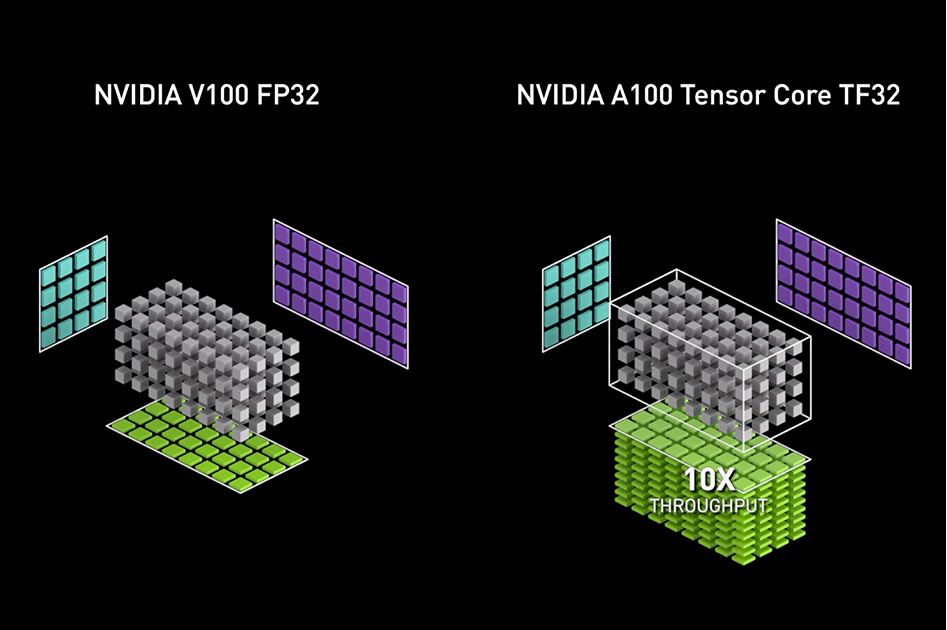
NVIDIA Ampere GPU architecture introduced the third generation of Tensor Cores, with the new TensorFloat32 (TF32) mode for accelerating FP32 convolutions and matrix multiplications. TF32 mode is the default option for AI training with 32-bit variables on Ampere GPU architecture. It brings Tensor Core acceleration to single-precision DL workloads, without needing any changes to model scripts. Mixed-precision training with a native 16-bit format (FP16/BF16) is still the fastest option, requiring just a few lines of code in model scripts. Table 1 shows the math throughput of A100 Tensor Cores, compared to FP32 CUDA cores. It’s also worth pointing out that for single-precision training, the A100 delivers 10x higher math throughput than the previous generation training GPU, V100.
| FP32 | TF32 | FP16 / BF16 |
| 1x | 8x | 16x |
Internals
TF32 is a new compute mode added to Tensor Cores in the Ampere generation of GPU architecture. Dot product computation, which forms the building block for both matrix multiplies and convolutions, rounds FP32 inputs to TF32, computes the products without loss of precision, then accumulates those products into an FP32 output (Figure 1).
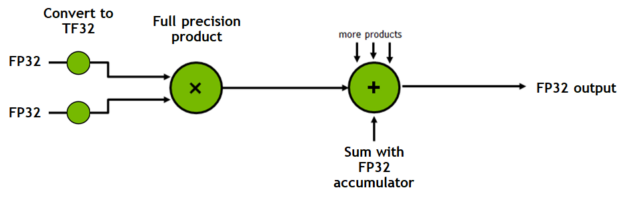
TF32 is only exposed as a Tensor Core operation mode, not a type. All storage in memory and other operations remain completely in FP32, only convolutions and matrix-multiplications convert their inputs to TF32 right before multiplication. In contrast, 16-bit types provide storage, various math operators, and so on.
Numerics
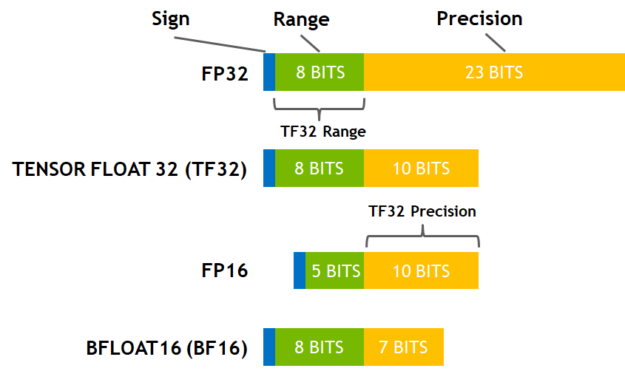
Figure 2 shows the various precision options. TF32 mode in the Ampere generation of GPUs adopts 8 exponent bits, 10 bits of mantissa, and one sign bit. As a result, it covers the same range of values as FP32. TF32 also maintains more precision than BF16 and the same amount as FP16. The precision for TF32 remains the only difference from FP32 and has been shown to have more than sufficient margin for AI workloads with extensive studies.
