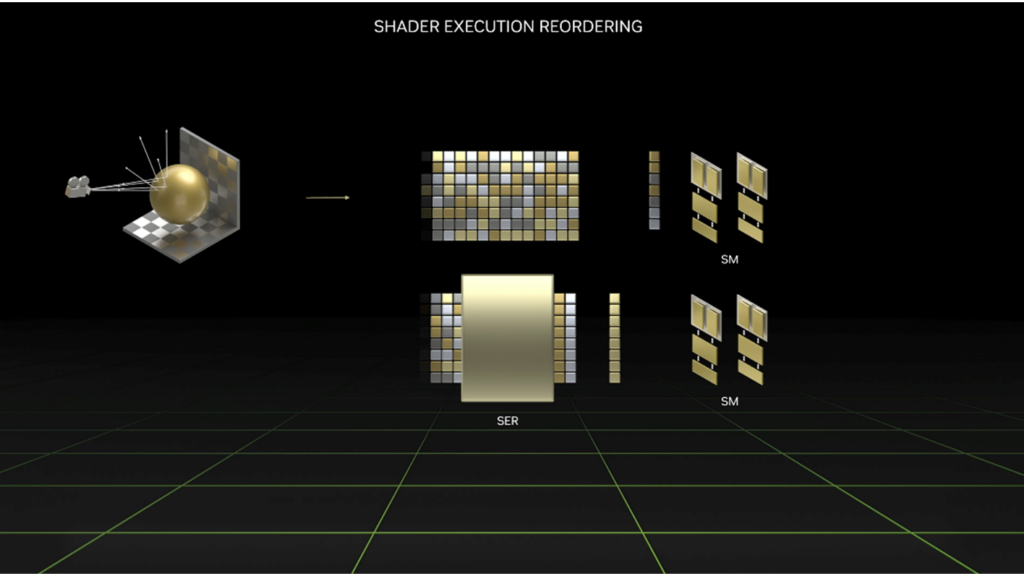
NVIDIA recently introduced a new feature available in the next generation of GPUs: Shader execution reordering (SER). SER is a performance optimization that unlocks the potential for better ray and memory coherency in ray tracing shaders and thus increased shading efficiency.
Background
Shading divergence is a long-standing problem in ray tracing. With increasingly complex renderer implementations, more workloads are becoming limited by shader execution rather than the tracing of rays. One way to mitigate this problem is to reduce the divergence affecting the GPU when executing shader code.
SER helps to alleviate two types of divergence:
- Execution divergence: Occurs when different threads execute different shaders or branches within a shader.
- Data divergence: Occurs when different threads access memory resources in patterns that are hard to cache.
SER mitigates divergence by reordering threads, on the fly, across the GPU so that they can continue execution with increased coherence. It also enables the decoupling of ray intersection and shading.
For more information, see the Shader Execution Reordering whitepaper.
Integration using the NVIDIA API
To access the feature set and optimizations provided by SER, you need the following:
- A GPU that supports DXR 1.0 or higher
- A driver that supports SER, R520, and newer
- HLSL extension headers, which can be found in the latest NVIDIA API
- Link against nvapi64.lib, included in the packages containing the HLSL headers
- (Optional) A recent version of DXC (dxcompiler.dll) that supports templates. If you’re compiling shaders from Visual Studio, make sure that your project is configured to use this version of the compiler executable.
Get started with SER and NVIDIA API.
Initialize NVAPI and enable SER API
First, initialize and deinitialize NVAPI using the following call:
NvAPI_Initialize();
NvAPI_Unload();
Next, verify that the SER API is supported, using the following call:
bool supported = false;
NvAPI_D3D12_IsNvShaderExtnOpCodeSupported(pDevice, NV_EXTN_OP_HIT_OBJECT_REORDER_THREAD, &supported);
if (!supported)
{
/* Don't use SER */
}
Host-side integration
Before ray tracing state object creation, set up a fake UAV slot and register it:
#define NV_SHADER_EXTN_SLOT 999999 // pick an arbitrary unused slot
#define NV_SHADER_EXTN_REGISTER_SPACE 999999 // pick an arbitrary unused space
NvAPI_D3D12_SetNvShaderExtnSlotSpace(pDevice, NV_SHADER_EXTN_SLOT, NV_SHADER_EXTN_REGISTER_SPACE);
If you need a thread-local variant, use the related function: NvAPI_D3D12_SetNvShaderExtnSlotSpaceLocalThread.
Next, add the fake UAV slot to the global root signature used to compile ray tracing pipelines. You do not have to allocate or bind a resource for this. The following example shows augmenting D3D12 sample code with a fake UAV slot, highlighted here. The root signature creation in your application will likely look quite different.
// Global Root Signature
// This is a root signature that is shared across all raytracing shaders invoked during a DispatchRays() call.
