MPI, the Message Passing Interface, is a standard API for communicating data via messages between distributed processes that is commonly used in HPC to build applications that can scale to multi-node computer clusters. As such, MPI is fully compatible with CUDA, which is designed for parallel computing on a single computer or node. There are many reasons for wanting to combine the two parallel programming approaches of MPI and CUDA. A common reason is to enable solving problems with a data size too large to fit into the memory of a single GPU, or that would require an unreasonably long compute time on a single node. Another reason is to accelerate an existing MPI application with GPUs or to enable an existing single-node multi-GPU application to scale across multiple nodes. With CUDA-aware MPI these goals can be achieved easily and efficiently. In this post I will explain how CUDA-aware MPI works, why it is efficient, and how you can use it.
I will be presenting a talk on CUDA-Aware MPI at the GPU Technology Conference next Wednesday at 4:00 pm in room 230C, so come check it out!
A Very Brief Introduction to MPI
Before I explain what CUDA-aware MPI is all about, let’s quickly introduce MPI for readers who are not familiar with it. The processes involved in an MPI program have private address spaces, which allows an MPI program to run on a system with a distributed memory space, such as a cluster. The MPI standard defines a message-passing API which covers point-to-point messages as well as collective operations like reductions. The example below shows the source code of a very simple MPI program in C which sends the message “Hello, there” from process 0 to process 1. Note that in MPI a process is usually called a “rank”, as indicated by the call to MPI_Comm_rank() below.
#include <stdio.h>
#include <string.h>
#include <mpi.h>
int main(int argc, char *argv[])
{
char message[20];
int myrank, tag=99;
MPI_Status status;
/* Initialize the MPI library */
MPI_Init(&argc, &argv);
/* Determine unique id of the calling process of all processes participating
in this MPI program. This id is usually called MPI rank. */
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0) {
strcpy(message, "Hello, there");
/* Send the message "Hello, there" from the process with rank 0 to the
process with rank 1. */
MPI_Send(message, strlen(message)+1, MPI_CHAR, 1, tag, MPI_COMM_WORLD);
} else {
/* Receive a message with a maximum length of 20 characters from process
with rank 0. */
MPI_Recv(message, 20, MPI_CHAR, 0, tag, MPI_COMM_WORLD, &status);
printf("received %s\n", message);
}
/* Finalize the MPI library to free resources acquired by it. */
MPI_Finalize();
return 0;
}
This program can be compiled and linked with the compiler wrappers provided by the MPI implementation.
mpicc source.c -o myapp
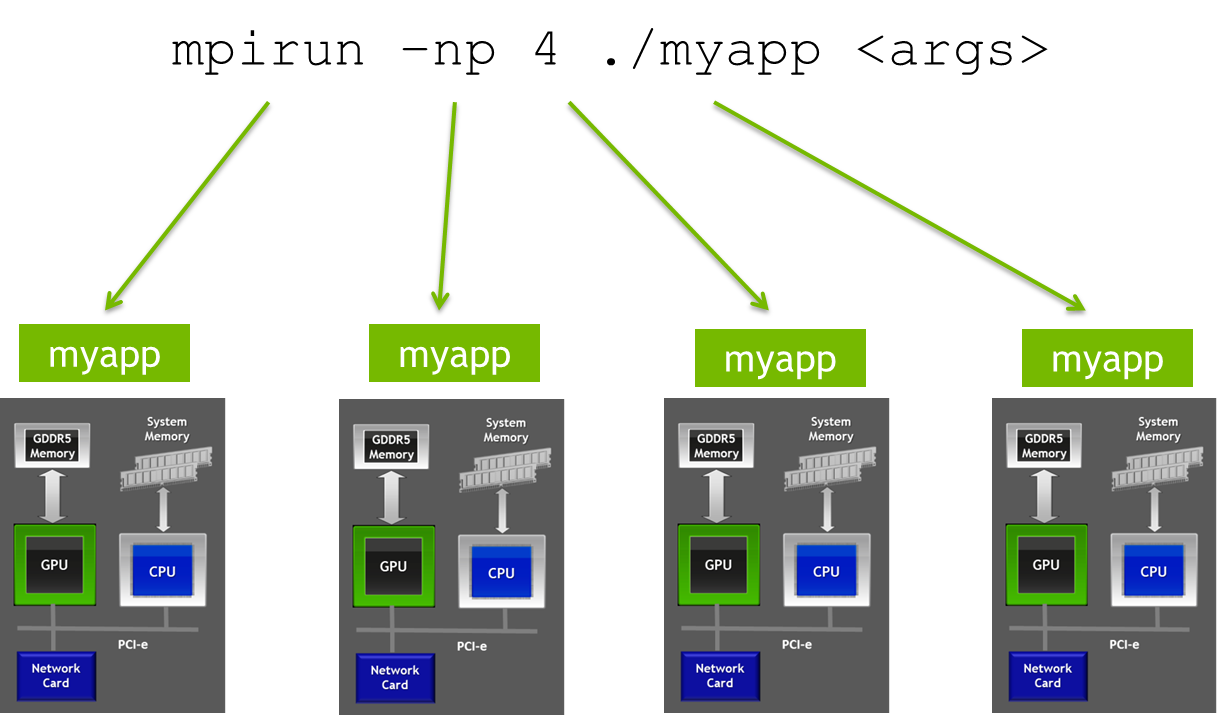
The MPI launcher mpirun is used to start myapp. It takes care of starting multiple instances of myapp and distributes these instances across the nodes in a cluster as shown in the picture below.
What is CUDA-aware MPI?
There are several commercial and open-source CUDA-aware MPI implementations available:
- MVAPICH2 1.8/1.9b
- OpenMPI 1.7 (beta)
- CRAY MPI (MPT 5.6.2)
- IBM Platform MPI (8.3)
- SGI MPI (1.08)
How does CUDA come into play? The example above passes pointers to host (system) memory to the MPI calls. With a regular MPI implementation only pointers to host memory can be passed to MPI. However, if you are combining MPI and CUDA, you often need to send GPU buffers instead of host buffers. Without CUDA-aware MPI, you need to stage GPU buffers through host memory, using cudaMemcpy as shown in the following code excerpt.
//MPI rank 0 cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost); MPI_Send(s_buf_h,size,MPI_CHAR,1,100,MPI_COMM_WORLD); //MPI rank 1 MPI_Recv(r_buf_h,size,MPI_CHAR,0,100,MPI_COMM_WORLD, &status); cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);
With a CUDA-aware MPI library this is not necessary; the GPU buffers can be directly passed to MPI as in the following excerpt.
//MPI rank 0 MPI_Send(s_buf_d,size,MPI_CHAR,1,100,MPI_COMM_WORLD); //MPI rank n-1 MPI_Recv(r_buf_d,size,MPI_CHAR,0,100,MPI_COMM_WORLD, &status);
That, in a nutshell, is what CUDA-aware MPI is all about. In the remainder of this post I will explain how it works, why it is more efficient than staging buffers through host memory, and present performance numbers with a CUDA+MPI Jacobi solver example.
How does CUDA-aware MPI work?
A CUDA-aware MPI implementation must handle buffers differently depending on whether it resides in host or device memory. An MPI implementation could offer different APIs for host and device buffers, or it could add an additional argument indicating where the passed buffer lives. Fortunately, neither of these approaches is necessary because of the Unified Virtual Addressing (UVA) feature introduced in CUDA 4.0 (on Compute Capability 2.0 and later GPUs). With UVA the host memory and the memory of all GPUs in a system (a single node) are combined into one large (virtual) address space.