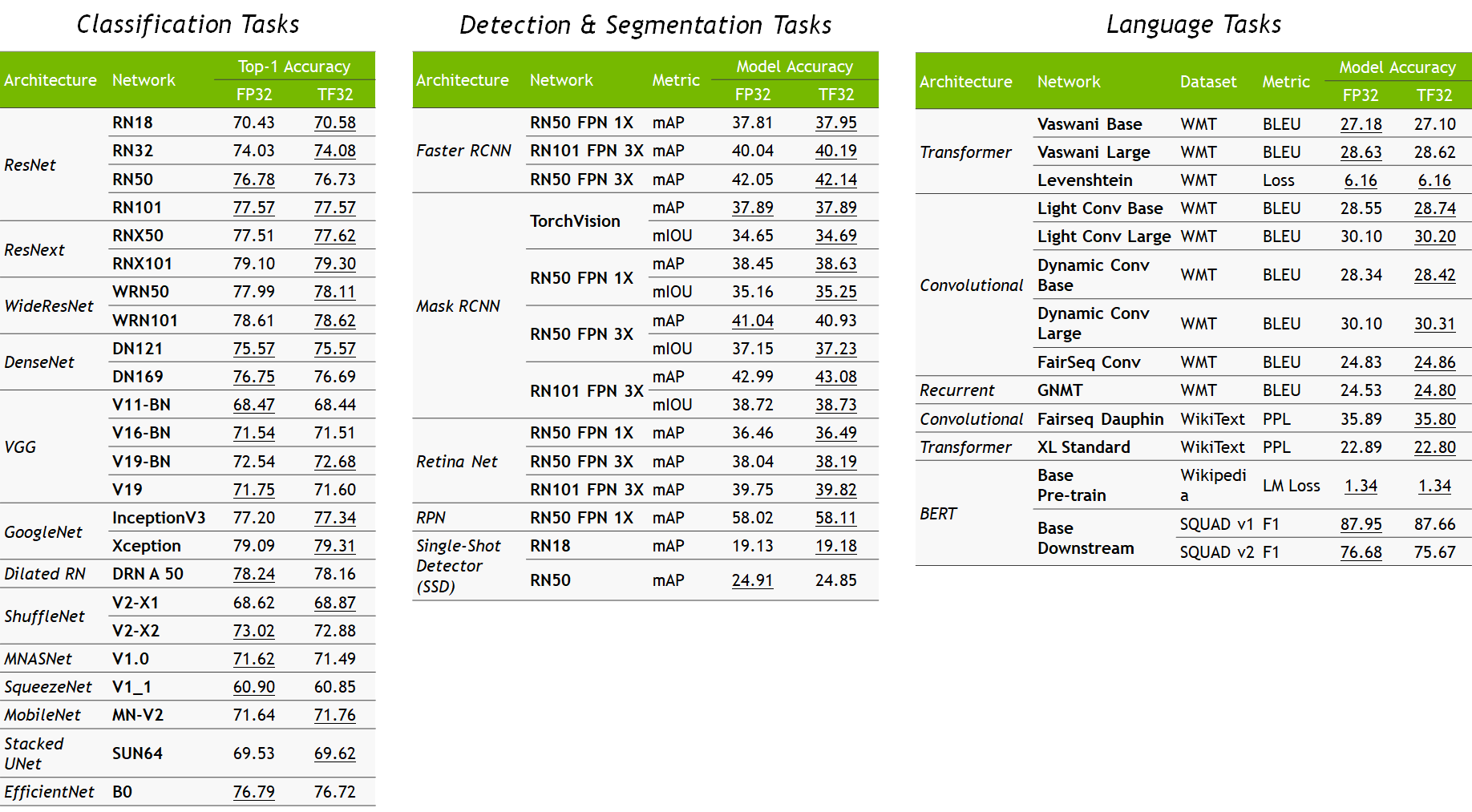
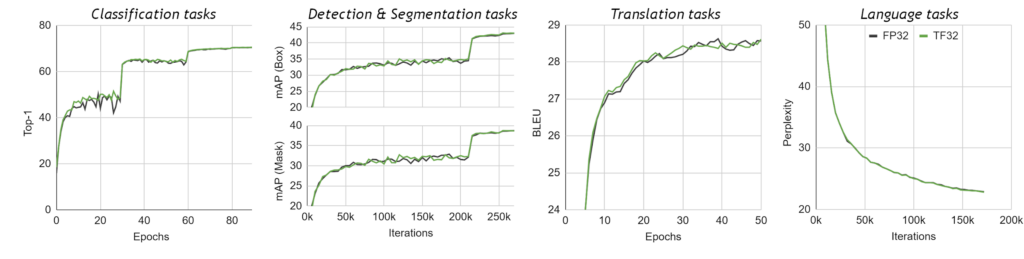
We validated single-precision training in TF32 mode on a wide breadth of AI networks across a variety of applications from computer vision to natural language processing to recommender systems. All the dozens of considered DL workloads match FP32 accuracy, loss values, and training behavior, with no changes to hyperparameters or training scripts. Figure 3 shows a sampling of networks trained. All workloads use identical hyperparameters for training in FP32 and TF32 modes, all differences in accuracy are within respective bounds of run-to-run variation (different random seeds, and so on) for each network. Figure 4 shows the training curves for a few select models on a sampling of networks trained.