{
CD3DX12_DESCRIPTOR_RANGE ranges[5]; // Perfomance TIP: Order from most frequent to least frequent.
ranges[0].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0); // output texture
ranges[1].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 2, 0, 1); // static index buffers
ranges[2].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 2, 0, 2); // static vertex buffers
ranges[3].Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 1, 0, 3); // static vertex buffers
// fake UAV for shader execution reordering
ranges[4].Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, NV_SHADER_EXTN_SLOT, NV_SHADER_EXTN_REGISTER_SPACE);
CD3DX12_ROOT_PARAMETER rootParameters[GlobalRootSignatureParams::Count];
rootParameters[GlobalRootSignatureParams::OutputViewSlot].InitAsDescriptorTable(1, &ranges[0]);
rootParameters[GlobalRootSignatureParams::AccelerationStructureSlot].InitAsShaderResourceView(0);
rootParameters[GlobalRootSignatureParams::SceneConstantSlot].InitAsConstantBufferView(0);
rootParameters[GlobalRootSignatureParams::VertexBuffersSlot].InitAsDescriptorTable(3, &ranges[1]);
rootParameters[GlobalRootSignatureParams::SerUavSlot].InitAsDescriptorTable(1, &ranges[4]);
CD3DX12_ROOT_SIGNATURE_DESC globalRootSignatureDesc(ARRAYSIZE(rootParameters), rootParameters);
SerializeAndCreateRaytracingRootSignature(globalRootSignatureDesc, &m_raytracingGlobalRootSignature);
}
Use of API in shader code
In shader code, define the fake UAV slot and register again, using the same values:
#define NV_SHADER_EXTN_SLOT u999999 // matches slot number in NvAPI_D3D12_SetNvShaderExtnSlotSpace
#define NV_SHADER_EXTN_REGISTER_SPACE space999999 // matches space number in NvAPI_D3D12_SetNvShaderExtnSlotSpace
#include "SER/nvHLSLExtns.h"
Now the SER API may be used in ray generation shaders:
NvHitObject hitObject = NvTraceRayHitObject(TLAS, RAY_FLAG_NONE, 0xff, 0, 1, 0, ray, payload);
NvReorderThread(hitObject, 0, 0);
NvInvokeHitObject(TLAS, hitObject, payload);
When compiling HLSL to DXIL, do one of the following:
- Ensure that templates are enabled in DXC by specifying the command line argument
-HV 2021 - Use the macro version of the API that does not require templates. The macro version can be enabled by defining
NV_HITOBJECT_USE_MACRO_APIbefore includingnvHLSLExtns.h. This is intended for use in legacy codebases that have difficulty switching to HLSL 2021. The recommended path is using templates if the codebase can support it.
Integration of Unreal Engine 5 NvRTX
Unreal Engine developers can take advantage of SER within the NVIDIA branch of Unreal Engine (NvRTX). The following section explains how SER provides performance gains in ray tracing operations and provides optimization tips for specific use cases.
The NVIDIA Unreal Engine 5 NvRTX 5.0.3 release will feature SER integration to support the optimization of many of its ray tracing paths. With SER, you’ll see additional frame rate optimization on 40 series cards with up to 40% increased speeds in ray tracing operations and zero impact on quality or content authoring. This improves the efficiency of complex ray tracing calculations and provides greater gains in scenes that take full advantage of what ray tracing has to offer.
Benefits of SER in Unreal Engine 5
SER in Unreal Engine 5 (UE5) enables better offline path tracing, which is arguably the most complex tracing operation in UE5. Likewise, hardware ray-traced reflections and translucency will also see benefits, as they have complex interactions with materials and lighting.
SER also improves Lumen performance when hardware ray tracing is enabled. In some cases, the changes required to do this, independent of initial system complexity, are trivial. In other cases, it has added substantial complexity. Three different examples are explored in more detail:
- Simple case: Path tracing
- Unusual case: Work compaction in Lumen global illumination
- Complex case: Lumen reflections
Simple case: Path tracing
Path tracing presents a highly divergent workflow, making it a great candidate for applying SER.

Applying SER enables the path tracer to reduce divergence in its material evaluation, instead of just on the number of bounces. This offers a 20-50% gain in performance with the following code change:
#if !PATH_TRACER_USE_REORDERING
// Trace the ray, including evaluation of hit data
TraceRay(
TLAS,
RayFlags,
RAY_TRACING_MASK_ALL,
RAY_TRACING_SHADER_SLOT_MATERIAL,
RAY_TRACING_NUM_SHADER_SLOTS,
MissShaderIndex,
PathState.Ray,
PackedPayload);
#else
{
NvHitObject Hit;
// Trace ray to produce hit object
NvTraceRayHitObject(TLAS, RayFlags, RAY_TRACING_MASK_ALL, RAY_TRACING_SHADER_SLOT_MATERIAL, RAY_TRACING_NUM_SHADER_SLOTS, MissShaderIndex, PathState.Ray, PackedPayload, Hit);
// Reorder threads to have coherent hit evaluation
NvReorderThread(Hit);
// Evaluate hit data in the now coherent environment
NvInvokeHitObject(TLAS, Hit, PackedPayload);
}
#endif
This improvement can be accomplished by replacing the DXR TraceRay function with an equivalent set of NvTraceRayHitObject, NvReorderThread, and NvInvokeHitObject.
