Solving Large-Scale Linear Sparse Problems with NVIDIA cuDSS
Solving large-scale problems in Electronic Design Automation (EDA), Computational Fluid Dynamics (CFD), and advanced optimization workflows has become the norm...
NVIDIA cuDSS Advances Solver Technologies for Engineering and Scientific Computing
NVIDIA cuDSS is a first-generation sparse direct solver library designed to accelerate engineering and scientific computing. cuDSS is increasingly adopted in...
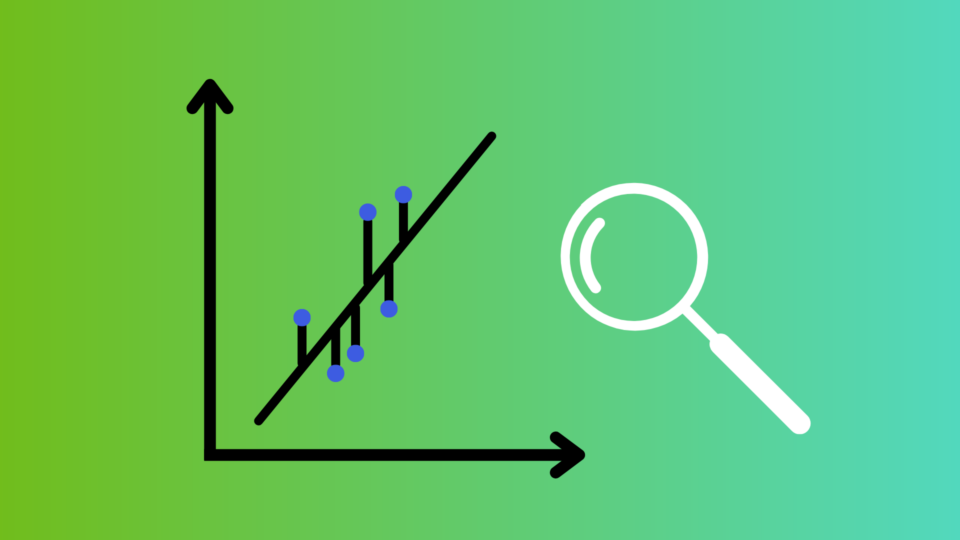
A Comprehensive Overview of Regression Evaluation Metrics
As a data scientist, evaluating machine learning model performance is a crucial aspect of your work. To do so effectively, you have a wide range of statistical...