Training speedups
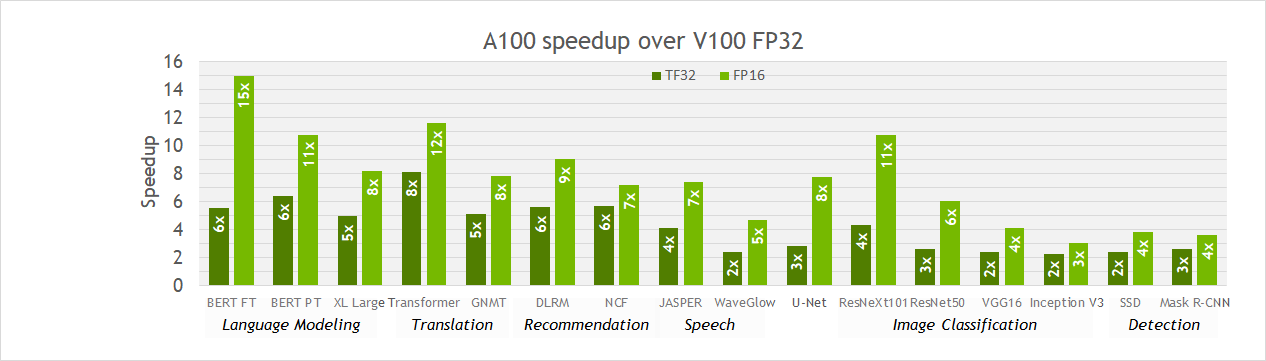
As shown earlier, TF32 math mode, the default for single-precision DL training on the Ampere generation of GPUs, achieves the same accuracy as FP32 training, requires no changes to hyperparameters for training scripts, and provides an out-of-the-box 10X faster “tensor math” (convolutions and matrix multiplies) than single-precision math on Volta GPUs. However, speedups observed for networks in practice vary, since all memory accesses remain FP32 and TF32 mode doesn’t affect layers that are not convolutions or matrix multiplies.
Figure 5 shows that speedups of 2-6x are observed in practice for single-precision training of various workloads when moving from V100 to A100. Furthermore, switching to mixed precision with FP16 gives a further speedup of up to ~2x, as 16-bit Tensor Cores are 2x faster than TF32 mode and memory traffic is reduced by accessing half the bytes. Thus, TF32 is a great starting point for models trained in FP32 on Volta or other processors, while mixed-precision training is the option to maximize training speed on A100.
For researchers
In this section, we summarize everything that you must know to accelerate deep learning workloads with TF32 Tensor Cores.
DL frameworks
TF32 is the default mode for AI on A100 when using the NVIDIA optimized deep learning framework containers for TensorFlow, PyTorch, and MXNet, starting with the 20.06 versions available at NGC. TF32 is also enabled by default for A100 in framework repositories starting with PyTorch 1.7, TensorFlow 2.4, as well as nightly builds for MXNet 1.8. Deep learning researchers can use the framework repositories and containers listed earlier to train single-precision models with benefits from TF32 Tensor Cores.
Operations
TF32 mode accelerates single-precision convolution and matrix-multiply layers, including linear and fully connected layers, recurrent cells, and attention blocks. TF32 does not accelerate layers that operate on non-FP32 tensors, such as 16-bits, FP64, or integer precisions. TF32 also does not apply to layers that are not convolution or matrix-multiply operations (for example, batch normalization), as well as optimizer or solver operations. Tensor storage is not changed when training with TF32. Everything remains in FP32, or whichever format is specified in the script.
For developers
Across the NVIDIA libraries, you see Tensor Core acceleration for the full range of precisions available on A100, including FP16, BF16, and TF32. This includes convolutions in cuDNN, matrix multiplies in cuBLAS, factorizations and dense linear solvers in cuSOLVER, and tensor contractions in cuTENSOR. In this post, we discuss the various considerations for enabling Tensor Cores in NVIDIA libraries.
cuDNN
cuDNN is the deep neural network library primarily used for convolution operations. Convolutional layers in cuDNN have descriptors that describe the operation to be performed, such as the math type. With version 8.0 and greater, convolution operations are performed with TF32 Tensor Cores when you use the default math mode CUDNN_DEFAULT_MATH or specify the math type as CUDNN_TENSOR_OP_MATH. The library internally selects TF32 convolution kernels if they exist when operating on 32-bit data. For Volta and previous versions of cuDNN, the default math option continues to be FP32.
cuBLAS
cuBLAS is used to perform basic dense linear algebra operations such as matrix multiplications that occur in deep neural networks. cuBLAS continues to default to FP32 operations for CUBLAS_DEFAULT_MATH because of the traditional use of cuBLAS in HPC applications, which require more precision.
With version 11.0 and greater, cuBLAS supports TF32 Tensor Core operations with the cublasSetMathMode function, by setting the math mode to CUBLAS_TF32_TENSOR_OP_MATH for legacy BLAS APIs and by setting the compute type to CUBLAS_COMPUTE_32F_FAST_TF32 for the cublasGemmEx and cublasLtMatmul APIs. When these options are selected, the library internally selects TF32 kernels, if available, when operating on 32-bit data.
To get the benefits of TF32, NVIDIA optimized deep learning frameworks set the global math mode state on the cuBLAS handle to CUBLAS_TF32_TENSOR_OP_MATH using cublasSetMathMode. However, there are still some linear algebra operations in deep learning that cuBLAS needs full FP32 precision to preserve the numerics for training or inference. The frameworks have guards around such operations (for example, that are performing solver operations) and set the math mode back to CUBLAS_DEFAULT_MATH, which uses FP32 kernels.
cuSOLVER
cuSOLVER is primarily used for solver operations such as factorizations and dense linear solvers. Some of the deep learning frameworks use cuSOLVER from the CUDA toolkit. There is no need to change the default math operation, as it always uses the precision defined by the API call.
cuTENSOR
cuTENSOR is primarily used for tensor primitives such as contractions, reductions, and element-wise operations. The precision is always defined by the API call. With version 1.1.0 and greater, cuTENSOR supports TF32 Tensor Core operations through the compute type CUTENSOR_COMPUTE_TF32.
Rounding options
BF16 is introduced as Tensor Core math mode in cuBLAS 11.0 and as a numerical type in CUDA 11.0. Deep learning frameworks and AMP will support BF16 soon. Conversions between 16-bit and FP32 formats are typical when devising custom layers for mixed-precision training. We recommend using type casts or intrinsic functions, as shown in the following example. The appropriate header files cuda_fp16.h and cuda_bf16.h must be included.
#include <cuda_fp16.h> half a = (half)(1.5f); half b = (half)(1.0f); half c = a + b;
#include <cuda_bf16.h> nv_bfloat16 a = (nv_bfloat16)(1.5f); nv_bfloat16 b = (nv_bfloat16)(1.5f); nv_bfloat16 c = a + b;
Example: Sample CUDA code for converting two FP32 values to 16-bits (FP16 or BF16), adding them with 16-bit operations, and storing the result in a 16-bit register.
Global platform control
A100 introduces the global platform control to allow changes to the default math behavior for AI training. A global environment variable NVIDIA_TF32_OVERRIDE can be used to toggle TF32 mode at the system level, overriding programmatic settings in the libraries or frameworks (Table 3).
| NVIDIA_TF32_OVERRIDE=0 | Not Set |
| Disables all TF32 kernels from being used so that FP32 kernels will be used | Defaults to the library and framework settings |
The global variable is designed as a debugging tool when training goes wrong. It provides a quick way to rule out any concern regarding TF32 libraries and allows you to focus on other issues in the training script.
NVIDIA_TF32_OVERRIDE must be set before the application is launched, as the effect of any change after the application launch is unspecified. The variable affects only the mode of FP32 operations. Operations using FP64 or one of the 16-bit formats are not affected and continue to use those corresponding types.
Conclusion
This post briefly introduces the variety of precisions and Tensor Core capabilities that the NVIDIA Ampere GPU architecture offers for AI training. TensorFloat32 brings the performance of Tensor Cores to single-precision workloads, while mixed precision with a native 16-bit format (FP16/BF16) remains the fastest options for training deep neural networks. All options are available in the latest deep learning frameworks optimized for A100 GPUs. For more information about the various possibilities to train neural networks with Tensor Cores, see the following online talks:
