
Evaluating large language models (LLMs) and retrieval-augmented generation (RAG) systems is a complex and nuanced process, reflecting the sophisticated and multifaceted nature of these systems. Unlike traditional machine learning (ML) models, LLMs generate a wide range of diverse and often unpredictable outputs, making standard evaluation metrics insufficient.
Open models such as the Nemotron-4 family provide specialized reward and instruct variants that are designed to act as evaluators and judges for metrics such as helpfulness, coherence, verbosity, making it easier to build robust, reproducible evaluation pipelines.
Key challenges include the absence of definitive ground truth for many tasks, the risk of data contamination, and the models’ sensitivity to prompt variations and decoding strategies. Furthermore, LLMs often produce outputs of such high quality that they can surpass low-quality human references, rendering traditional reference-based metrics inadequate.
In this post, we explore robust evaluation techniques and best practices for assessing the accuracy and reliability of LLMs and RAG systems for various use cases, like chatbots and AI agents.
Why LLM evaluation matters
In the development of generative AI applications, rigorous evaluation is crucial for ensuring system effectiveness and reliability. This process serves multiple critical functions, including validating user satisfaction by confirming that the AI meets expectations and provides meaningful interactions. Evaluation also ensures output coherence, verifying that generated content is logically consistent and contextually appropriate. By benchmarking performance against existing baselines, it offers a clear measure of progress and competitive positioning.
Importantly, evaluation helps detect and mitigate risks by identifying biases, toxicity, or other harmful outputs, promoting ethical AI practices. It also guides future improvements by pinpointing strengths and weaknesses, informing targeted refinements and development priorities. Lastly, evaluation assesses real-world applicability, determining the model’s readiness for deployment in practical scenarios.
NVIDIA NeMo Evaluator offers a library to evaluate many of these benchmarks OOTB and for users looking for an enterprise-ready option, a microservice that can score open and proprietary models consistently across domains like reasoning, coding, and instruction following.
Challenges of LLM evaluation
Designing a robust evaluation process for generative AI applications involves navigating a range of complex challenges. These challenges can be broadly categorized into two main categories: ensuring the reliability of evaluation outcomes and integrating the evaluation process into larger AI workflows.
Ensuring reliable evaluation outcomes
Effective evaluation must produce dependable insights about the model’s performance, which is complicated by the following factors:
- Data availability
- Domain-specific gaps: The lack of tailored benchmarks for specific domains limits the relevance and depth of evaluations, creating challenges in assessing real-world applicability.
- Human annotation constraints: Securing sufficient resources for annotators and creating high-quality nonsynthetic datasets can be time-intensive and costly.
- Data quality
- Biased evaluations: Using LLMs to assess other LLMs can introduce biases that skew results, potentially compromising the accuracy of assessments.
- Lack of techniques
- Overfitting to current techniques: Relying heavily on existing evaluation methods risks models being optimized for these techniques rather than achieving genuine performance improvements.
- Agentic workflows
- Multiturn interaction: Unlike single-turn interactions, multiturn conversations require intricate evaluation designs to capture nuances and maintain coherence over extended exchanges.
- Workflow coherence: Evaluating the overall coherence and effectiveness of multi-agent interactions within agentic workflows presents a unique challenge. It is crucial to assess how well agents work together, maintain consistency across subtasks, and produce cohesive outputs.
Integrating evaluation into AI workflows
Embedding evaluation processes within AI development workflows presents additional hurdles, including:
- Continuous evaluation: Models in production require ongoing assessment to ensure performance and reliability over time, necessitating seamless integration of evaluation tools.
- Real-time feedback: Implementing mechanisms for instant feedback during development can be challenging but is crucial for iterative improvement.
- Cross-platform compatibility: Evaluation tools must function across diverse platforms and environments to ensure consistent and scalable assessments.
- Security and privacy standards: Safeguarding sensitive data and maintaining compliance with privacy regulations is essential during the evaluation process.
- Fragmentation and rigid frameworks: Many existing tools and benchmarks focus on specific metrics, leading to a disjoint approach. Furthermore, rigid frameworks often lack the flexibility to accommodate new data, benchmarks, or contextual factors, limiting their adaptability to evolving needs.
Addressing these challenges requires a thoughtful combination of strategies and tools that ensure both reliable insights and seamless integration into AI workflows. In the following sections, we will explore effective solutions for overcoming these obstacles, with a focus on enhancing the LLM evaluation for real-world applications using NVIDIA NeMo Evaluator as an example.
Choosing LLM evaluation metrics
The process of evaluating LLMs involves multiple complementary approaches as seen in Figure 1, each designed to address specific aspects of model performance.
