
Machine Learning (ML) is increasingly used to make decisions across many domains like healthcare, education, and financial services. Since ML models are being used in situations that have a real impact on people, it is critical to understand what features are being considered for the decisions to eliminate or minimize the impact of biases.
Model Interpretability aids developers and other stakeholders to understand model characteristics and the underlying reasons for the decisions, thus making the process more transparent. Being able to interpret models can help data scientists explain the reasons for decisions made by their models, adding value and trust to the model. In this post, we discuss:
- The Need for Model Interpretability
- Interpretability using SHAP
- GPU-accelerated SHAP implementation from RAPIDS
- Using SHAP for model explanation on Azure Machine Learning with a demo notebook.
Why do we need Interpretability?
There are six main reasons that justify the need for model interoperability in machine learning:
- Understanding fairness issues in the model
- Precise understanding of the objectives
- Creating robust models
- Debugging models
- Explaining outcomes
- Enabling auditing
Understanding fairness issues in the model: An interpretable model can explain the reasons for choosing the outcome. In social contexts, these explanations will inevitably reveal inherent biases towards underrepresented groups. The first step to overcoming these biases is to see how they manifest.
A more precise understanding of the objectives: The need for explanations also arises from our gaps in understanding the problem fully. Explanations are one of the ways to ensure that the effects of the gaps are visible to us. It helps in understanding whether the models’ predictions are matching the stakeholders’ or experts’ objectives.
Creating Robust Models: Interpretable models can help us understand why there’s some variance in the predictions, which can help make them more robust and eliminate extreme and unintended changes in forecasts; and why the errors were made. Increasing robustness can also help build trust in the model as it doesn’t produce dramatically different results.
Model interpretability can also help debug models, explain outcomes to stakeholders, and enable auditing to meet regulatory compliances.
It is important to note that there are instances where interpretability might be less important. For example, there might be cases where adding interpretable models can aid adversaries to cheat the systems.
Now that we understand what interpretability is and why we need it, let’s look at one way of implementing it that has become very popular recently.
Interpretability using SHAP and cuML’s SHAP
There are different methods that aim at improving model interpretability; one such model-agnostic method is SHAPley Values. It’s a method derived from coalitional game theory to provide a way to distribute the “payout” across the features fairly. In the case of Machine Learning models, the payout is the predictions/outcome of the models. It works by computing the Shapley Values for the whole dataset and combining them.
cuML, the Machine Learning library in RAPIDS that supports single and multi-GPU Machine Learning algorithms, provides GPU-accelerated Model Explainability through Kernel Explainer and Permutation Explainer. Kernel SHAP is the most versatile and commonly used black box explainer of SHAP. It uses weighted linear regression to estimate the SHAP values, making it a computationally efficient method to approximate the values.
The cuML implementation of Kernel SHAP provides acceleration to fast GPU models, like those in cuML. They can also be used with CPU-based models, where speedups can still be achieved but they might be limited due to data transfers and the speed of models themselves.
In the next section, we will discuss how to use RAPIDS Kernel SHAP on Azure.
Using interpret-community and RAPIDS for Interpretability
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. While the main interpretability techniques and glass box explainable models are covered in the Interpret package of this offering, Interpret-Community extends the Interpret repository and incorporates further community developed and experimental interpretability techniques and functionalities that are designed to enable interpretability for real-world scenarios.
We can extend this to explain models on Microsoft Azure, which is discussed in more detail later. Interpret-community provides various techniques for interpreting models, including:
- Tree, Deep, Linear, and Kernel Explainers based on SHAP,
- Mimic Explainer based on training global surrogate models (trains a model to approximate the predictions of the black box model), and
- Permutation Feature Importance(PFI) Explainer based on Breiman’s paper on Rander Forest, which works by shuffling data one feature at a time for the entire dataset and estimating how it affects the performance metric; the larger the change, the more important the feature is. It can explain the overall behavior and not the individual predictions.
Integrating GPU accelerated SHAP in interpret-community
To make GPU-accelerated SHAP easily accessible to end-users, we integrated the cuML’s GPU KernelExplainer to the interpret-community package. Users who have access to VMs with GPUs on Azure (NVIDIA Pascal or better) can install RAPIDS (>=0.20) and enable the GPU explainer by setting the use_gpu flag to True.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes, use_gpu=True)
The newly added GPUKernelExplainer also uses cuML K-Means to replicate the behavior of shap.kmeans. KMeans reduces the size of background data to be processed by the explainers. It summarizes the dataset passed with K mean samples weighted by the number of data points. Replacing sklearn K-Means with cuML allows us to leverage the speed-ups of GPU even during preprocessing of the data before SHAP.