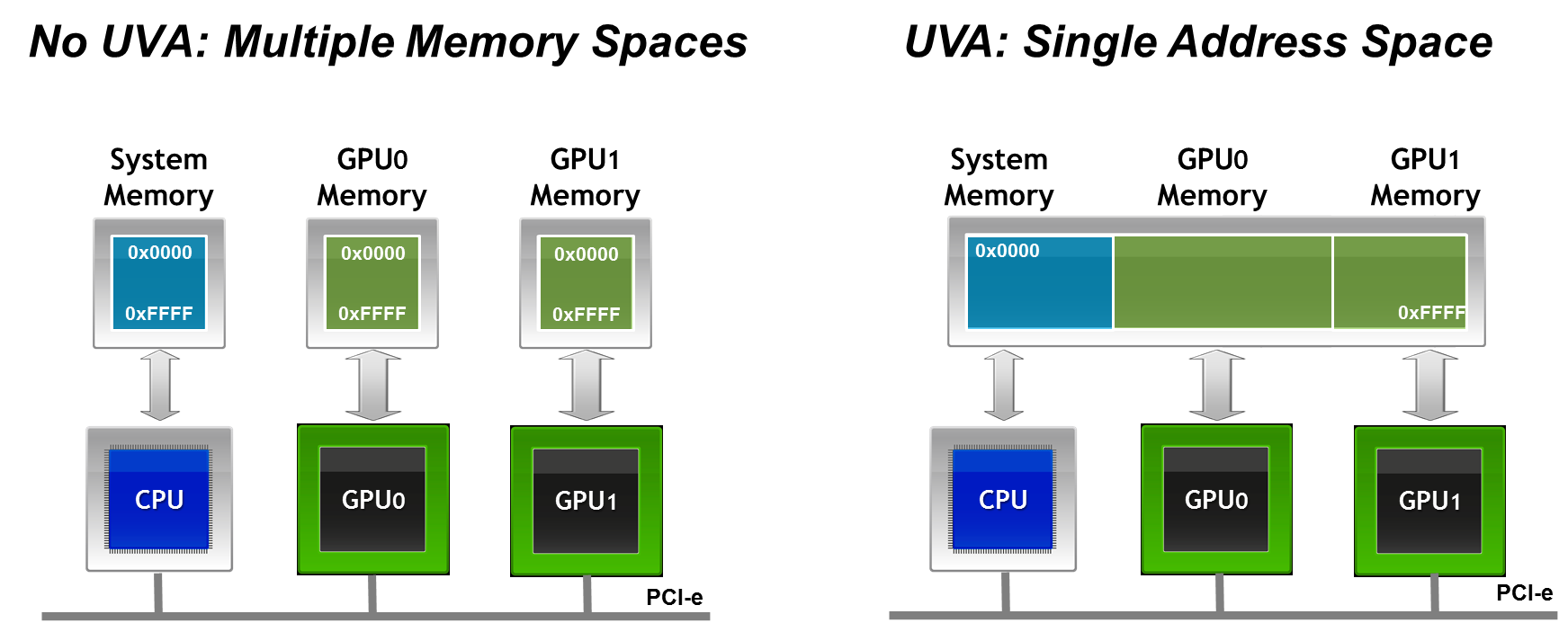
With UVA the location of a buffer can be determined based on the MSBs of its address, so there is no need to change the API of MPI.
What are the benefits of using CUDA-aware MPI besides ease of use?
CUDA-aware MPI not only makes it easier to work with a CUDA+MPI application, it also makes the application run more efficiently for two reasons:
- all operations that are required to carry out the message transfer can be pipelined;
- acceleration technologies like GPUDirect can be utilized by the MPI library transparently to the user.
NVIDIA GPUDirect technologies provide high-bandwidth, low-latency communications with NVIDIA GPUs. GPUDirect is an umbrella name used to refer to several specific technologies. In the context of MPI the GPUDirect technologies cover all kinds of inter-rank communication: intra-node, inter-node, and RDMA inter-node communication.
The newest GPUDirect feature, introduced with CUDA 5.0, is support for Remote Direct Memory Access (RDMA), with which buffers can be directly sent from the GPU memory to a network adapter without staging through host memory.

Another variant is GPUDirect for Peer-to-Peer (P2P) transfers, which was introduced with CUDA 4.0 and can accelerate intra-node communication. Buffers can be directly copied between the memories of two GPUs in the same system with GPUDirect P2P.
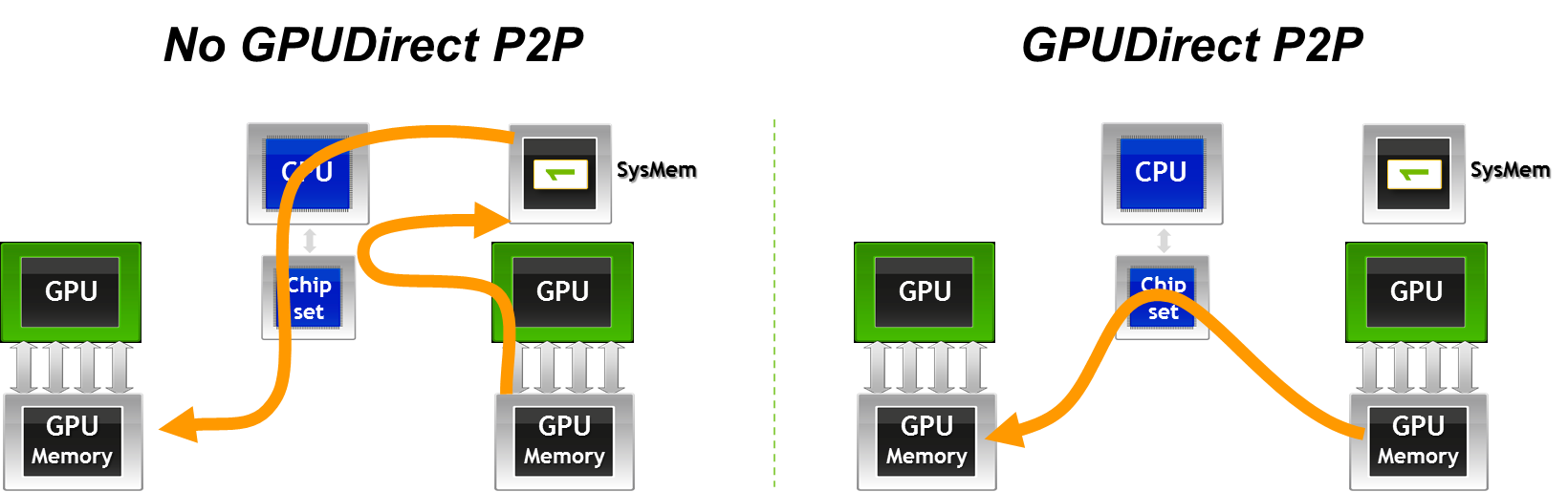
Before I explain the third GPUDirect technology let me give a short refresher about pinned and pageable memory. Host memory allocated with malloc is usually pageable, that is, the memory pages associated with the memory can be moved around by the kernel, for example to the swap partition on the hard drive. Memory paging has an impact on copying data by DMA and RDMA. DMA and RDMA transfers work independently of the CPU and thus also independently of the OS kernel, so memory pages must not be moved by the kernel while they are being copied. Inhibiting the movement of memory pages is called memory “pinning”. So memory that cannot be moved by the kernel and thus can be used in DMA and RDMA transfers is called pinned memory. As a side note, pinned memory can also be used to speed up host-to-device and device-to-host transfer in general. You can find more information on this topic at docs.nvidia.com and in a previous Parallel Forall blog post, “How to Optimize Data Transfers in CUDA C/C++”.
GPUDirect for accelerated communication with network and storage devices was the first GPUDirect technology, introduced with CUDA 3.1. This feature allows the network fabric driver and the CUDA driver to share a common pinned buffer in order to avoids an unnecessary memcpy within host memory between the intermediate pinned buffers of the CUDA driver and the network fabric buffer.

To explain how these acceleration techniques and the necessary intermediate buffers affect communication with MPI I will use a simple example with just two MPI ranks. MPI Rank 0 sends a GPU buffer to MPI Rank 1 and MPI Rank 1 receives the message from MPI Rank 0 into a GPU Buffer. So MPI Rank 0 will execute an MPI_Send.
MPI_Send(s_buf_d,size,MPI_CHAR,1,100,MPI_COMM_WORLD);
MPI Rank 1 will execute an MPI_Recv.
MPI_Recv(r_buf_d,size,MPI_CHAR,0,100,MPI_COMM_WORLD,&stat);
The following diagrams explain how this works in principle. Depending on the MPI implementation, the message size, the chosen protocol and other factors, the details might differ but the conclusions remain valid. In the diagrams I use the icons in the following legend. Faded icons represent operations that are avoided by using RDMA.

If GPUDirect RDMA is available the buffer can be directly moved to the network without touching the host memory at all. So the data is directly moved from the buffer in the device memory of MPI Rank 0 to the device memory of MPI Rank 1 with a PCI-E DMA → RDMA → PCI-E DMA sequence as indicated in the picture below by the red arrow with a green outlineline.
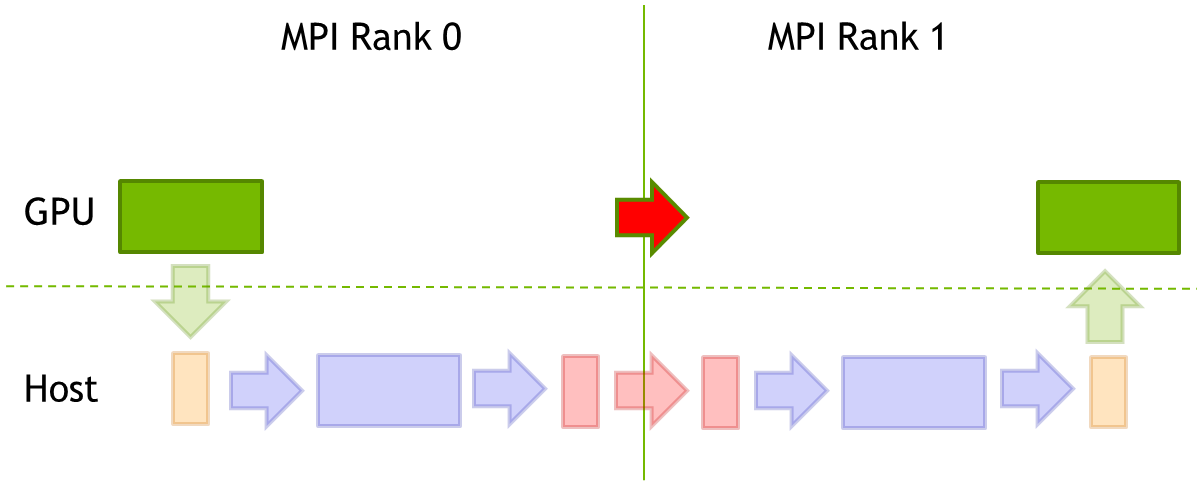
Depending on the size of the buffer this might be done in chunks and so that we get multiple incarnations of the PCI-E DMA → RDMA → PCI-E DMA sequence.

If MPI rank 0 and MPI rank 1 are running on the same host and using GPUs on the same PCI-E bus GPUDirect P2P can be utilized to achieve a similar result.
If no variant of GPUDirect is available, for example if the network adapter does not support GPUDirect, the situation is a little bit more complicated. The buffer needs to be first moved to the pinned CUDA driver buffer and from there to the pinned buffer of the network fabric in the host memory of MPI Rank 0. After that it can be sent over the network. On the receiving MPI Rank 1 these steps need to be carried out in reverse.
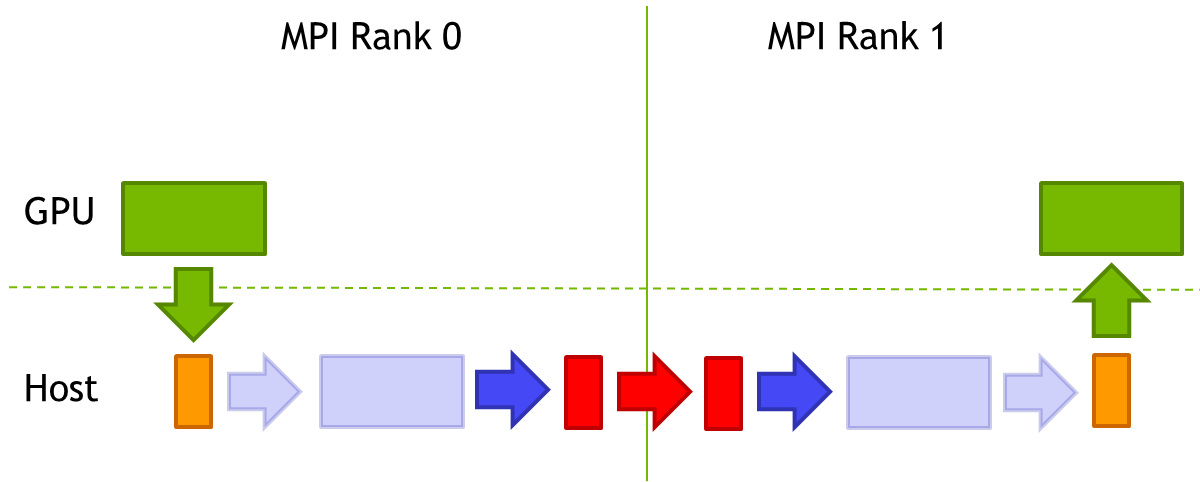
Although this involves multiple memory transfers, the execution time for many of them can be hidden by executing the PCI-E DMA transfers, the host memory copies and the network transfers in a pipelined fashion as shown below.
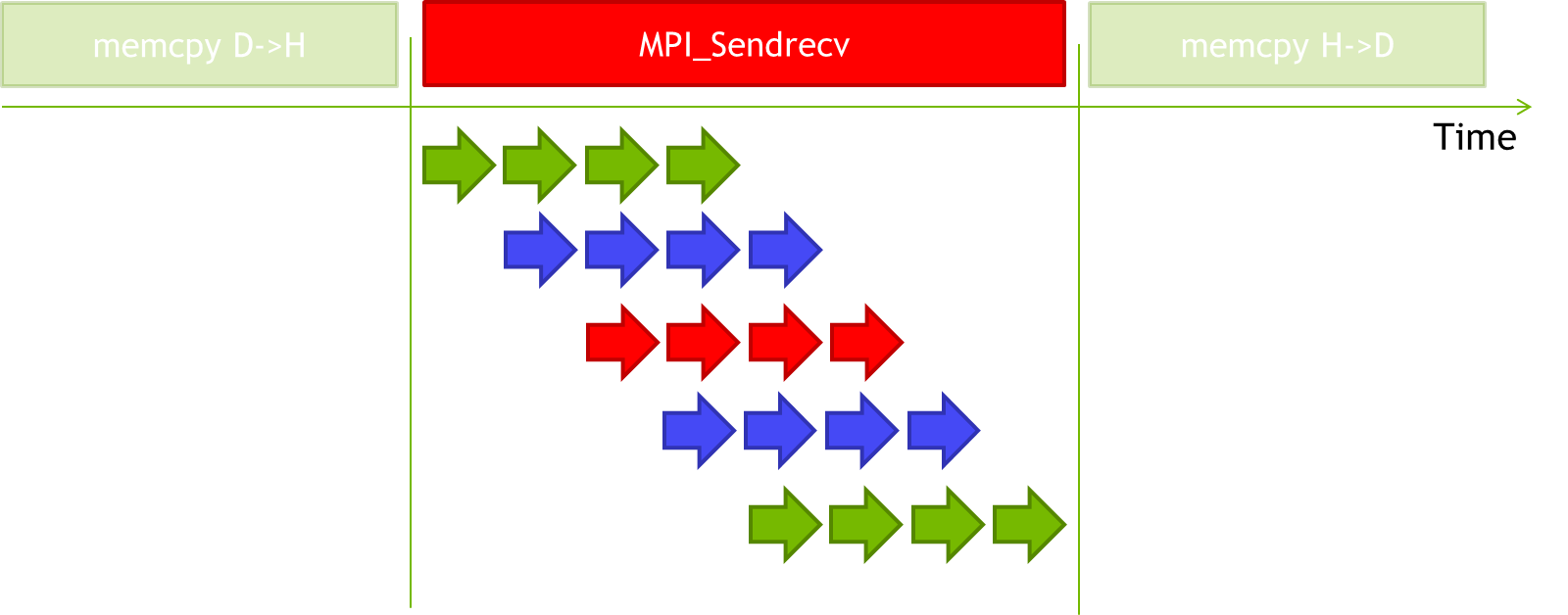
If GPUDirect accelerated communication with network and storage devices is available the memory copy between the pinned CUDA buffer and the network fabric buffer can be eliminated.