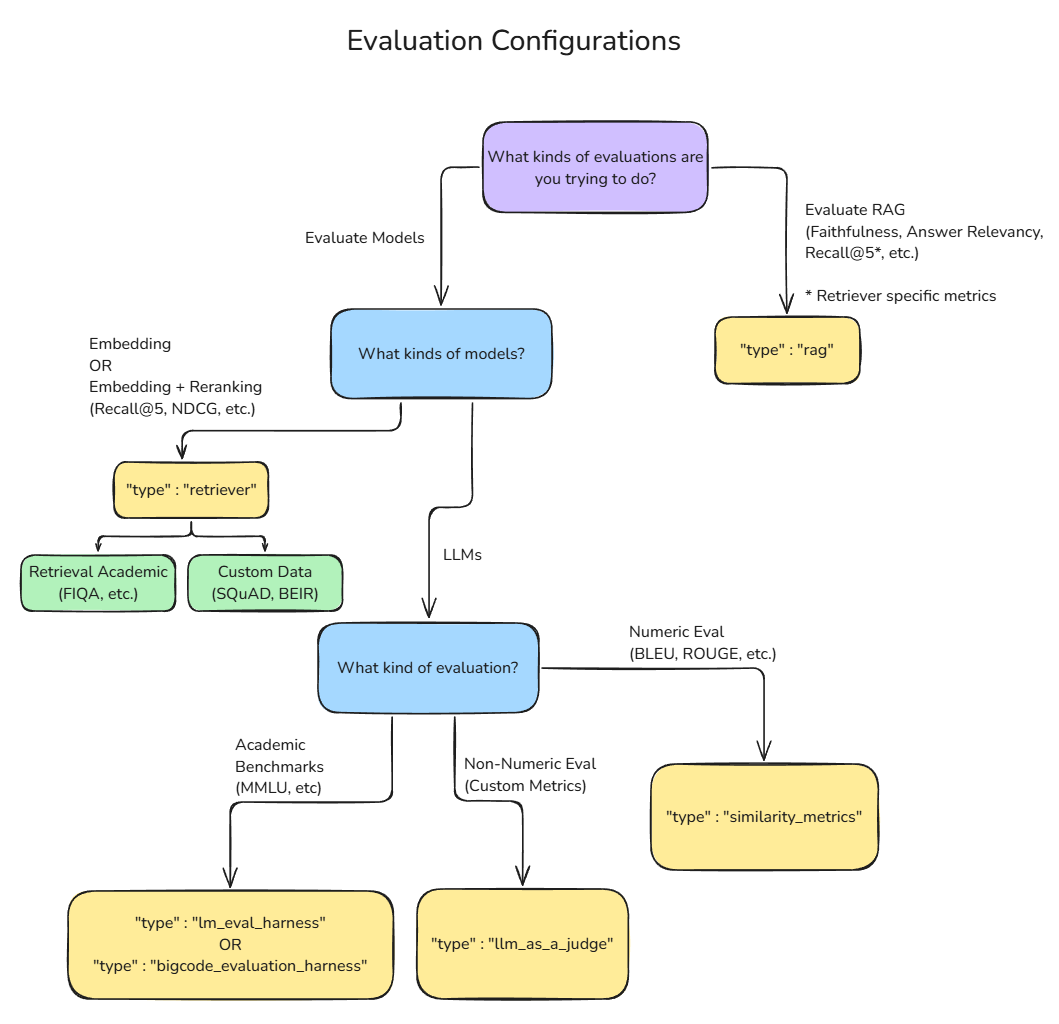
Table 1 summarizes the corresponding benchmarks for each model or system you’re optimizing performance for.
| LLMs | Academic benchmarks Similarity metrics such as F1 and ROUGE LLM-as-a-Judge |
| Embedding models | Precision@K Recall@K Relevance Temporal aspects |
| Embedding and reranking models | |
| RAG systems | Retrieval precision Retrieval recall Faithfulness Response relevancy |
How to evaluate LLM metrics
The following sections outline the different approaches that can be taken while evaluating LLMs and embedding and reranking models.
Academic benchmarks
Standardized benchmarks provide consistent datasets and metrics to evaluate LLMs across a variety of tasks. Some common benchmarks are listed below. Note that as LLMs develop quickly, academic benchmarks can become saturated quickly and new benchmarks will constantly emerge to test the frontier capability of models.
Core knowledge
- Massive Multitask Language Understanding (MMLU): This benchmark covers 57 subjects across STEM, humanities, and social sciences, testing an LLM’s breadth and depth of knowledge.
- HellaSwag: Focused on common-sense reasoning, HellaSwag challenges LLMs with multiple-choice questions about everyday scenarios.
- WinoGrande: An expansion of the Winograd Schema Challenge, WinoGrande evaluates an LLM’s commonsense reasoning capabilities with a dataset of 44,000 problems.
Coding
- HumanEval: This benchmark assesses an LLM’s ability to generate functional code by solving programming problems with specific input-output requirements.
- CodeXGLUE: A comprehensive benchmark for code intelligence, covering various programming tasks and languages.
Q&A
- ARC Challenge (AI2 Reasoning Challenge): Consisting of grade-school science questions, ARC Challenge tests an LLM’s ability to reason and apply scientific knowledge.
- TruthfulQA: Assesses an LLM’s ability to provide truthful answers across 38 topics, targeting common misconceptions
- TriviaQA: Evaluates an LLM’s ability to answer trivia questions across various domains.
Synthetic data generation
- RewardBench: Assesses the capabilities and safety of reward models used in language modeling, particularly those trained with Direct Preference Optimization (DPO).
- CQ-Syn (Compound Question Synthesis): Generates compound questions to evaluate LLMs’ ability to handle complex, multipart queries.
Instruction following
- IFEVAL: A key dataset in measuring model’s instruction following ability with 500 prompts that can be verified by heuristics, such as “write in more than 300 words.”
- MT-Bench-101: Assesses an LLM’s ability to follow complex, multiturn instructions in conversational contexts.
- BIG-Bench Hard: Challenging reasoning tasks designed to test an LLM’s ability to follow intricate instructions.
Multilingual
- MGSM: Evaluates the reasoning abilities of an LLM in multilingual settings, particularly in complex reasoning tasks.
- XNLI (Cross-lingual Natural Language Inference): Evaluates an LLM’s ability to perform natural language inference across multiple languages.
Long context
- LongGenBench: Assesses an LLM’s ability to generate long-form text while adhering to complex instructions over extended sequences.
- ZeroSCROLLS: Zero-shot benchmark for natural language understanding over long texts.
Domain-specific
- FinanceBench: Evaluates LLM performance on financial questions, covering areas like SEC filings, earnings reports, and financial analysis.
- GSM8K (Grade School Math 8K): Focuses on grade-school level math word problems, testing an LLM’s mathematical reasoning skills.
- Massive Multidiscipline Multimodal Understanding and Reasoning (MMMU): Covers college-level knowledge across six core disciplines, challenging LLMs to perform expert-level tasks.
Nemotron-4 reward and instruct models have been validated on RewardBench and other frontier benchmarks, and NeMo Evaluator leverages the same metrics to assess downstream applications.
By using these diverse benchmarks, researchers and developers can gain a comprehensive understanding of an LLM’s capabilities across various domains and task types. This multifaceted approach to evaluation ensures a more robust assessment of model performance and helps identify areas for improvement in LLM development.
LLM-as-a-judge
The LLM-as-a-judge approach leverages the reasoning capabilities of LLMs to assess the outputs of other models. This strategy is particularly useful for tasks requiring nuanced understanding or complex reasoning. Here’s how it works:
- Provide the evaluator LLM with a prompt that includes:
- The task description
- Evaluation criteria
- The input given to the evaluated model
- The output generated by the evaluated model
- Ask the evaluator LLM to assess the output based on the provided criteria
- Receive a structured assessment from the LLM evaluator, which typically includes:
- A numerical score
- Qualitative feedback
- Reasoning for the evaluation
This method excels for tasks where automated metrics fall short, such as assessing coherence and creativity. However, it’s important to note that LLM-as-a-judge evaluations may introduce biases inherent in the LLM evaluator training data.
Numeric evaluations (similarity metrics)
Traditional natural language processing (NLP) similarity metrics offer quantitative methods to evaluate LLM outputs. Common metrics include:
- Bilingual Evaluation Understudy (BLEU): Evaluates machine translation quality by comparing model outputs to reference translations. The BLEU score ranges from 0 (no match, that is, low quality) to 1 (a perfect match, that is, high quality).
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE) : Measures overlap between machine-generated and human-generated summaries. The ROUGE score ranges between 0 and 1, with higher scores indicating higher similarity.
- Perplexity: Quantifies uncertainty in predicting sequences of words, with lower values indicating better predictive performance.
How to evaluate embedding or embedding plus reranking models
Embedding and reranking models are often leveraged in retrieval-based tasks. Being able to evaluate these models is critical in building robust LLM-based applications.
There are a number of standard evaluation metrics that are leveraged in the evaluation of these models:
- Precision@K: Measures the proportion of retrieved documents that are relevant in a grouping of K retrieved documents.
- Recall@K: Assesses the proportion of relevant documents that are successfully retrieved in a grouping of K retrieved documents.
- Relevance: Evaluates how well the retrieved information aligns with the query or context.
- Temporal aspects: Considers the timeliness and currency of the retrieved information.
NeMo Evaluator microservice includes dedicated retriever and reranker evaluation jobs that compute these metrics for RAG blueprints built on NeMo Retriever and Nemotron models.
Reranking serves to augment the retrieval process, and can be thought of as a double check. The metrics leveraged by the embedding or embedding plus reranking pipelines are the same, however.
How to evaluate performance of RAG pipelines
Evaluating RAG systems presents unique challenges that set it apart from general LLM evaluation. This complexity stems from the dual nature of RAG systems, which combine information retrieval with text generation.
When it comes to evaluating RAG systems, conventional metrics prove inadequate as they primarily focus on text similarity and fail to capture the nuanced performance of RAG systems. The reason for this shortcoming lies in their inability to effectively measure factual accuracy and contextual relevance.
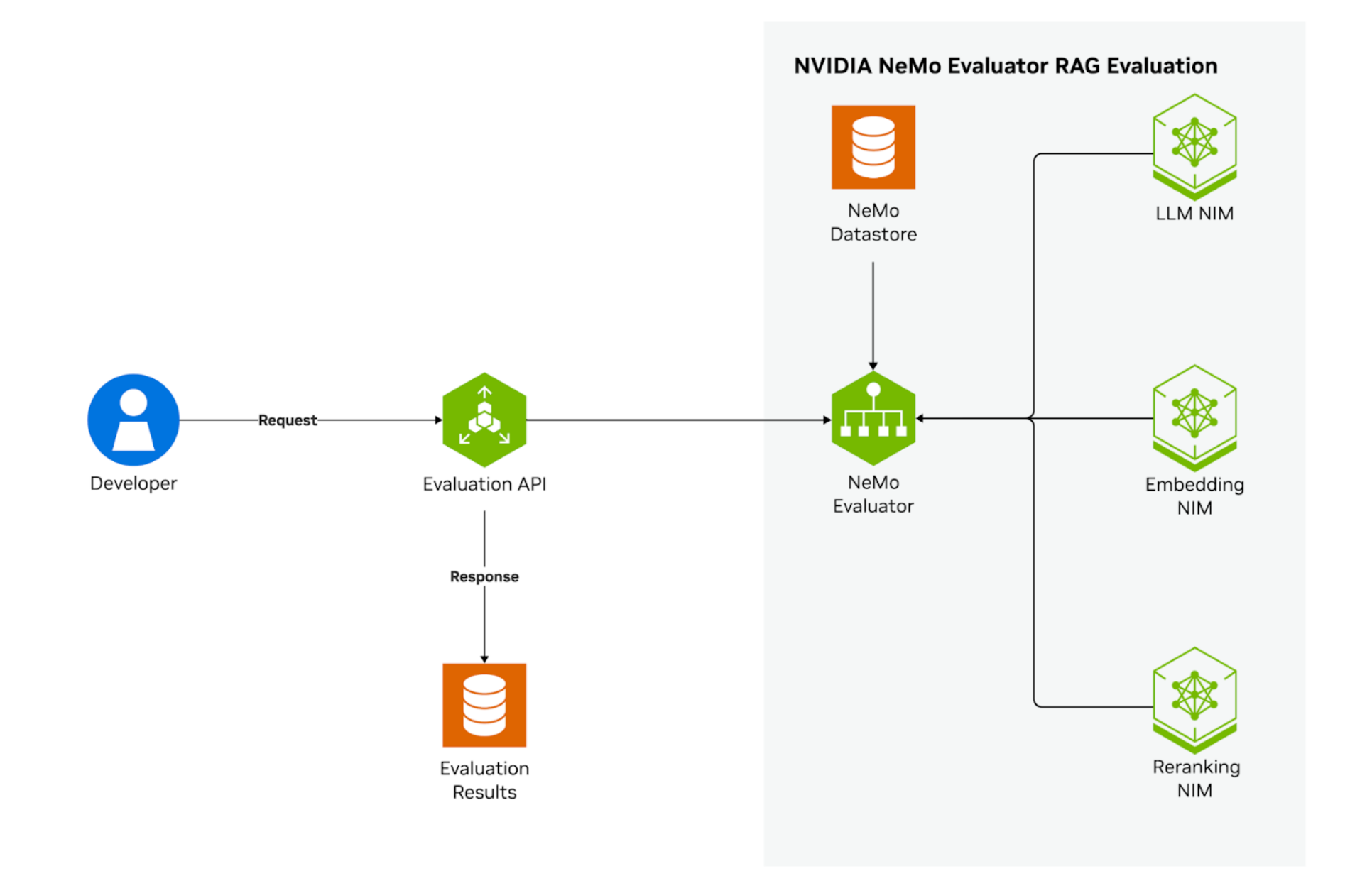
As shown in Figure 2, evaluating RAG systems requires a comprehensive approach that considers both the retrieval and generation components, both independently and as an integrated whole. The retriever component is evaluated as previously described. This is a benefit of using NeMo Evaluator, which enables users to build modular evaluation pipelines.
The generation component must be assessed for its ability to produce coherent, contextually appropriate, and factually accurate text based on the retrieved information. This evaluation should consider the following:
- Coherence: How well the generated text flows and maintains logical consistency.
- Contextual appropriateness: Whether the generated content is suitable for the given query or context.
- Factual accuracy: The correctness of any facts or information presented in the generated text.
To comprehensively evaluate a RAG system, the following end-to-end flow can be employed:
- Synthetic Data Generation (SDG): Creating a set of synthetically generated triplets (question-answer-context) based on the documents in the vector store can be achieved using a model like NVIDIA Nemotron.
- Query processing: Analyze how well the system interprets and processes the input query.
- Information retrieval: Evaluate the relevance and quality of retrieved information using metrics like precision and recall.
- Content generation: Assess the quality, coherence, and factual accuracy of the generated text.
- Overall output assessment: Evaluate the final output for its relevance to the original query, factual correctness, and usefulness.
- Comparative analysis: Compare the RAG system’s performance against baseline models or human-generated responses.
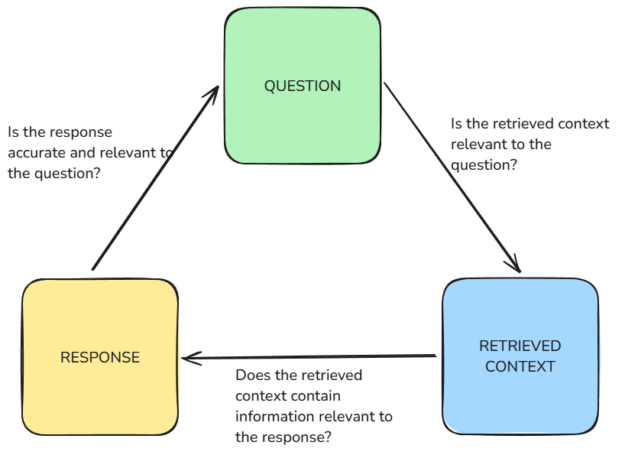
To address the shortcomings of traditional metrics, several specialized metrics have been proposed for RAG evaluation, these are provided through the Ragas framework in NeMo Evaluator:
- Retrieval precision: Measures the proportion of retrieved documents that are relevant to the query.
- Retrieval recall: Assesses the proportion of relevant documents retrieved from the total set of relevant documents.
- Faithfulness: Measures the factual consistency of the generated answer against the given context.
- Response relevancy: Assesses how pertinent the generated answer is to the given prompt.
For a full flow of RAG evaluation on a real-world use case, see Evaluating Medical RAG with NVIDIA AI Endpoints and Ragas.
Next steps for evaluating generative AI and AI agent accuracy
This post provides an overview of the challenges with evaluation, as well as some approaches that have been found to be successful. Evaluation is a complex topic to reason about, and contains many areas for customization and adaptation to your desired downstream tasks. It also comes with some technical and implementation hurdles that can consume critical development time.
NeMo Evaluator microservice simplifies the end-to-end evaluation of generative AI applications, including RAG and agentic AI with an easy-to-use API. It provides LLM-as-a-judge capabilities, along with a comprehensive suite of benchmarks and metrics for a wide range of custom tasks and domains, including reasoning, coding, and instruction-following. You can also incorporate open models like NVIDIA Nemotron that already provide specialized reward and instruct variants that are designed to act as evaluators and judges.
You can seamlessly integrate NeMo Evaluator into your CI/CD pipelines and build data flywheels for continuous evaluation, ensuring AI systems maintain high accuracy over time.
To get started, download the NeMo Evaluator microservice on the NGC catalog today. For developer-focused examples, see the RAG and medical evaluation tutorials that combine NeMo Evaluator, Ragas, and Nemotron models.
