
This post was updated in March 2023. Sign up for the latest Speech AI news from NVIDIA.
Speech AI is used in a variety of applications, including contact centers’ agent assists for empowering human agents, voice interfaces for intelligent virtual assistants (IVAs), and live captioning in video conferencing. To support these features, speech AI technology includes automatic speech recognition (ASR) and text-to-speech (TTS). The ASR pipeline takes raw audio and converts it to text, and the TTS pipeline takes the text and converts it to audio.
Developing and running real-time speech AI services is complex and difficult. Building speech AI applications requires hundreds of thousands of hours of audio data, tools to build and customize models based on your specific use case, and scalable deployment support.
It also means running in real time, with low latency far under 300 ms to interact naturally with users. NVIDIA Riva streamlines the end-to-end process of developing speech AI services and provides real-time performance for human-like interactions.
NVIDIA Riva SDK
NVIDIA Riva is a GPU-accelerated SDK for building and deploying fully customizable, real-time speech AI applications that deliver accurately in real time. These applications can be deployed on-premises, in the cloud, embedded, and on the edge. NVIDIA Riva is designed to help you access speech AI functionalities easily and quickly. With a few commands, you can access the high-performance services through API operations and try demos.
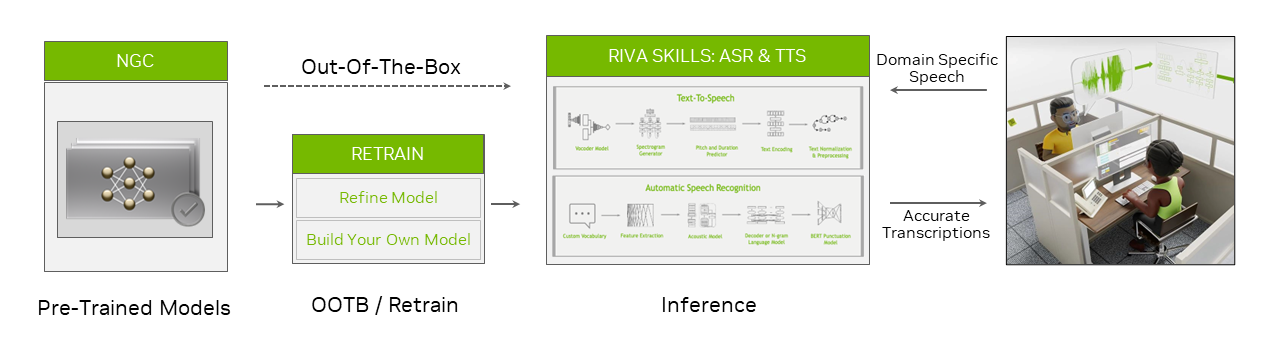
The NVIDIA Riva SDK includes pretrained speech AI models that can be fine-tuned on a custom dataset, and optimized end-to-end skills for automatic speech recognition and speech synthesis.
Using Riva, you can fully customize state-of-art models on your data to achieve a deeper understanding of their specific contexts. Optimize for inference to offer services that run in real time (less than 150 ms).
Task-specific AI services and gRPC endpoints provide out-of-the-box, high-performance ASR and TTS. These AI services are trained with thousands of hours of public and internal datasets to reach high accuracy. You can start using the pre-trained models or fine-tune them with your own dataset to further improve model performance.
Riva uses NVIDIA Triton Inference Server to serve multiple models for efficient and robust resource allocation and to achieve high performance in terms of high throughput, low latency, and high accuracy.
Overview of NVIDIA Riva skills
Riva provides highly optimized automatic speech recognition and speech synthesis services for use cases like real-time transcription and intelligent virtual assistants. The automatic speech recognition skill is available in English, Spanish, Mandarin, Hindi, Korean, Portuguese, French, German, and Russian.
It is trained and evaluated on a wide variety of real-world, domain-specific datasets. With telecommunications, podcasting, and healthcare vocabulary, it delivers world-class production accuracy. To learn more, see Exploring Unique Applications of Automatic Speech Recognition Technology.