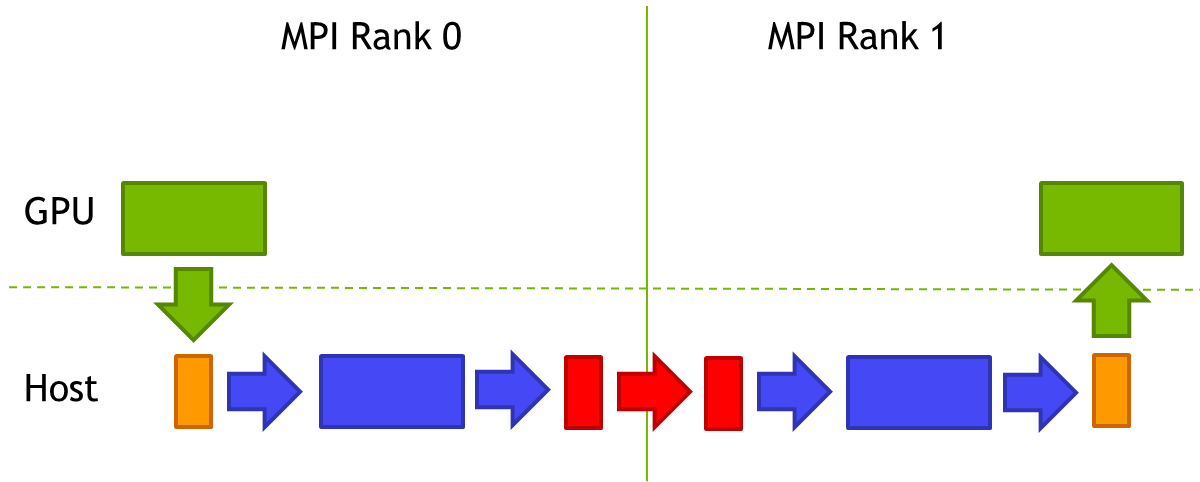
In contrast, if a non-CUDA-aware MPI implementation is used, the programmer has to take care of staging the data through host memory, by executing the following sequence of calls.
MPI Rank 0 will execute a cudaMemcpy from device to host followed by MPI_Send.
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost); MPI_Send(s_buf_h,size,MPI_CHAR,1,100,MPI_COMM_WORLD);
MPI Rank 1 will execute MPI_Recv followed by a cudaMemcpy from device to host.
MPI_Recv(r_buf_h,size,MPI_CHAR,0,100,MPI_COMM_WORLD,&stat); cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);
This will not only introduce an additional memory copy within each node’s host memory, but it will also stall the pipeline after the first cudaMemcpy and after the MPI_Recv on MPI rank 1, so the execution time will be much longer as visualized in the diagram below.
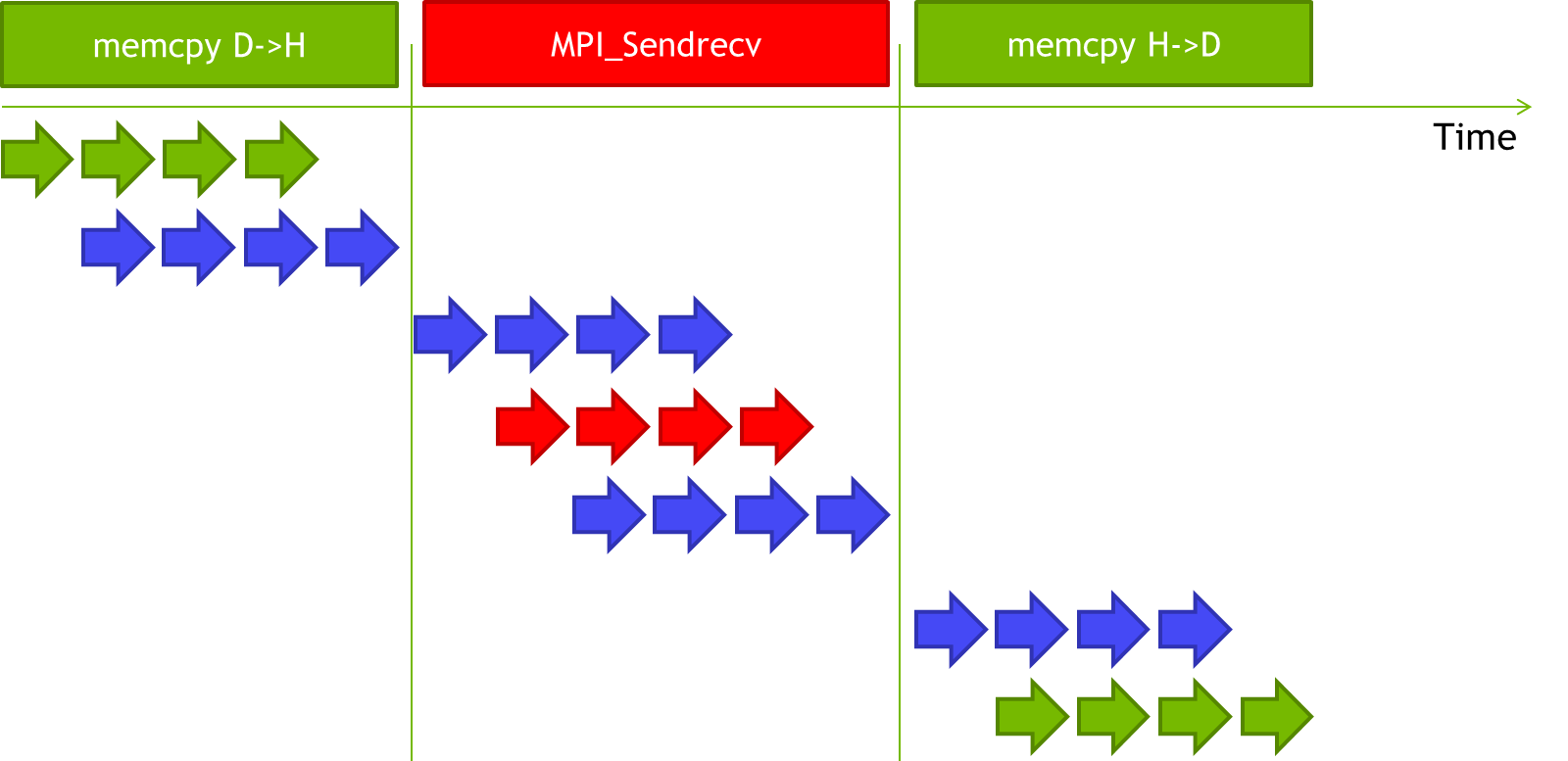
A user of a non-CUDA-aware MPI library could implement a more efficient pipeline using CUDA streams and asynchronous memory copies to speed up the communication. Even so, a CUDA-aware MPI can more efficiently exploit the underlying protocol and can automatically utilize the GPUDirect acceleration technologies.
Now you know how CUDA-aware MPI works in principle and why it is more efficient than using a non-CUDA-aware MPI. In my next post I will show you the performance you can expect from CUDA-aware MPI, which I will measure with synthetic MPI bandwidth and latency benchmarks and, as a real world example, with a Jacobi solver for the Poisson equation. Make sure to read it next week!