As the size and complexity of large language models (LLMs) continue to grow, NVIDIA is today announcing updates to the NeMo framework that provide training speed-ups of up to 30%.
These updates–which include two trailblazing techniques and a hyperparameter tool to optimize and scale training of LLMs on any number of GPUs–offer new capabilities to train and deploy models using the NVIDIA AI platform.
BLOOM, the world’s largest open-science, open-access multilingual language model, with 176 billion parameters, was recently trained on the NVIDIA AI platform, enabling text generation in 46 languages and 13 programming languages. The NVIDIA AI platform has also powered one of the most powerful transformer language models, with 530 billion parameters, Megatron-Turing NLG model (MT-NLG).
Recent advances in LLMs
LLMs are one of today’s most important advanced technologies, involving up to trillions of parameters that learn from text. Developing them, however, is an expensive, time-consuming process that demands deep technical expertise, distributed infrastructure, and a full-stack approach.
Yet their benefit is enormous in advancing real-time content generation, text summarization, customer service chatbots, and question-answering for conversational AI interfaces.
To advance LLMs, the AI community is continuing to innovate on tools such as Microsoft DeepSpeed, Colossal-AI, Hugging Face BigScience, and Fairscale–which are powered by the NVIDIA AI platform, involving Megatron-LM, Apex, and other GPU-accelerated libraries.
These new optimizations to the NVIDIA AI platform help solve many of the existing pain points across the entire stack. NVIDIA looks forward to working with the AI community to continue making the power of LLMs accessible to everyone.
Build LLMs faster