The Riva text-to-speech or speech synthesis skill generates human-like speech. It uses non-autoregressive models to deliver 12x higher performance on NVIDIA A100 GPUs compared to Tacotron 2 and WaveGlow models on NVIDIA V100 GPUs. Furthermore, with TTS you can create a natural custom voice for every brand and virtual assistant with only 30 minutes of voice data.

To take full advantage of the computational power of the GPUs, Riva skills uses NVIDIA Triton Inference Server to serve neural networks and ensemble pipelines to run efficiently with NVIDIA TensorRT.
Riva services are exposed through API operations accessible by gRPC endpoints that hide all the complexity. Figure 3 shows the system’s server-side. The gRPC API operations are exposed by the API server running in a Docker container. They are responsible for processing all the speech incoming and outgoing data.
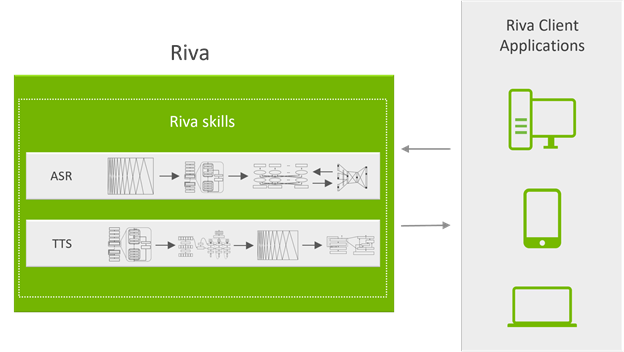
The API server sends inference requests to NVIDIA Triton and receives the results.
NVIDIA Triton is the backend server that simultaneously processes multiple inference requests on multiple GPUs for many neural networks or ensemble pipelines.
It is crucial for speech AI applications to keep the latency below a given threshold. This latency requirement translates into the execution of inference requests as soon as they arrive. To make the best use of GPUs to increase performance, you should increase the batch size by delaying the inference execution until more requests are received, forming a bigger batch.
NVIDIA Triton is also responsible for the context switch of networks with the state between one request and another.
Riva can be installed directly on bare-metal through simple scripts that download the appropriate models and containers from NGC, or it can be deployed on Kubernetes through a Helm chart, which is also provided.
Querying NVIDIA Riva services
Here’s a quick look at how you can interact with Riva. A Python interface makes communication with a Riva server easier on the client side through simple Python API operations. For example, here’s how a request for an existing TTS Riva service is created in four steps.
First, import the Riva API and other useful or required libraries:
import numpy as np
import IPython.display as ipd
import riva.clientNext, create a gRPC channel to the Riva endpoint:
auth = riva.client.Auth(uri='localhost:50051')
riva_tts = riva.client.SpeechSynthesisService(auth)Then, configure the TTS API parameters:
sample_rate_hz = 44100
req = {
"language_code" : "en-US",
"encoding" : riva.client.AudioEncoding.LINEAR_PCM,
"sample_rate_hz" : sample_rate_hz,
"voice_name" : "English-US.Female-1"
}Finally, create a TTS request:
req["text"] = "Is it recognize speech or wreck a nice beach?"
resp = riva_tts.synthesize(**req)
audio_samples = np.frombuffer(resp.audio, dtype=np.int16)
ipd.Audio(audio_samples, rate=sample_rate_hz)Customizing a model with your data
While Riva’s default models are powerful, engineers might need to customize them in developing speech AI applications. Specific contexts where customizing ASR pipeline components can further optimize the transcription of audio data include the following:
- Different accents, dialects, or even languages from those on which the models were initially trained
- Domain-specific vocabulary, such as academic, scientific, or business jargon
- Preferencing or de-preferencing certain words, for example, to account for one word in a set of homophones making more sense in the current context
- Noisy environments
You might also wish to customize a TTS model, so that the synthesized voice assumes a particular pitch or accent or possibly mimics your own voice.
With NVIDIA NeMo, you can fine-tune ASR, TTS, and NLP models on domain- or application-specific datasets (Figure 4), or even train the models from scratch.
