
HPC applications are critical to solving the biggest computational challenges to further scientific research. There is a constant need to drive efficiencies in hardware and software stacks to run larger scientific models and speed up simulations.
High communication costs between GPUs prevents you from maximizing performance from your existing hardware. To address this, we’ve built NVIDIA Topology-Aware GPU Selection (NVTAGS), a toolset for HPC applications. It enables faster simulation time for HPC applications with a non-uniform communication pattern, by intelligently assigning MPI processes to GPUs and thereby reducing overall GPU-to-GPU communication time.
In this post, we discuss how MPI-process-to-GPU assignment can affect application communication performance, demonstrate how NVTAGS works, and show performance gains that can be achieved with NVTAGS.
Core issue
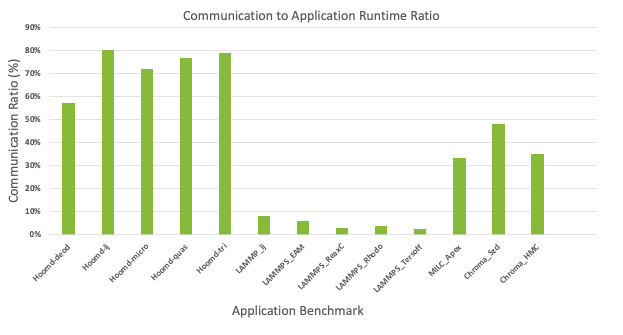
Many GPU-accelerated HPC applications spend a substantial portion of their time in non-uniform, GPU-to-GPU communications. Applications such as HOOMD-blue, CHROMA, and MIMD Lattice Computation (MILC) spend considerable time in GPU-to-GPU communication, clearly outlining the need to reduce communication congestion. Figure 1 shows the ratio of GPU communication time to total application runtime for HPC applications running on OpenMPI.
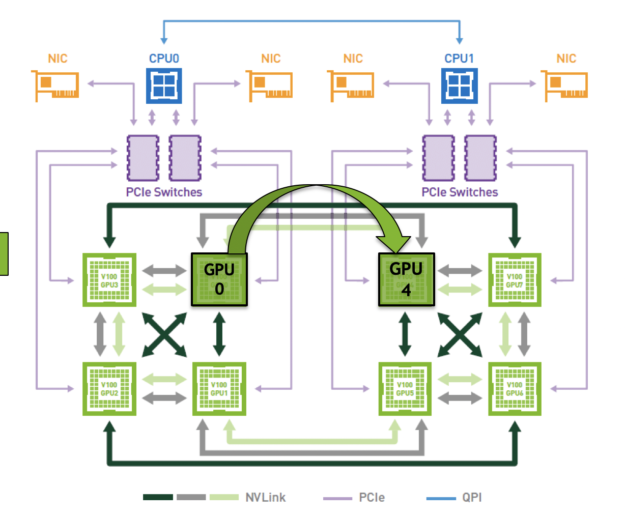
In a multi-GPU system topology, each GPU pair may use a communication channel different from other GPU pairs in terms of communication bandwidth or latency. This means that some GPU pairs communicate more data faster than others.
To ensure that GPU-to-GPU communication is as efficient as possible for HPC applications with non-uniform communication, it is crucial that these applications make informed decisions when assigning MPI processes to GPUs, ensuring processes requiring heavy communication use faster communication links. The assignment of processes to GPUs is dependent on two key factors: system topology and application profiling.
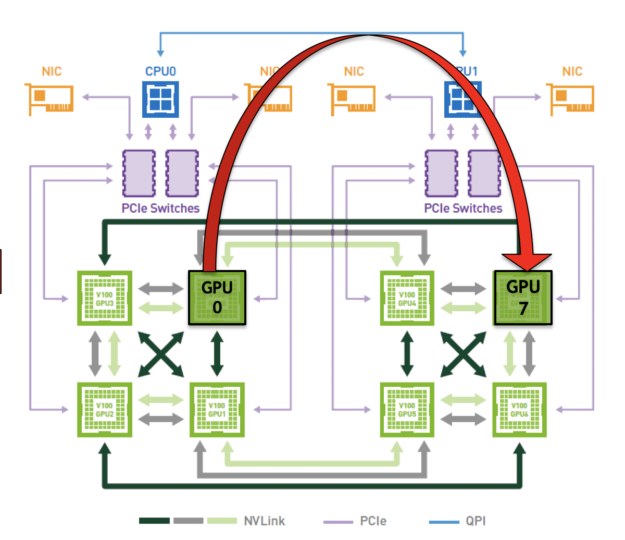
In Figure 2, GPU 0 and GPU 4 share a higher bandwidth communication channel compared to GPU 0 and GPU 7 which are linked by lower bandwidth communication channels. It would be ideal to route the processes that require heavy communication through the faster channels, but this requires an intimate knowledge of the overall system topology. Doing this manually isn’t a viable option.
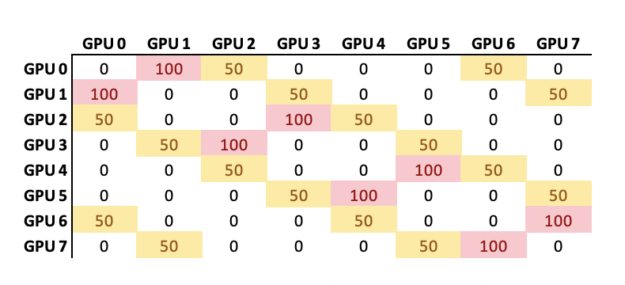
You also need to know how processes are distributed per GPU for a given HPC application. Figure 3 shows the GPU-to-GPU communication pattern for MILC. The values shown have been normalized from 0 to 100, where 100 denotes a higher volume of communication and 0 denotes a lower volume of communication. By default, process 0 is assigned to GPU 1 and process 2 is assigned to GPU 2 and so on. The process-to-GPU mapping varies from one HPC application to another.
Currently, these mappings must be generated through an iterative and manual process that is not only time-consuming, but also requires considerable domain expertise.
NVTAGS automates both these processes.
Speeding up application simulation with NVTAGS
NVTAGS is a toolset for HPC applications using MPI. It enables faster solve times for those applications with high GPU-communication-to-application runtime ratios. NVTAGS intelligently and automatically assigns GPUs to MPI processes, thereby reducing overall GPU-to-GPU communication time. It profiles application communication, extracts system GPU communication topology leveraging NVIDIA System Management Interface (nvdia-smi), and finds an efficient process-to-GPU assignment that minimizes communication congestion.
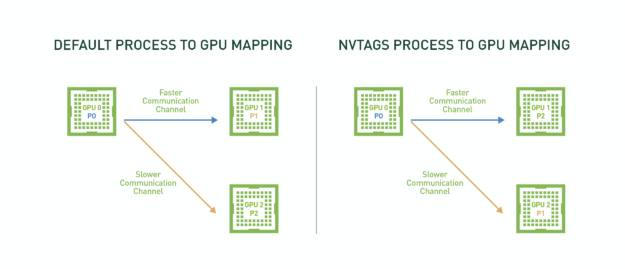
In Figure 4, process 0 (P0) and process 1 (P1) require relatively “lighter” GPU-to-GPU communication while process 0 (P0) and process 2 (P2) require relatively “heavier” GPU-to-GPU communication. NVTAGS profiles the application and the system communication topology to assign P0 and P2 to GPUs with the fastest communication path, ensuring that the processing pairs that engage in the heaviest communication use the fastest available communication channel.
In addition to finding an efficient GPU assignment for your HPC application, NVTAGS provides the option for supporting automatic CPU and NIC binding. With this option (enabled by default), NVTAGS assigns GPUs processes intelligently, ensuring that each process binds to CPUs and NICs that are in its affinity.
Here are three key benefits of NVTAGS:
- Automated process: NVTAGS provides a fully automated process that removes the need to conduct manual and time-consuming mapping of GPUs to processes. NVTAGS is application– and system-agnostic and can provide critical insight into how the processes are distributed on any single-node system.
- Improved performance: NVTAGS dramatically improves performance by intelligently mapping GPUs to MPI processes for HPC applications that require heavy GPU-to-GPU communication. This decreases application time to solution, allowing you to run more simulations.
- Easy integration: NVTAGS can be easily integrated into a container, making it portable and easily deployable on any system or architecture. This ensures that end users can run NVTAGS in their own environment without having to configure systems or require any additional assistance from system administrators. It is extremely lightweight, with application profiling taking up less than 1% of the total application runtime.
Key steps for using NVTAGS
The NVTAGS pipeline consists of two integral steps:
- Tuning includes system profiling, application profiling, and mapping.
- Running applies GPU mapping and performs CPU and NIC binding.
Tuning
For system profiling, NVTAGS analyzes the GPU communication channels on the system. It first records link names interconnecting each pair of GPUs and then assigns values to each link to represent their communication strength. For example, GPU pairs with NVLink are assigned greater values compared to pairs connected using QPI.
For application profiling, NVTAGS records all GPU communication that takes place among processes and deciphers the communication pattern used by the application. It first detects the MPI version used to run the application and then loads an application profiler on the system to build the profiling results. Profiling results are cached for subsequent use.
For mapping, NVTAGS looks for an efficient solution for placing application processes on system GPUs. It first converts system and application profiles from the previous steps into graphs. It then uses mapping algorithms to find an efficient way of mapping application communication graphs into the system graph.
Running
In this step, NVTAGS reads a mapping file that is generated in the tuning step and sets CUDA_VISIBLE_DEVICES before initiating the application run command.
During the mapping process, NVTAGS also considers CPU and NIC affinity to the corresponding GPUs. For example, if P0 uses GPU 0 by default, which has affinity to CPU CORE 0 and NIC 0, and P1 uses GPU1, which has affinity to CPU CORE1 and NIC1. After running NVTAGS, P0 is assigned to GPU1 and binds to CPU CORE 1 and NIC 1, ensuring that the new GPU assignment uses resources that are in its affinity.
Example run commands
It is straightforward to update existing application run commands to use NVTAGS. Consider the following example command for an application titled ‘myapp’:
mpirun ... myapp myargs
First, tune myapp with NVTAGS profiling. Run the following command:
nvtags --tune “mpirun ... myapp myargs”
You can then run your application with the following command and benefit from optimized GPU assignment:
nvtags --run “mpirun … myapp myargs”
Alternatively, you can use the NVTAGS script, which takes care of both optimized GPU assignment and binding CPU and NICs:
mpirun ... -x EXE="myapp" -x ARGS="myargs" nvtags_run.sh
Performance results
In this section, we explore the NVTAGS performance impact on CHROMA and MILC HPC applications. These applications can be accessed from NVIDIA NGC, the hub for GPU-optimized containers for HPC, deep learning, and visualization applications. The highly performant containers from NGC allow you to deploy applications easily without having to deal with the complicated process of binding libraries and dependencies required to run the application.
The following table shows how NVTAGS reassigns processes to GPUs for CHROMA after the tuning step.
| Process ID | Before NVTAGS | After NVTAGS |
|---|---|---|
| P0 | GPU 0 | GPU 0 |
| P1 | GPU 1 | GPU 1 |
| P2 | GPU 2 | GPU 4 |
| P3 | GPU 3 | GPU 5 |
| P4 | GPU 4 | GPU 6 |
| P5 | GPU 5 | GPU 7 |
| P6 | GPU 6 | GPU 2 |
| P7 | GPU 7 | GPU 3 |
Correspondingly, NVTAGS also records the normalized GPU communication congestion, which is the total volume of data transferred through a given link divided by the maximum link bandwidth. Figure 5 shows the comparison for CHROMA before and after applying NVTAGS.
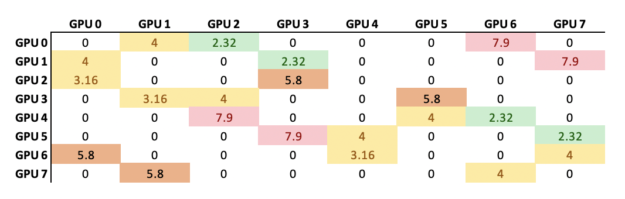

Figure 5a. Before NVTAGS. 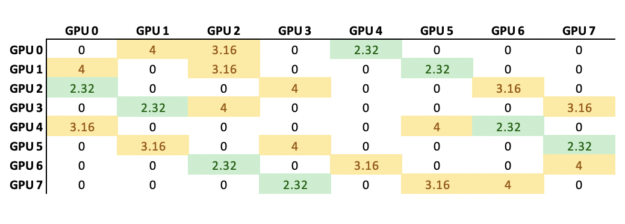

Figure 5b. After NVTAGS.
NVTAGS considers both maximum and average communication congestion when determining the appropriate mapping required to minimize application communication time. For CHROMA, NVTAGS reduced the maximum congestion from 7.9 to 4.0 (1.9X) and dropped the average congestion from 4.53 to 3.16 (1.4X).
Finally, look at performance data for CHROMA and MILC. Figure 6 shows performance gains from properly pinning CPUs (gray) and running with NVTAGS (green). We ran the applications on an eight GPU, V100 DGX-1 system.
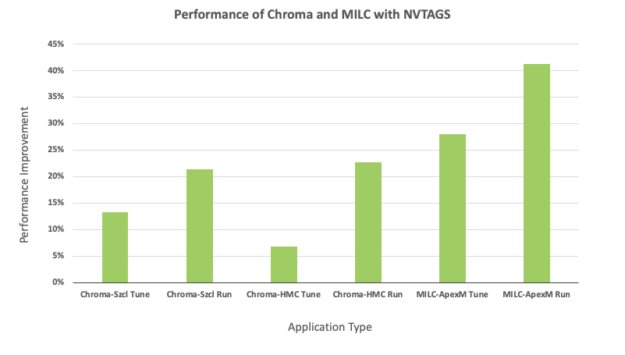
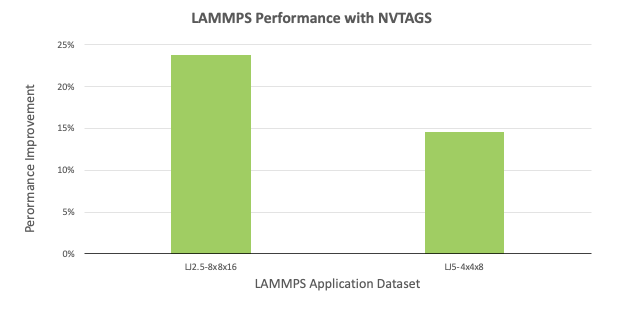
For CHROMA, we attained performance improvements ranging from 7-24% for a given type of dataset. For MILC, the performance gains range between 28-41% between two different datasets. Furthermore, we also extended the study by evaluating Large-scale Atomic Molecular Massively Parallel Simulator (LAMMPS) on an eight V100 GPU PCIe with Broadwell CPUs system using different data sets. For the LJ and ReaxC benchmarks, we noticed performance improvements of 5.6% and 6.8%, respectively.
Summary
NVTAGS automated GPU-to-process mapping provides substantial gains in performance for HPC applications that have a high communication-to-application runtime ratio.
In future versions of NVTAGS, we plan to extend its functionality to multi-node systems as well as other areas where it may provide additional benefits. In doing so, we believe we can provide additional speedups when running applications on clusters.
Download NVTAGS binaries now and send us feedback on how NVTAGS can be further improved.