The latest updates to the NeMo framework offer 30% speed-ups for training GPT-3 models ranging in size from 22 billion to 1 trillion parameters. Training can now be done on 175 billion-parameter models on 300 billion tokens using 1,024 NVIDIA A100 GPUs in just 24 days–reducing time to results by 10 days, or some 250,000 hours of GPU computing, prior to these new releases.
The NeMo Framework is a quick, efficient, and easy-to-use end-to-end containerized framework for collecting data, training large-scale models, evaluating models against industry-standard benchmarks, and for inference with state-of-the-art latency and throughput performance.
It makes LLM training and inference easy and reproducible on a wide range of GPU cluster configurations. Currently, these capabilities are available to early access customers to run on NVIDIA DGX SuperPODs, and NVIDIA DGX Foundry as well as in Microsoft Azure cloud. Support for other cloud platforms will be available soon.
You can try the features on NVIDIA LaunchPad, a free program that provides short-term access to a catalog of hands-on labs on NVIDIA-accelerated infrastructure.
The NeMo framework is an open-source framework for building high-performance and flexible applications for conversational AI, speech AI, and biology.
Two new techniques to speed-up LLM training
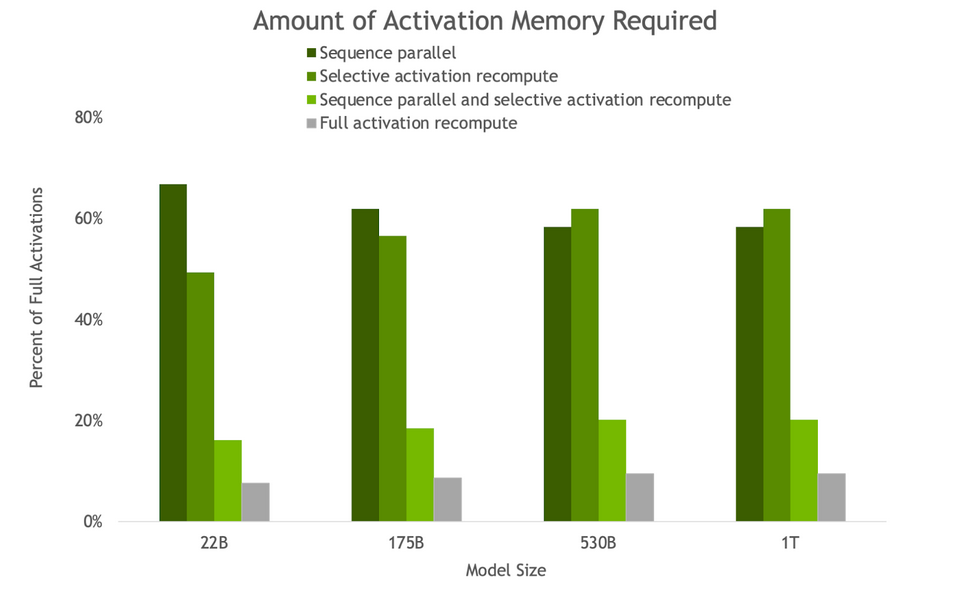
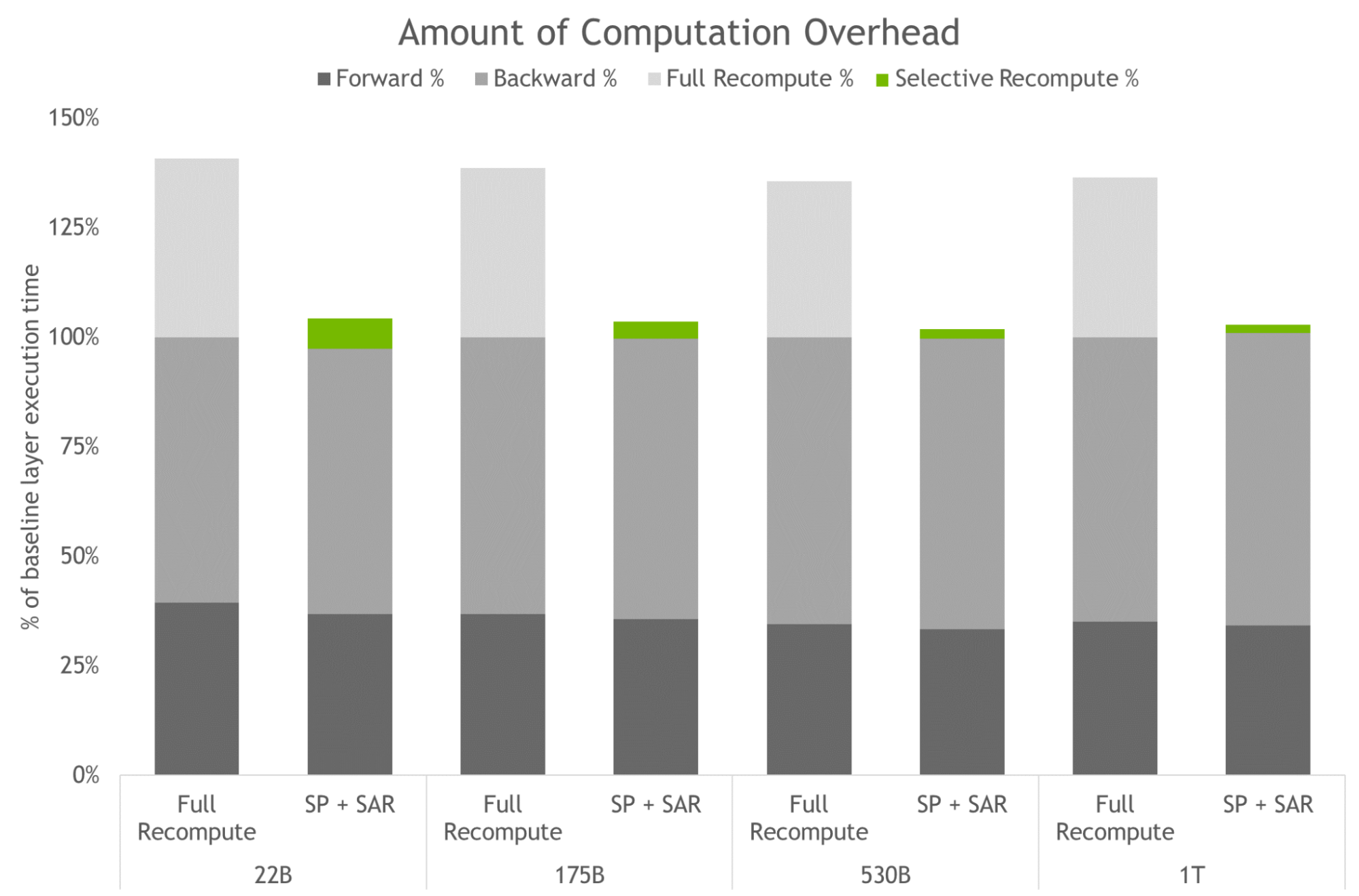
Two new techniques included in the updates that optimize and scale the training of LLMs are sequence parallelism (SP) and selective activation recomputation (SAR).
Sequence parallelism expands tensor-level model parallelism by noticing that the regions of a transformer layer that haven’t previously been parallelized are independent along the sequence dimension.
Splitting these layers along the sequence dimension enables distribution of the compute and, most importantly, the activation memory for these regions across the tensor parallel devices. Since the activations are distributed, more activations can be saved for the backward pass instead of recomputing them.
