Today many servers contain 8 or more GPUs. In principle then, scaling an application from one to many GPUs should provide a tremendous performance boost. But in practice, this benefit can be difficult to obtain. There are two common culprits behind poor multi-GPU scaling. The first is that enough parallelism has not been exposed to efficiently saturate the processors. The second reason for poor scaling is that processors exchange too much data and spend more time communicating than computing. To avoid such communication bottlenecks, it is important to make the most of the available inter-GPU bandwidth, and this is what NCCL is all about.
NCCL (pronounced “Nickel”) is a library of multi-GPU collective communication primitives that are topology-aware and can be easily integrated into your application. Initially developed as an open-source research project, NCCL is designed to be light-weight, depending only on the usual C++ and CUDA libraries. NCCL can be deployed in single-process or multi-process applications, handling required inter-process communication transparently. Finally, the API will be very familiar to anyone with experience using MPI’s collectives.
Collective Communication
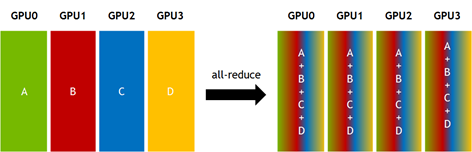
Collective communication routines are common patterns of data transfer among many processors. If you have experience with MPI, then you are probably already familiar with several collective operations. For example, all-reduce starts with independent arrays \(V_k\) of N values on each of K processors and ends with identical arrays S of N values, where \(S[k] = V_0[k]+V_1[k]+\ldots+V_k[k]\), for each processor k. See Figure 1.
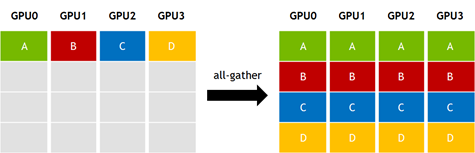
Another common collective is all-gather, where each of K processors begins with an independent array of N values, and collects data from all other processors to form a result of dimension N*K, as Figure 2 shows.
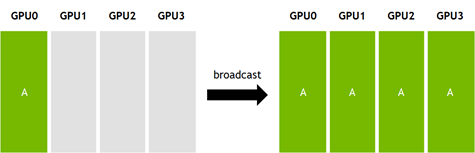
Broadcast is a third example. Here an N-element buffer on one processor is copied to all other processors, as Figure 3 shows.
All of the above collectives can be performed either “out-of-place,” with separate input and output buffers, or “in-place,” with overlapping input and output.
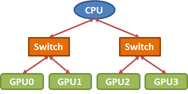
Red arrows represent PCIe x16 connections.
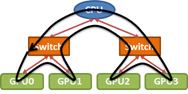
There are numerous approaches to implementing collectives efficiently. However, it is critical that our implementation takes the topology of interconnects between processors into account. For example, consider a broadcast of data from GPU0 to all other GPUs in the PCIe tree topology pictured below.
A two-step tree algorithm is a common choice in this situation. In the first step the data is sent from the GPU0 to a second GPU, and in the second step both of these send data to the remaining processors. However, we have a choice. We can either send data from GPU0 to GPU1 in the first step and then GPU0 to GPU2 and GPU1 to GPU3 in the second, or we can perform the initial copy form GPU0 to GPU2 and then GPU0 to GPU1 and GPU2 to GPU3 in the second step. Examining the topology, it is clear that the second option is preferred, since sending data simultaneously from GPU0 to GPU2 and GPU1 to GPU3 would cause contention on the upper PCIe links, halving the effective bandwidth for this step. In general, achieving good performance for collectives requires careful attention to the interconnect topology.
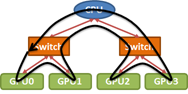
To optimize Broadcast bandwidth, an even better approach is to treat the PCIe topology above as a ring.
The broadcast is then performed by relaying small chunks of the input around the ring from GPU0 to GPU3. Interestingly, ring algorithms provide near optimal bandwidth for nearly all of the standard collective operations, even when applied to “tree-like” PCIe topologies. But note that selecting the correct ring order remains important.
GPU Collectives with NCCL
In order to provide maximum bandwidth, NCCL implements ring-style collectives. NCCL implicitly indexes the GPUs into the optimal ring order under the hood. This provides great performance for your application while freeing you from having to worry about specific hardware configurations.
Many collectives requires a buffer for intermediate results. In order to minimize memory overhead to a few MB on each GPU, NCCL splits large collectives into many small chunks. It would be highly inefficient to launch separate kernels and cudaMemcpy calls for every step and chunk of a collective algorithm. Instead, each collective is implemented by a monolithic CUDA kernel. NCCL makes extensive use of GPUDirect Peer-to-Peer direct access to push data between processors. Where peer-to-peer direct access is not available (e.g., when traversing a QPI interconnect), the pushed data is staged through a buffer in pinned system memory. Similarly, synchronization is performed by polling on volatile variables in device (or pinned system) memory.
Internally, NCCL implements each collective in terms of three primitives: Copy, Reduce, and ReduceAndCopy. Each of these is optimized to efficiently transfer fine-grained slices of data (4-16KB) between GPUs. The kernels have also been specifically optimized to achieve maximum bandwidth at low occupancy. As a result, NCCL can saturate a PCIe 3.0 x16 interconnect using a single block of CUDA threads. This leaves the bulk of the GPU free to execute compute tasks concurrently with the communication.