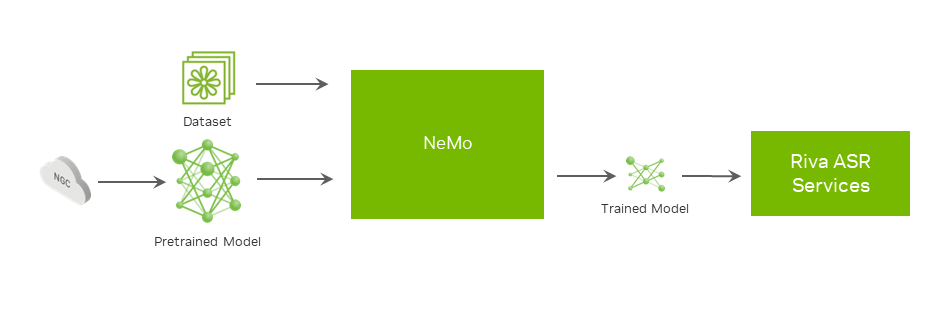
Exploring one such customization in more detail, to further improve the legibility and accuracy of an ASR transcribed text, you can add a custom punctuation and capitalization model to the ASR system that generates text without those features.
Starting from a pretrained BERT model, the first step is to prepare the dataset. For every word in the training dataset, the goal is to predict the following:
- The punctuation mark that should follow the word
- Whether the word should be capitalized
After the dataset is ready, the next step is training by running a previously provided script. When the training is completed and the desired final accuracy is reached, create the model repository for NVIDIA Triton by using an included script.
The NVIDIA Riva Speech Skills documentation contains ASR customization best practices and more details about how to train or fine-tune other models. This post shows only one of the many customization possibilities using NVIDIA NeMo.
Deploying a model in NVIDIA Riva
Riva is designed for speech AI at scale. To help you efficiently serve models across different servers robustly, NVIDIA provides push-button model deployment using Helm charts (Figure 5).
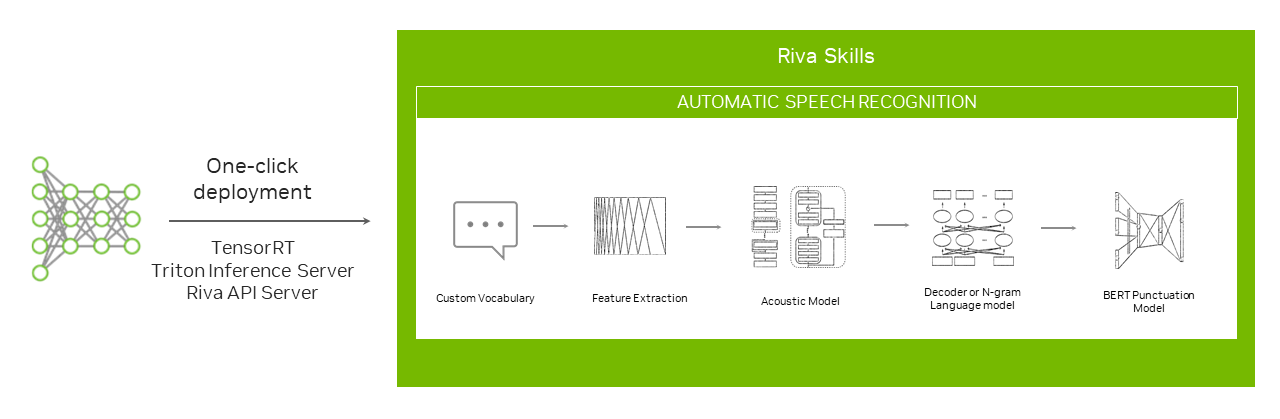
The Helm chart configuration, available from the NGC catalog, can be modified for custom use cases. You can change settings related to which models to deploy, where to store them, and how to expose the services.
Conclusion
NVIDIA Riva containers and pretrained models are available for free as a 90-day trial on NVIDIA NGC to members of the NVIDIA Developer program. With these resources, you can begin testing applications with real-time transcription, virtual assistants, or custom voice synthesis.
Get unlimited usage on all clouds, access to NVIDIA AI experts, and long-term support for production deployments with your purchase of NVIDIA Riva. For more information, contact us.
If you are ready to deploy Riva speech AI skills, check out Riva Getting Started to deliver an interactive voice experience for any application.