Based on our experiments, we found that cuML models, when used with cuML KernelExplainer, produce the most optimal results for speeds noticing up to 270x speed-ups in some cases. We also saw the best speed-ups for models with optimized and fast predict calls, as seen with the optimized sklearn.svm.LinearSVR and cuml.svm.SVR(kernel=’linear’).
Model explanations in Azure
Azure Machine Learning provides a way to get explanations for regular and automated ML training through the azureml-interpret SDK package. It enables the user to achieve model interpretability on real-world datasets at scale during training and inference[2]. We can also use interactive visualizations to further explore overall and individual model predictions and understand our model and dataset further. Azure-interpret uses the techniques in the interpret-community package, which means it now supports RAPIDS SHAP. We’ll walk through an example notebook demonstrating Model Interpretability using cuML’s SHAP on Azure.
- Set up a RAPIDS environment using a Custom Docker Image on GPU VM (Standard_NC6s_v3, in this example).
- We’ve provided a script(train_explain.py), which trains and explains a binary classification problem using the cuML SVM model. In this example, we are using the HIGGS Dataset to predict if a process generates Higgs Bosons or not. It has 21 kinematic properties measured by particle detectors in the accelerator.
- The script then generates model explanations with GPU SHAP KernelExplainer.
- The generated explanations are uploaded to Azure Machine Learning using our ExplanationClient, which is the client that uploads and downloads the explanations. This can run locally on your machine or remotely on Azure Machine Learning Compute.
- Once the generated explanations are uploaded to Azure Machine Learning Run History, you can view the visualization on the explanations dashboard in Azure Machine Learning Studio.
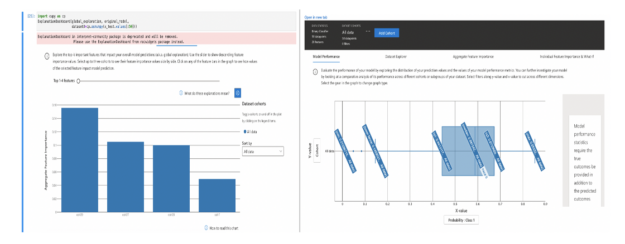
We benchmarked the CPU and GPU implementation on a single explain_global call in Azure. The explain_global function returns the aggregate feature importance values as opposed to instance-level feature importance values while using explain_local. We are comparing cuml.svm.SVR(kernel=’rbf’) vs sklearn.svm.SVR(kernel=’rbf’) on synthetic data with shape (10000, 40).
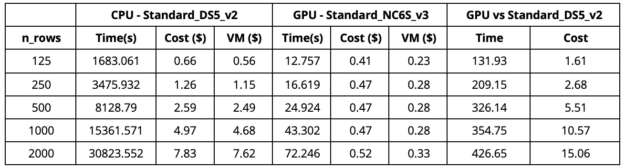
As we can observe from Table 1, when we use the GPU VM (Standard_NC6S_v3), there’s a 420x speed-up on 2000 rows of explanation as opposed to a CPU VM with 16 cores (Standard_DS5_v2). We did notice that using a 64-core CPU VM(Standard_D64S_v3) over a 16-core CPU VM yielded a faster CPU runtime (by the order of around 1.3x). This faster CPU run was still much slower than the GPU run and more expensive. GPU run was 380x faster with a cost of $0.52 in comparison to a $23 for the 64 core CPU VM. We ran the experiments in the US East region in Azure.
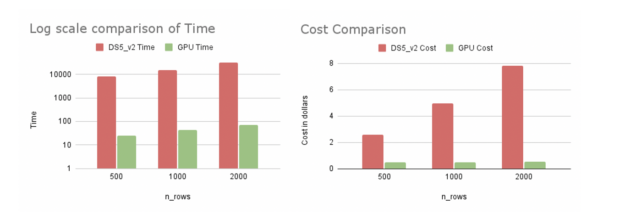
From our experiments, using cuML’s KernelExplainer proves to be more cost and time-efficient on Azure. The speed-ups are better as the number of rows increases. Not only does GPU SHAP explain more data but it also saves more money and time. This can hugely impact businesses that are time-sensitive.
A simple example of how you can use cuML’s SHAP for explanations on Azure. This can be extended to larger examples with more interesting models and datasets. The libraries discussed in this post are constantly updated, if you’re interested in adding or requesting new features check out the following resources:
- https://github.com/rapidsai/cuml
- https://github.com/interpretml/interpret-community
- https://github.com/rapidsai/cloud-ml-examples
- Interpret and explain ML models in Python (preview) – Azure Machine Learning | Microsoft Docs.
- Explaining and Accelerating Machine Learning for Loan Delinquencies
- What is Explainable AI?