NCCL currently supports the all-gather, all-reduce, broadcast, reduce, and reduce-scatter collectives. Any number of GPUs can be used, as long as they reside in a single node.
Using NCCL
The open-source release of NCCL is available on Github. The library should build on any common Linux distribution and is compatible with CUDA 7.0 and later. CUDA supports direct access only for GPUs of the same model sharing a common PCIe root hub. GPUs not fitting these criteria are still supported by NCCL, though performance will be reduced since transfers are staged through pinned system memory.
The NCCL API closely follows MPI. Before performing collective operations, a communicator object must be created for each GPU. The communicators identify the set of GPUs that will communicate and maps the communication paths between them. We call the set of associated communicators a clique. There are two ways to initialize communicators in NCCL. The most general method is to call ncclCommInitRank() once for each GPU.
ncclResult_t ncclCommInitRank(ncclComm_t* comm,
int nGPUs,
ncclUniqueId cliqueId,
int rank);
This function assumes that the GPU belonging to the specified rank has already been selected using cudaSetDevice(). nGPUs is the number of GPUs in the clique. cliqueId allows the ranks of the clique to find each other. The same cliqueId must be used by all ranks. To achieve this, call ncclGetUniqueId() in one rank and broadcast the resulting uniqueId to the other ranks of the clique using the communication framework of your choice (for example, MPI_Bcast).
The last argument to ncclCommInitRank() specifies the index of the current GPU within the clique. It must be unique for each rank in the clique and in the range [0, nGPUs). This index is used, for example, to identify the source GPU for a broadcast operation, or to order the contributions to an all-gather.
Upon successful initialization, ncclCommInitRank() returns ncclSuccess and *comm is set to the new NCCL communicator object.
Internally, ncclInitRank() performs a synchronization between all communicators in the clique. As a consequence, it must be called from a different host thread for each GPU, or from separate processes (e.g., MPI ranks). Specifically, calling ncclInitRank() in a single threaded loop over GPUs will result in deadlock.
The second way to initialize the communicators is to use ncclCommInitAll(). This is essentially a convenience routine that spares you the effort of spawning extra host threads to initialize NCCL in an otherwise single-threaded application.
ncclResult_t ncclCommInitAll(ncclComm_t* comms,
int nGPUs,
int* devList);
The comms argument now refers to an array of ncclComm_t objects, one for each of the nGPUs ranks in the clique. devList specifies which CUDA device gets associated with each rank. With the communicator object initialized, you can call the collectives through their host functions, such as ncclAllReduce().
ncclResult_t ncclAllReduce(void* sendoff,
void* recvbuff,
int count,
ncclDataType_t type,
ncclRedOp_t op,
ncclComm_t comm,
cudaStream_t stream);
Documentation for each collective is provided in nccl.h. Most arguments have analogues in the MPI collectives API. The notable exception is the stream argument. Similar to many CUDA “Async” routines, NCCL collectives schedule the operation in a stream but may return before the collective is complete. By queuing collectives and other compute kernels in separate streams, the GPU is able to overlap collective communication with more compute-intensive workloads. To maximize overlap, schedule NCCL collectives on high-priority streams to allow them to slip in among compute intensive grids.
ncclAllReduce() must be called once for each communicator in the clique, each call providing its own send and receive buffers, etc. NCCL collectives assume that the appropriate CUDA context is already current. Because NCCL is asynchronous, a simple loop can be used to initiate a collective from a single threaded application.
for (int gpu=0; gpu<nGPUs; ++gpu) {
cudaSetDevice(devList[gpu]);
ncclAllReduce(...);
}
Performance
The performance that NCCL collectives achieve depends on the exact topology of the computer. In the best case, all GPUs share peer access. This is most common for workstations equipped with a few GPUs. Larger servers usually sport dual CPUs, with some GPUs segregated on different IO hubs. Figure 6 shows NCCL bandwidth for various collectives measured on an NVIDIA Digits DevBox equipped with 4 GeForce GTX Titan X GPUs arranged as in Figure 4 above.
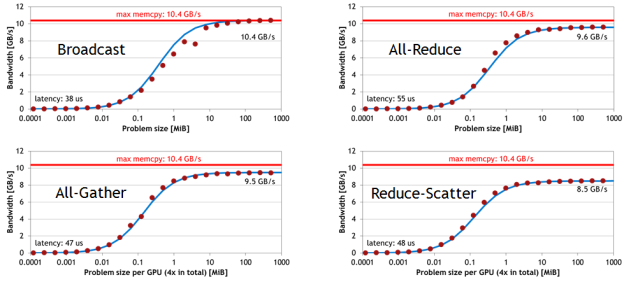
The red bar at 10.4 GB/s represents the bandwidth achieved by a large cudaMemcpy between two of the GPUs (specifically GPU 0 and 2 in Figure 4). NCCL sustains a high percentage of this peak bandwidth while performing communication among all four GPUs.
Future Directions & Final Remarks
The goal of NCCL is to deliver topology-aware collectives that can improve the scalability of your multi-GPU applications. By using NCCL you can get great performance without having to think about low-level hardware details.
Simple code examples for both single-process and MPI applications are distributed with NCCL. As a research project, we welcome your feedback as we continue to evolve the project. Please try it out and let us know what you think! For an update on the latest developments, come see my NCCL talk at GTC.