A key aspect is that the optimization is only applied selectively. The change only applies to the TraceTransparentRay function within the UE5 path-tracing code, as this is the source of most material evaluation divergence. Other rays are performing cheaper operations and are less important to reorder, so they may not be worth the extra cost of attempting to reorder.
This example is the tip of the iceberg when it comes to the potential of the path tracer code. More careful analysis will almost certainly allow additional gains, including possibly eliminating the need to use multiple passes to compact longer rays.
Unusual case: Work compaction in Lumen global illumination
Typically, you might think of reordering to handle the execution divergence experienced by hit shading. While the ray tracing passes used in Lumen global illumination do not run a divergent hit shader, they still benefit from the mechanisms provided by SER.
For large scenes, like the UE5 City Sample, traces are broken into the near and far field, which are run as separate tracing passes with compaction in between. The multiple passes and compaction can be replaced by a single NVReorderThread call. This avoids the idle bubbles on the GPU required to compact the results of near-field tracing, and then launch far-field rays.
| Without SER | With SER |
| Trace near field Compact misses Trace far field | Trace near and far with compaction |
Removing the extra overhead of storing, compacting, and relaunching work is often worth a 20% savings. The shader changes can be more intensive due to assumptions in the original code (functions using macros to permute behaviors rather than arguments). However, the logical changes amounted to adding two reorder calls with a single Boolean expression for whether a trace had hit or missed.
Complex case: Lumen reflections
Lumen is a system contained in UE5 that implements global illumination and reflections. It has a high degree of complexity, and a thorough discussion of it is well beyond the scope of this post. This description is heavily distilled and focuses on one specific configuration: Lumen reflections with hardware ray tracing (HWRT) hit lighting enabled. Lumen can also use software ray tracing by way of signed distance fields, which is not discussed in this post.
To render reflections, the Lumen HWRT hit lighting path uses multiple passes:
- Near field tracing: extract material ID
- Compact rays.
- (Optional) Far field tracing: extract material ID.
- Compact rays.
- (Optional) Append far-field rays.
- Sort rays by material.
- Re-trace with hit lighting.
The following important details about how Lumen works help explain the differences in approach between SER and non-SER:
- Near field and far field in Lumen correspond with different sections of the TLAS for objects close to the camera and objects far away from the camera, respectively. Both near field and far field are contained in the same TLAS.
- Two different ray-tracing pipelines are used in the preceding passes. Near and far field both use a simplified (fast) tracing path, while hit lighting has full material support. This is the reason for the separate re-tracing path with hit lighting.
For more information about these passes, see Lumen Technical Details.
With SER enabled, the passes can be combined because separate compaction and sorting phases are no longer necessary. The pass roughly becomes as follows:
- Trace near field.
- If not a hit, trace far field.
- If either hit, then use the hit object to evaluate the material and perform lighting.
This is possible due to the decoupling of tracing and shading.
Here are the relevant sections of the shader:
NvHitObject SERHitObject;
// Near field
NvTraceRayHitObject(..., SERHitObject);
NvReorderThread(SERHitObject);
Result.bIsHit = SERHitObject.IsHit();
// Far field
if (!Result.bIsHit)
{
// Transform ray into far field space of TLAS
...
NvTraceRayHitObject(..., SERHitObject);
NvReorderThread(SERHitObject);
Result.bIsHit = SERHitObject.IsHit();
}
// Compute result
if (Result.bIsHit)
{
NvInvokeHitObject(Context.TLAS, SERHitObject, Payload);
Result.Radiance = CalculateRayTracedLighting();
}
// Handle miss
This is one example of the availability of SER creating a higher-level implication on the rendering architecture, rather than just replacing TraceRay with the respective NVAPI equivalent. The implementation described earlier resulted in a 20-30% speed increase in Lumen reflections on the GPU, measured when profiling a typical workload in UE5 City Sample.
Conclusion
Shading divergence can pose performance problems when considering both data and execution. The Shader Execution Reordering API gives you a powerful tool to mitigate these penalties, with relatively little effort required to get started. The optimizations discussed in this post represent only the initial stages of introducing the possibilities provided by SER to a large codebase, such as Unreal Engine 5. We look forward to seeing SER realize more of its potential as its use evolves.
For more information, see the following resources:
