Jun 23, 2021
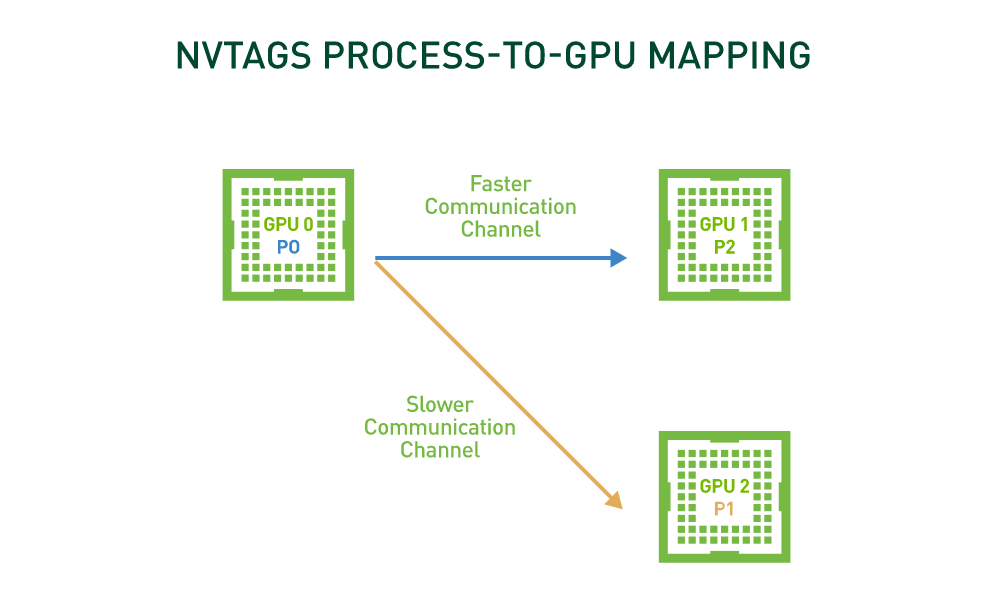
Achieve up to 75% Performance Improvement for Communication Intensive HPC Applications with NVTAGS
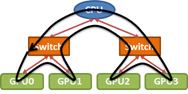
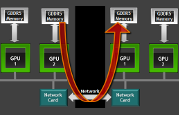
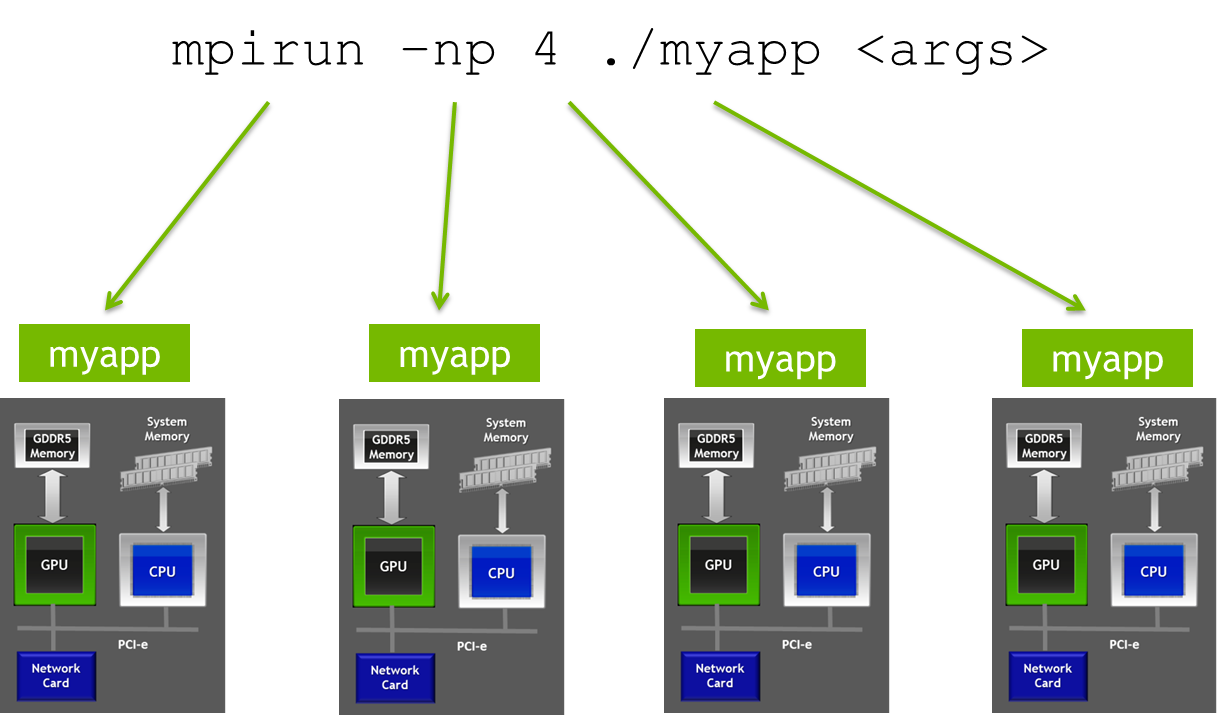
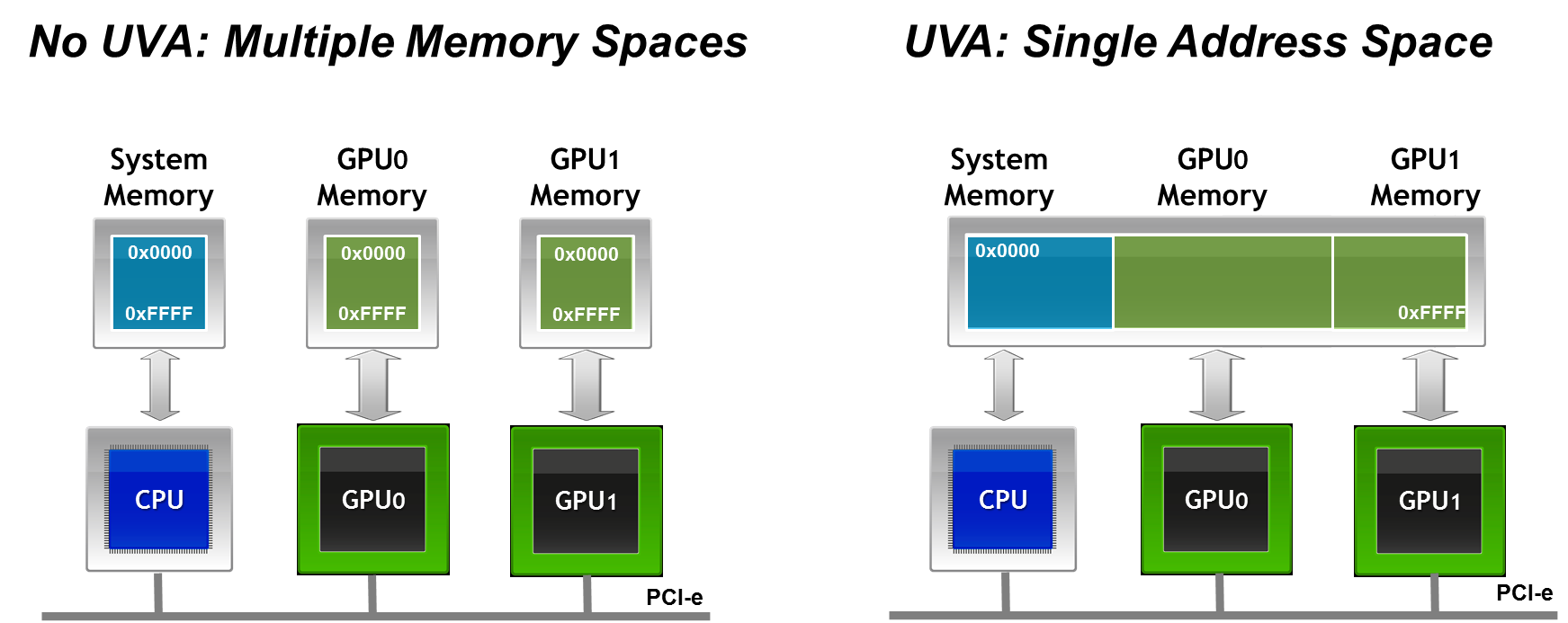
Many GPU-accelerated HPC applications spend a substantial portion of their time in non-uniform, GPU-to-GPU communications. Additionally, in many HPC systems,...
2 MIN READ