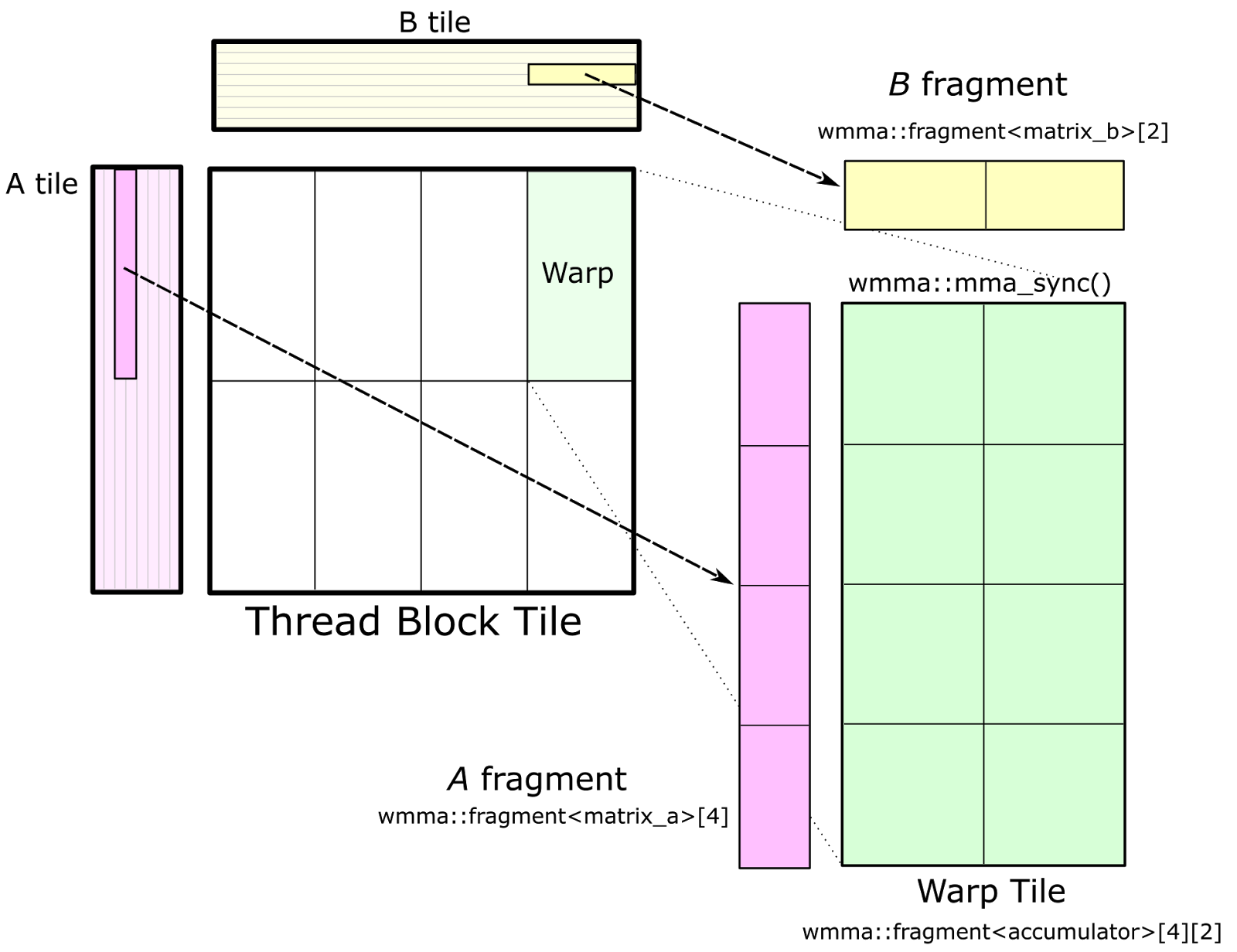
Update May 21, 2018: CUTLASS 1.0 is now available as Open Source software at the CUTLASS repository. CUTLASS 1.0 has changed substantially from our preview...
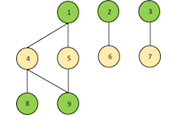
Graph Coloring: More Parallelism for Incomplete-LU Factorization
In this blog post I will briefly discuss the importance and simplicity of graph coloring and its application to one of the most common problems in sparse...
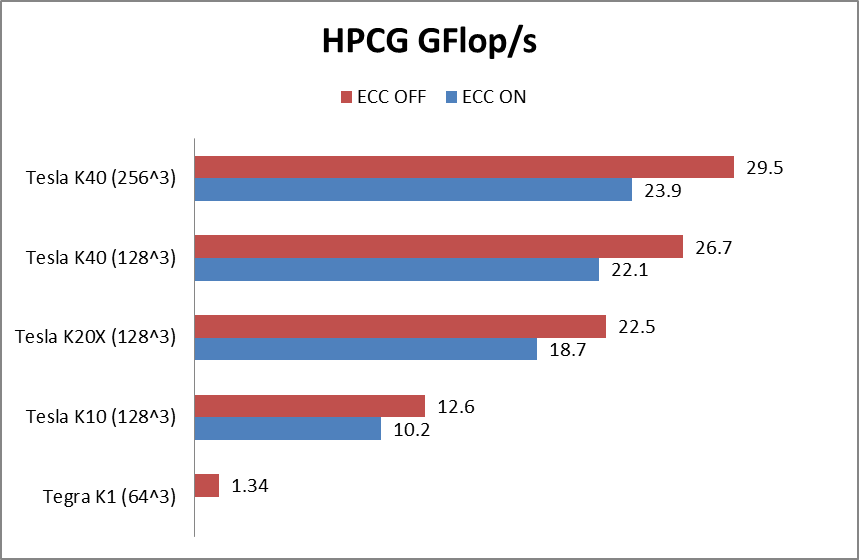
Optimizing the High Performance Conjugate Gradient Benchmark on GPUs
[This post was co-written by Everett Phillips and Massimiliano Fatica.] The High Performance Conjugate Gradient Benchmark (HPCG) is a new benchmark intended to...