
Deep neural network (DNN) models are routinely used in applications requiring analysis of video stream content. These may include object detection, classification, and segmentation. Typically, these models are trained on servers with high-end GPUs, either in stand-alone servers, such as NVIDIA DGX1, or on servers available in data centers or private or public clouds.
Such systems often use floating-point 32-bit arithmetic to take advantage of the wider dynamic range for the weights. After a model is trained, however, it often must be deployed at the edge on hardware that has less computational resources. It is advantageous in many cases to use 8-bit integer numbers for weights. The challenge is that simply rounding the weights after training may result in a lower accuracy model, especially if the weights have a wide dynamic range.
In this post, you learn about training models that are optimized for INT8 weights. During training, the system is aware of this desired outcome, called quantization-aware training (QAT).
Quantizing a model
Quantization is the process of transforming deep learning models to use parameters and computations at a lower precision. Traditionally, DNN training and inference have relied on the IEEE single-precision floating-point format, using 32 bits to represent the floating-point model weights and activation tensors. For more information, see Automatic Mixed Precision.
This compute budget may be acceptable at training as most DNNs are trained in data centers or in the cloud with NVIDIA V100 or A100 GPUs that have significantly large compute capability and much larger power budgets. However, during deployment, these models are most often required to run on devices with much smaller computing resources and lower power budgets at the edge. Running a DNN inference using the full 32-bit representation is not practical for real-time analysis given the compute, memory, and power constraints of the edge.
To help reduce the compute budget, while not compromising on the structure and number of parameters in the model, you can run inference at a lower precision. Initially, quantized inferences were run at half-point precision with tensors and weights represented as 16-bit floating-point numbers. While this resulted in compute savings of about 1.2–1.5x, there was still some compute budget and memory bandwidth that could be leveraged. In lieu of this, models are now quantized to an even lower precision, with an 8-bit integer representation for weights and tensors. This results in a model that is 4x smaller in memory and about 2–4x faster in throughput.
While 8-bit quantization is appealing to save compute and memory budgets, it is a lossy process. During quantization, a small range of floating-point numbers are squeezed to a fixed number of information buckets. This results in loss of information.
The minute differences which could originally be resolved using 32-bit representations are now lost because they get quantized to the same bucket in 8-bit representations. This is like the rounding errors that one encounters when representing fractional numbers as integers. To maintain accuracy during inferences at lower precision, it is important to try and mitigate errors arising due to this loss of information.
NVIDIA TAO Toolkit attempts to model this loss of information due to quantization in two ways: post-training quantization (PTQ) and QAT.
Post-training quantization
This method, as the name suggests, is applied to a model after it has been trained in TAO Toolkit. The training happens with weights and activations represented as 32-bit floating-point numbers. After the training is complete with a satisfactory model accuracy, the model is then calibrated using the TensorRT INT8 entropy calibrator.
The IInt8EntropyCalibratorV2 from TensorRT calibrates a model when building an INT8 engine. For more information about how TensorRT generates the INT8 scale files, see the INT8 Calibration Using C++. For more information about how to calibrate a model post-training, see the TAO Toolkit User Guide.
While PTQ provides an easy way to model quantization errors, there is an inherent assumption that the weights of the trained model can be effectively scaled to a smaller range. However, there are cases where this scaling cannot preserve the statistics of the model weights. One such example is the PeopleNet model on NGC. The model was trained with tensors represented in FP32 mode and calibrated using the TensorRT INT8 entropy calibrator. The resulting TensorRT engine, however, produced several spurious bounding boxes, as shown in Figure 1, causing a regression in the model accuracy.

Quantization-aware training
In QAT, as opposed to computing scale factors to activation tensors after the DNN is trained, the quantization error is considered when training the model. The training graph is modified to simulate the lower precision behavior in the forward pass of the training process. This introduces the quantization errors as part of the training loss, which the optimizer tries to minimize during the training. Thus, QAT helps in modeling the quantization errors during training and mitigates its effects on the accuracy of the model at deployment.
However, the process of modifying the training graph to simulate lower precision behavior is intricate. You must modify the training code to insert FakeQuantization nodes for the weights of the DNN Layers and Quantize-Dequantize (QDQ) nodes to the intermediate activation tensors to compute their dynamic ranges.
The placement of these QDQ nodes is also critical so as not to affect the learning capabilities of the model. Because these models are intended for deployment with the TensorRT inference platform, take care to include the QDQ nodes only at the end of the fused compute block. For example, TensorRT combines the Conv -> Bias -> ReLU and Conv -> Bias -> BatchNormalization -> ReLU compute blocks. In that case, adding a QDQ layer only makes sense to the output tensor of the ReLU activation. For more information, see Quantization-Aware Training.
Not all activation layer types are friendly to quantization. For example, networks with regression layers typically require that the output tensors of these layers not be bound by the range of the 8-bit quantization and they may require finer granularity in representation than 8-bit quantization can provide. These layers work best if they are excluded from quantization.
Running quantization-aware training with TAO Toolkit
Training a model with TAO Toolkit requires no code development on your part. TAO Toolkit abstracts all the requirements of implementing an effective QAT graph. To train with quantization awareness, add a flag in the training_config component of the training spec file. This triggers the train command to parse through the model graph and modify it to enable quantization of weights and activations during the forward pass and effectively train the model. Figure 2 shows the recommended workflow to generate an INT8 deployable model from QAT.
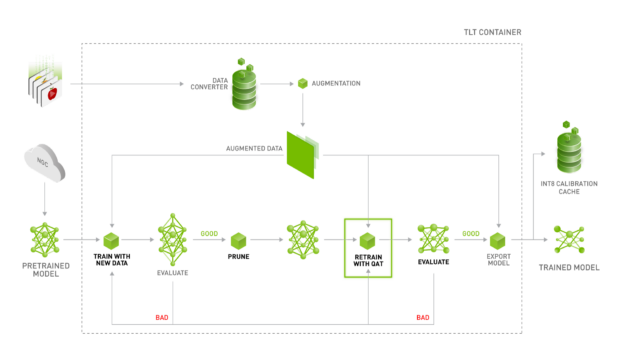
- Train an unpruned object detection model.
- Prune the trained model to get the most compute savings possible without compromising accuracy, using
prune. - Retrain this model with QAT enabled.
- Evaluate the retrained model to check for recovered accuracy with the unpruned model.
- Export the model to generate an .etlt file and INT8 calibration cache that may be read by the DeepStream SDK or the
converterto generate a TensorRT engine. You may also generate a TensorRT engine duringexport; however, this engine is only deployable on the hardware thatexportwas run on. - Evaluate the generated TensorRT engine on the validation set using
evaluate. QAT is not supported for classification and MaskRCNN models.
As an example use case, I discuss how to train a QAT-enabled version of the TAO Toolkit PeopleNet model that is suitable for deployment with integer precision (8-bit representations). For more information about training a DetectNet_v2 model using the PeopleNet model as pretrained weights, see Training with Custom Pretrained Models Using the NVIDIA TAO Toolkit.
I recommend following the steps to train an unpruned DetectNet_v2 model and pruning it to generate a significantly smaller pruned model.
After the pruned model is generated, update the model_config component on the re-training spec file to do the following:
- Include the pruned model as the pretrained weights.
- Set the
load_graphflag to true, so that the newly pruned model structure is imported.
The following code example shows the updated model config:
model_config {
pretrained_model_file: "/path/to/pruned/model"
load_graph: true
num_layers: 34
arch: "resnet"
use_batch_norm: true
objective_set {
bbox {
scale: 35.0
offset: 0.5
}
cov {
}
}
training_precision {
backend_floatx: FLOAT32
}
}
Next, update the training_config component of the re-training spec file to set the enable_qat flag:
training_config {
batch_size_per_gpu: 24
num_epochs: 120
enable_qat: true
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 5e-06
max_learning_rate: 0.0005
soft_start: 0.1
annealing: 0.7
}
}
regularizer {
type: L1
weight: 3e-09
}
optimizer {
adam {
epsilon: 9.9e-09
beta1: 0.9
beta2: 0.999
}
}
cost_scaling {
initial_exponent: 20.0
increment: 0.005
decrement: 1.0
}
checkpoint_interval: 10
}
The remaining spec file components may remain identical to the spec file from training the unpruned model:
dataset_configevaluation_configaugmentation_configpostprocessing_configbbox_rasterizer_configcost_function_config
For more information about these components, see Training with Custom Pretrained Models Using the NVIDIA TAO Toolkit and the TAO Toolkit Getting Started Guide.
To run training for this model, use the train command with the updated spec file. The sample command line usage for the train command is as follows:
tao train detectnet_v2 -e $spec_file_path \ -r $experiment_dir_pruned_qat \ -k $KEY \ -n $model_file_string \ --gpus $N
The following variables are defined:
$KEY: Key string to load the model.$experiment_dir_pruned_qat: UNIX-style path to the output results directory.$N: Number of GPUs to be used during training.$spec_file_path: UNIX-style path to the training specification file.$model_file_string: String name for the final model file stored after the training run is complete.- The model output is found at
$experiment_dir_pruned_qat/weights/$model_file_string.tlt
- The model output is found at
When the training is complete, you may verify the accuracy of this model by evaluating the model on a validation dataset using the evaluate command:
tao evaluate detectnet_v2 \ -e $spec_file_path \ -m $experiment_dir_pruned_qat/weights/$model_file_string.tlt \ -k $KEY \
The average precision (AP) per class is computed as per the Pascal VOC evaluation guidelines mentioned in the Pascal VOC challenge and printed out on the terminal along with the mean average precision (mAP) metric of the model. For more information about the compiled results for a QAT and non-QAT–trained model, see the Results section in this post.
The mAP computed here is close to the mAP of the model trained without QAT enabled. After the model is deemed satisfactory, it may be exported using the export command. The export command parses the model graph looking for quantized nodes and peels them out to generate an .etlt model file, along with a corresponding calibration_cache file that contains dynamic range scale factors for the intermediate activation tensors. The etlt_model file and the calibration_cache file can be consumed by the converter to generate a low precision (8-bit) TensorRT engine or used directly with the DeepStream SDK.
The following code example shows usage for the export command:
tao export detectnet_v2 -m $experiment_dir_pruned_qat/weights/$model_file_string.tlt \ -o $output_model_path \ -k $KEY \ --data_type int8 \ --batch_size N \ --cal_cache_file $calibration_cache_file \ --engine_file $engine_file_path
The following variables are defined:
$output_model_path: UNIX path to the output .etlt model file.$KEY: String key to load the model and save the .etlt model file.--data_type: Precision of the TensorRT file (to be set to INT8 to generate the calibration cache).N: The batch-size value for the output TensorRT engine.$calibration_cache_file: UNIX path to the output cache file containing the scales for the activation tensors.$engine_file_path: UNIX path to the output TensorRT engine file.
The engine generated using the export command can only be used to run inference on the platform on which the export command was run. To deploy this model on a different platform, run the converter on the inference platform using the .etlt model file along with calibration_cache.
When deploying on the Jetson platform, edit the first line of the calibration_cache file in a text editor to reflect the TensorRT version of the corresponding JetPack build. For example, for JP4.4, update the TensorRT version number in the first line from 7000 to 7100.
The QAT-generated calibration cache files are compatible only for deployment in GPU cores, both in discrete x86-based GPUs (NVIDIA T4, V100, and A100) and in NVIDIA Jetson platforms (AGX Xavier and Xavier NX).
The model generated using the export command used earlier is not compatible for deployment on INT8 mode in the DLA. To deploy this model with the DLA, you must generate the calibration cache file using PTQ on the QAT-trained .tlt model file. You can do this by setting the force_ptq flag over the command line when running export. A sample export command with this flag set for exporting a DetectNet_v2 model would look like the following example:
tao export detectnet_v2 \ -e $spec_file_path \ -m $experiment_dir_pruned_qat/weights/$model_file_string.tlt \ -o $output_model_path \ -k $KEY \ --data_type int8 \ --batch_size N \ --cal_cache_file $calibration_cache_file \ --engine_file $engine_file_path \ --force_ptq
Using the force_ptq option omits the scale factors from the model and generates scale factors using the TensorRT IInt8EntroplyCalibrator2, on the QAT-trained model. This method generates scales for all intermediate tensors in the model. Unlike the GPU, DLA currently doesn’t fuse Conv -> Bias -> ReLU and Conv -> Bias -> BatchNormalization -> ReLU blocks into a single operator. Therefore, quantization scales are required for all the intermediate tensors. For more information about the usage of the detectnet_v2 subtasks train, evaluate, prune, export, and converter, see the TAO Toolkit Getting Started Guide.
To deploy the PeopleNet v2.0 model on the DLA using INT8 mode, we generated the quantization scales using the force_ptq mode of export and evaluated the model using evaluate. The results are tabulated in Purpose-built models.
Results
Table 1 shows the accuracy comparison for the INT8 models trained with QAT compared to an FP32-trained model deployed in INT8 mode using PTQ. The numbers are compared against baseline FP32 accuracy.
When trained using QAT, the accuracy difference is within 1% with respect to baseline FP32. When we applied PTQ on the same model, the accuracy drops significantly, making the model unusable. QAT is an effective training technique for running inference at INT8 precision.
| Baseline FP32 mAP | INT8 mAP with PTQ | INT8 mAP with QAT | |
| PeopleNet-ResNet18 | 78.37 | 59.06 | 78.06 |
| PeopleNet-ResNet34 | 80.2 | 62 | 79.57 |
Being able to maintain similar accuracy with the INT8 model for the same model architecture provides significant inference performance boost on the same hardware. Table 2 compares the inference performance on T4 for the two PeopleNet models for FP16 and INT8 precision. On average across these two models, we see almost 2x increase in inference FPS. This means that you can effectively double the number of streams on your deployment platform without changing model architecture or GPU.
| FP16 inference performance (FPS) | INT8 inference performance (FPS) | |
| PeopleNet-ResNet18 | 762 | 1517 |
| PeopleNet-ResNet34 | 513 | 1038 |
The sample prediction included here shows the same image from Figure 1 but is running inference on the INT8 model trained with QAT enabled. The spurious detections are now eliminated, and accuracy has improved significantly.

Conclusion
Quantization-aware training helps you train DNNs for lower precision INT8 deployment, without compromising on accuracy. This is achieved by modeling quantization errors during training which helps in maintaining accuracy as compared to FP16 or FP32. Although PTQ is still supported with TAO Toolkit, I recommend training with QAT when planning to deploy using INT8 precision.
In this post, the PeopleNet model was used as a sample to walk you through the process of training a model with QAT, but it can also be used with the other object detection models supported in TAO Toolkit. For more information about QAT, see Training the model in the TAO Toolkit User Guide.
