
New research from a group of scientists at UC Berkeley is giving data-poor regions across the globe the power to analyze data-rich satellite imagery. The study, published in Nature Communications, introduces a machine learning model that resource-constrained organizations and researchers can use to draw out regional socioeconomic and environmental information. Being able to evaluate local resources remotely could help guide effective interventions and benefit communities globally.
“We saw that many researchers—ourselves included—were passing up on this valuable data source because of the complexities and upfront costs associated with building computer vision pipelines to translate raw pixel values into useful information. We thought that there might be a way to make this information more accessible while maintaining the predictive skill offered by state-of-the-art approaches. So, we set about constructing a way to do this,” said coauthor Ian Bolliger, who worked on the study while pursuing a PhD in Energy and Resources at UC Berkeley.
At any given time, hundreds of image-collecting satellites circle the earth, sending massive amounts of information to databases daily. This data holds valuable insight into global challenges, including health, economic, and environmental conditions—even offering a look into data-poor and remote regions.
Combining satellite imagery with machine learning (SIML) has become an effective tool for turning these raw data streams into usable information. Researchers have used SIML on a broad-range of studies, from calculating poverty rates, to water availability, to educational access. However, most SIML projects capture information on a narrow topic, creating data tailored to a specific study and location.
The researchers sought to create an accessible system capable of analyzing and organizing satellite images from multiple sources while lowering compute requirements. The tool they created, called the Multi-Task Observation using Satellite Imagery & Kitchen Sinks (MOSAIKS), does this by using a relatively simpler and more efficient unsupervised machine learning algorithm.
“We designed MOSAIKS keeping in mind that a single satellite image simultaneously holds information about many different prediction variables (like forest cover or population density.) We chose to use an unsupervised embedding of the imagery to create a statistical summary of each image. The unsupervised nature of the featurization step makes the learning and prediction steps of the pipeline very fast, while the specifics of how those features are computed from imagery are well suited to satellite image data,” said coauthor Esther Rolf, a Ph.D. student in computer science at Berkeley.
To develop the model, the researchers used CUDA-accelerated NVIDIA V100 Tensor Core GPUs on AWS. The publicly available CodeOcean capsule, which provides code, compute, and storage, for anyone to interactively run, uses NVIDIA GPUs.
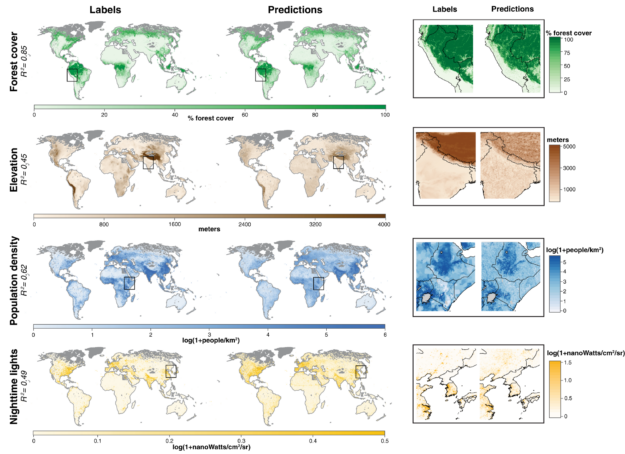
“We want policymakers in resource-constrained settings and without specialized computational expertise to be able to painlessly gather satellite imagery, build a model of a variable they care about (say, the presence of adequate sanitation systems), and test whether this model is actually performing well. If they can do this, it will dramatically improve the usefulness of this information in implementing policy objectives,” Bolliger said.
Currently the team is developing and testing a public-facing web interface tool, making it easy for people to query for MOSAIKS features in user-specified locations. The researchers encourage interested researchers to sign up for the beta version.
Read the full article in Nature Communications >>
Read more >>
