Deep Neural Networks (DNNs) have lead to breakthroughs in a number of areas, including image processing and understanding, language modeling, language translation, speech processing, game playing, and many others. DNN complexity has been increasing to achieve these results, which in turn has increased the computational resources required to train these networks. Mixed-precision training lowers the required resources by using lower-precision arithmetic, which has the following benefits.
- Decrease the required amount of memory. Half-precision floating point format (FP16) uses 16 bits, compared to 32 bits for single precision (FP32). Lowering the required memory enables training of larger models or training with larger minibatches.
- Shorten the training or inference time. Execution time can be sensitive to memory or arithmetic bandwidth. Half-precision halves the number of bytes accessed, thus reducing the time spent in memory-limited layers. NVIDIA GPUs offer up to 8x more half precision arithmetic throughput when compared to single-precision, thus speeding up math-limited layers.
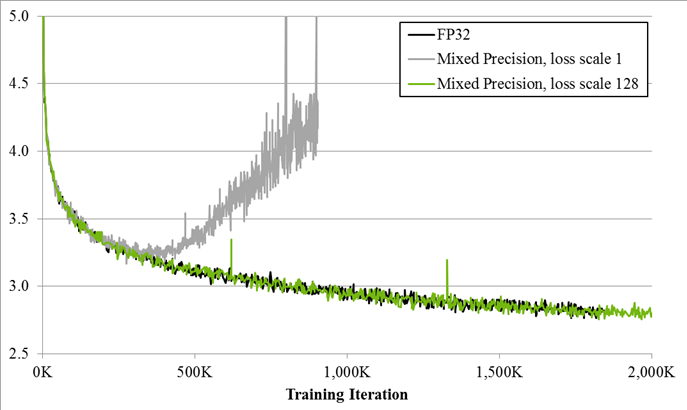
Since DNN training has traditionally relied on IEEE single-precision format, the focus of new joint work from NVIDIA and Baidu is on training with half precision while maintaining the network accuracy achieved with single precision (as the chart above shows). This technique is called mixed-precision training since it uses both single- and half-precision representations.
Read more >