSS to reside on the host, enabling the solution of systems that don’t fit into the memory of a single GPU. It works particularly well on NVIDIA Grace-based systems, thanks to the significantly higher memory bandwidth between the CPU and GPU.
Figure 3 presents the performance speedup for the factorization and solve phases with cuDSS 0.5.0, comparing an NVIDIA Grace Hopper system (Grace CPU plus NVIDIA H100 GPU) against an x86 system (Intel Xeon Platinum 8480CL, 2S) plus NVIDIA H100 GPU, using a set of large matrices.

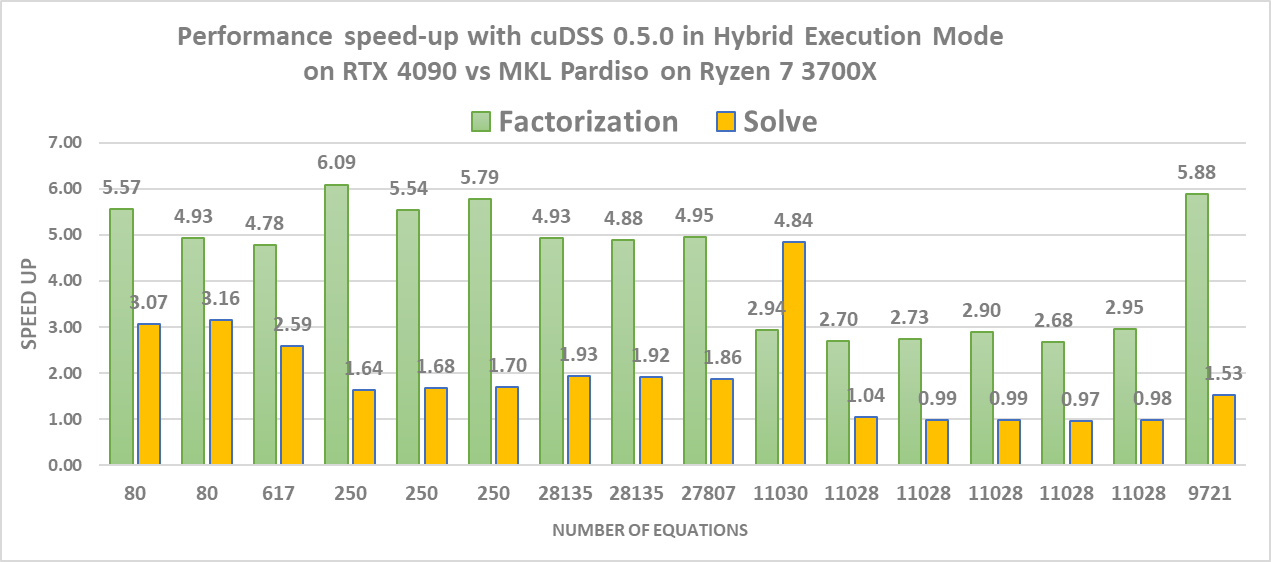
As previously mentioned, v0.5.0 introduces the hybrid execution mode, which improves performance of cuDSS for small matrices. Figure 4 shows the speedup of the hybrid execution mode against the CPU solver (Intel MKL PARDISO) for the factorization and solve phases.
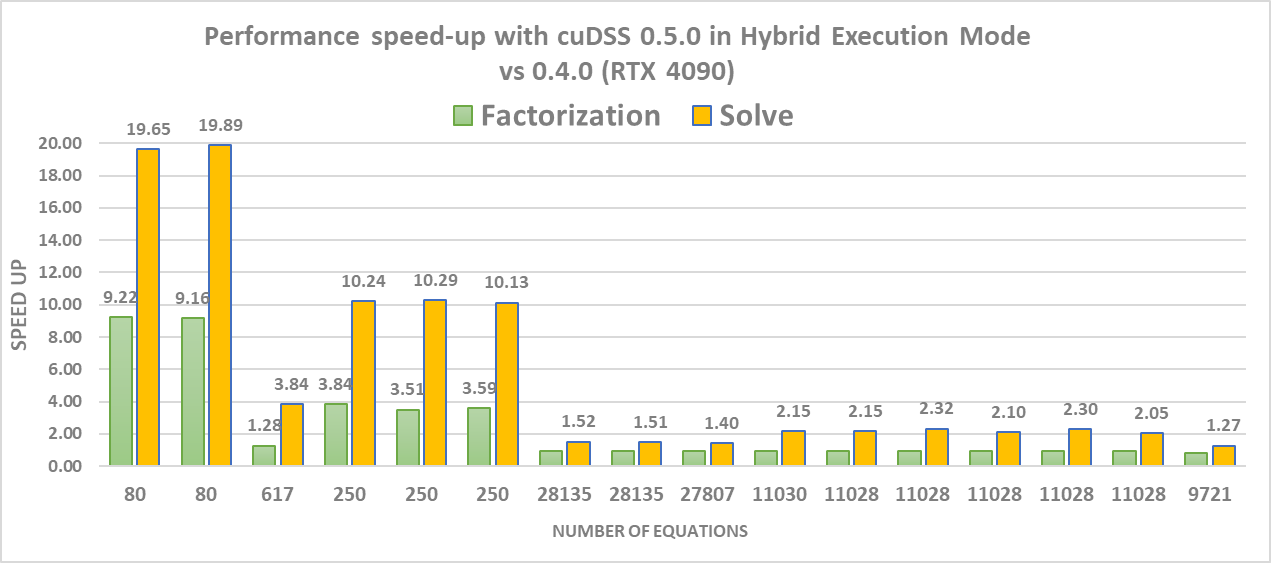
Finally, Figure 5 shows the speedup of the new hybrid execution mode (cuDSS v0.5.0) compared to the default mode (cuDSS v0.4.0) for the factorization and solve phases on a set of small matrices. While the speedup of the factorization phase is significant only for really small matrices, the solve phase delivers speedups for systems with up to 30K equations. This can be explained by the fact that the solve phase has less work compared to the factorization phase and cannot make good use of a GPU for the tested matrices.
Summary
NVIDIA cuDSS v0.4.0 and v0.5.0 releases provide several new enhancements that significantly improve performance. Highlights include general speedups in factorization and solving, a hybrid memory and execution mode, host multithreading, and support for non-uniform batch sizes. In addition to our continued investment in performance, we will consistently enhance our APIs to expand functionality, providing users with greater flexibility and fine-grained control.
Ready to get started? Download NVIDIA cuDSS v0.5.0.
To learn more, check out the cuDSS v0.5.0 release notes and the following previous posts:
- NVIDIA cuDSS Library Removes Barriers to Optimizing the US Power Grid
- Spotlight: Honeywell Accelerates Industrial Process Simulation with NVIDIA cuDSS
Join the conversation and provide feedback in the NVIDIA Developer Forum.