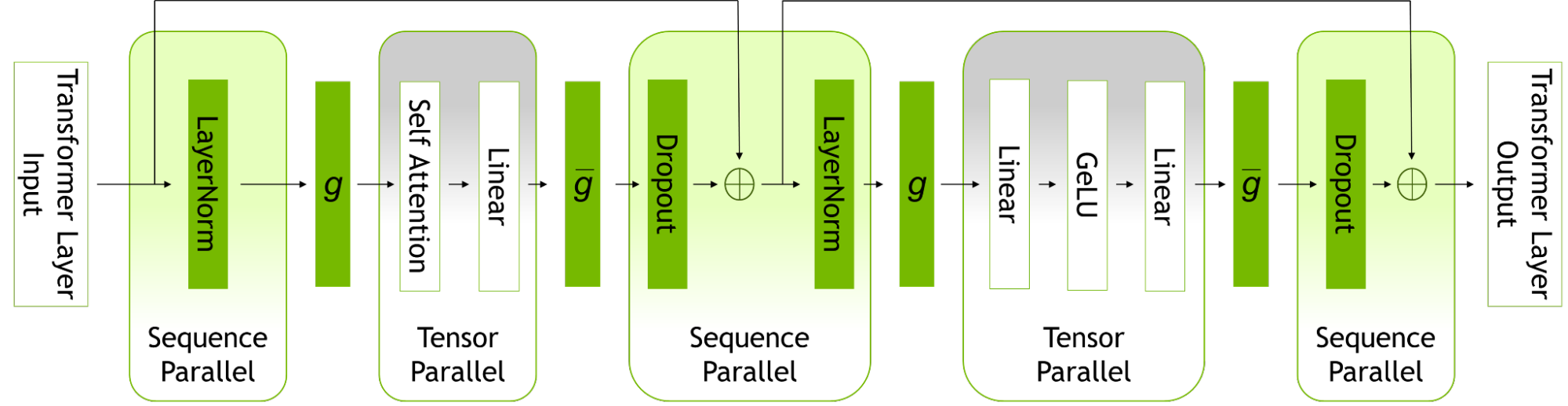
Selective activation recomputation improves cases where memory constraints force the recomputation of some, but not all, of the activations, by noticing that different activations require different numbers of operations to recompute.
Instead of checkpointing and recomputing full transformer layers, it’s possible to checkpoint and recompute only parts of each transformer layer that take up a considerable amount of memory but aren’t computationally expensive to recompute.
For more information, see Reducing Activation Recomputation in Large Transformer Models.
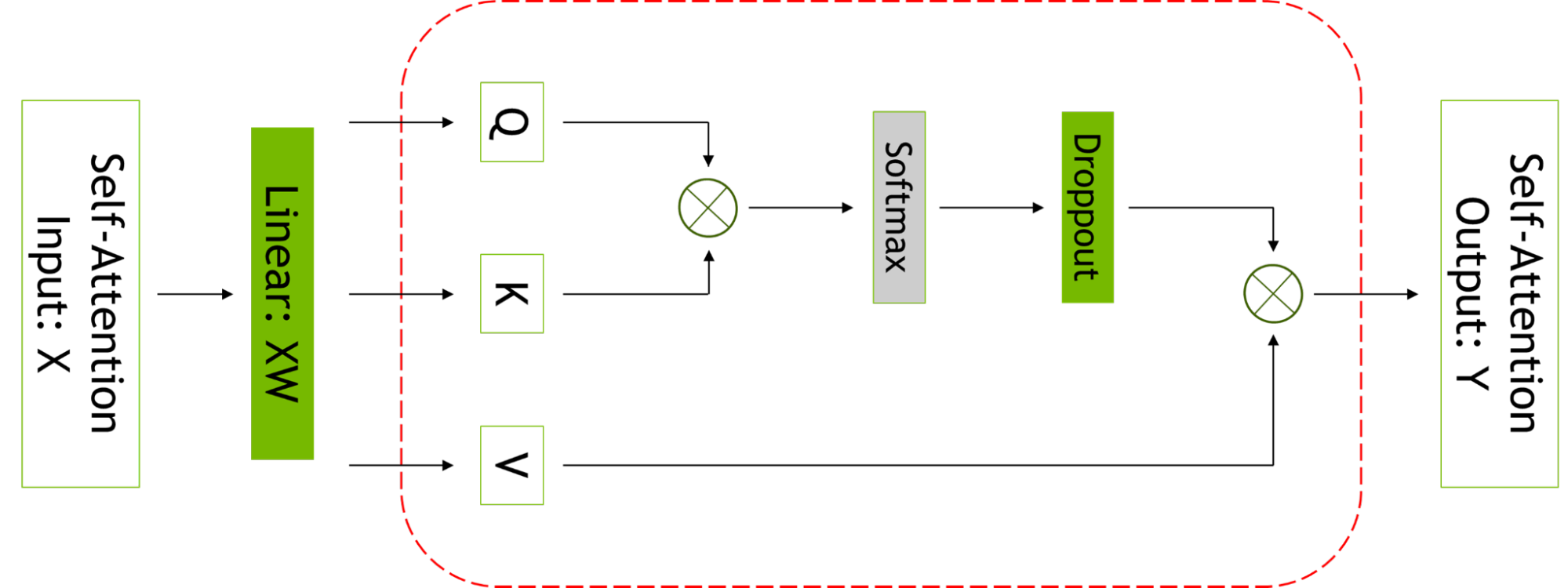
Accessing the power of LLMs also requires a highly optimized inference strategy. Users can easily use the trained models for inference, and optimize for different use cases using p-tuning and prompt tuning capabilities.
These capabilities are parameter-efficient alternatives to fine-tuning and allow LLMs to adapt to new use cases without the heavy-handed approach of fine-tuning the full pretrained models. In this technique, the parameters of the original model are not altered. As such, catastrophic ‘forgetting’ issues associated with fine-tuning models are avoided.
For more information, see Adapting P-Tuning to Solve Non-English Downstream Tasks.
New hyperparameter tool for training and inference
Finding model configurations for LLMs across distributed infrastructure is a time consuming process. The NeMo framework introduces a hyperparameter tool to automatically find optimal training and inference configurations, with no code changes required. This enables LLMs to be trained to convergence for inference from day one, eliminating time wasted searching for efficient model configurations.
It uses heuristics and empirical grid search across distinct parameters to find configurations with best throughputs: data parallelism, tensor parallelism, pipeline parallelism, sequence parallelism, micro batch size, and number of activation checkpointing layers (including selective activation recomputation).
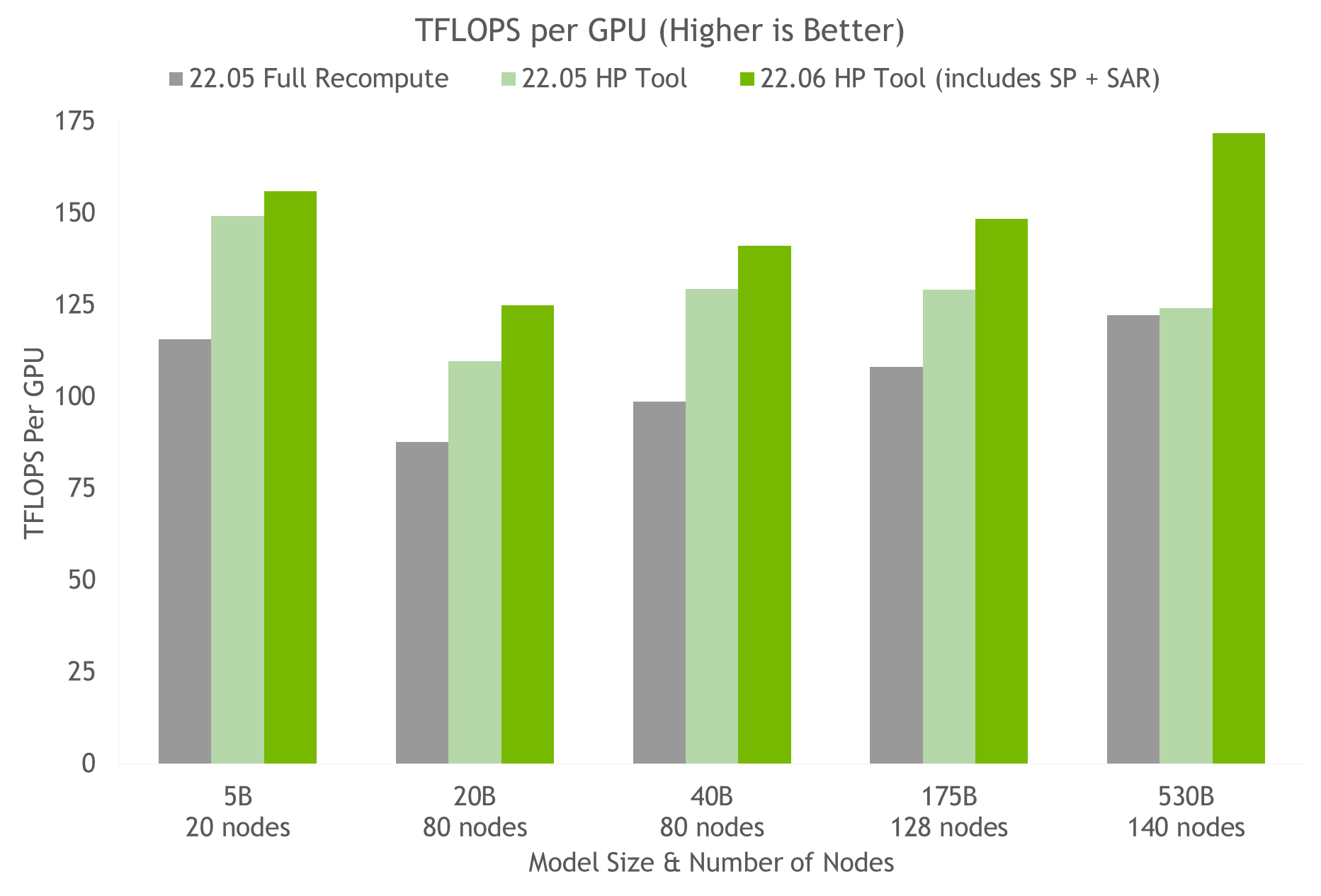
Using the hyperparameter tool and NVIDIA testing on containers on NGC, we arrived at the optimal training configuration for a 175B GPT-3 model in under 24 hours (see Figure 5). When compared with a common configuration that uses full activation recomputation, we achieve a 20%-30% throughput speed-up. Using the latest techniques, we achieve an additional 10%-20% speed-up in throughput for models with more than 20B parameters.
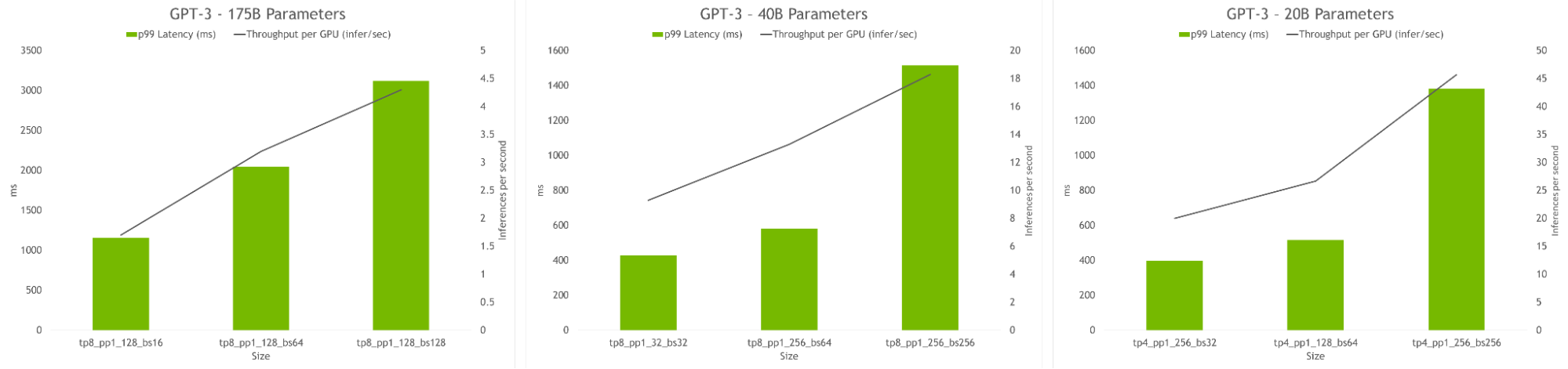
The hyperparameter tool also allows finding model configurations that achieve highest throughput or lowest latency during inference. Latency and throughput constraints can be provided to serve the model, and the tool will recommend suitable configurations.
To explore the latest updates to the NVIDIA AI platform for LLMs, apply for early access to the NeMo framework. Enterprises can also try the NeMo framework on NVIDIA LaunchPad, available at no charge.
To learn more about large deep neural networks, sign up for the new NVIDIA Deep Learning Institute course, Model Parallelism: Building and Deploying Large Neural Networks. You can also take the Model Parallelism workshop at GTC 2022.
Acknowledgements
We would like to thank Vijay Korthikanti, Jared Casper, Virginia Adams, and Yu Yao for their contributions to this post.