
Large language models (LLMs) are fundamentally changing the way we interact with computers. These models are being incorporated into a wide range of applications, from internet search to office productivity tools. They are advancing real-time content generation, text summarization, customer service chatbots, and question-answering use cases.
Today, LLM-powered applications are running predominantly in the cloud. However, many use cases that would benefit from running LLMs locally on Windows PCs, including gaming, creativity, productivity, and developer experiences.
AT CES 2024, NVIDIA announced several developer tools to accelerate LLM inference and development on NVIDIA RTX Systems for Windows PCs. You can now use NVIDIA end-to-end developer tools to create and deploy LLM applications on NVIDIA RTX AI-ready PCs.
Support for community models and native connectors
NVIDIA just announced optimized support for popular community models, including Phi-2, in addition to existing support for Llama2, Mistral-7B, and Code Llama on NVIDIA RTX systems. These models provide extensive developer choice, along with best-in-class performance using the NVIDIA TensorRT-LLM inference backend.
NVIDIA collaborated with the open-source community to develop native connectors for TensorRT-LLM to popular application frameworks such as LlamaIndex. These connectors offer seamless integration on Windows PCs to commonly used application development tools. View the example for the LlamaIndex implementation of the connector here.
We’ve also developed an OpenAI Chat API wrapper for TensorRT-LLM so that you can easily switch between running LLM applications on the cloud or on local Windows PCs by just changing one line of code. Now, you can use a similar workflow with the same popular community frameworks, whether they are designing applications in the cloud or on a local PC with NVIDIA RTX.
These latest advancements can now all be accessed through two recently launched open-source developer reference applications:
- A retrieval augmented generation (RAG) project running entirely on Windows PC with an NVIDIA RTX GPU and using TensorRT-LLM and LlamaIndex.
- A reference project that runs the popular continue.dev plugin entirely on a local Windows PC, with a web server for OpenAI Chat API compatibility.
RAG on Windows using TensorRT-LLM and LlamaIndex
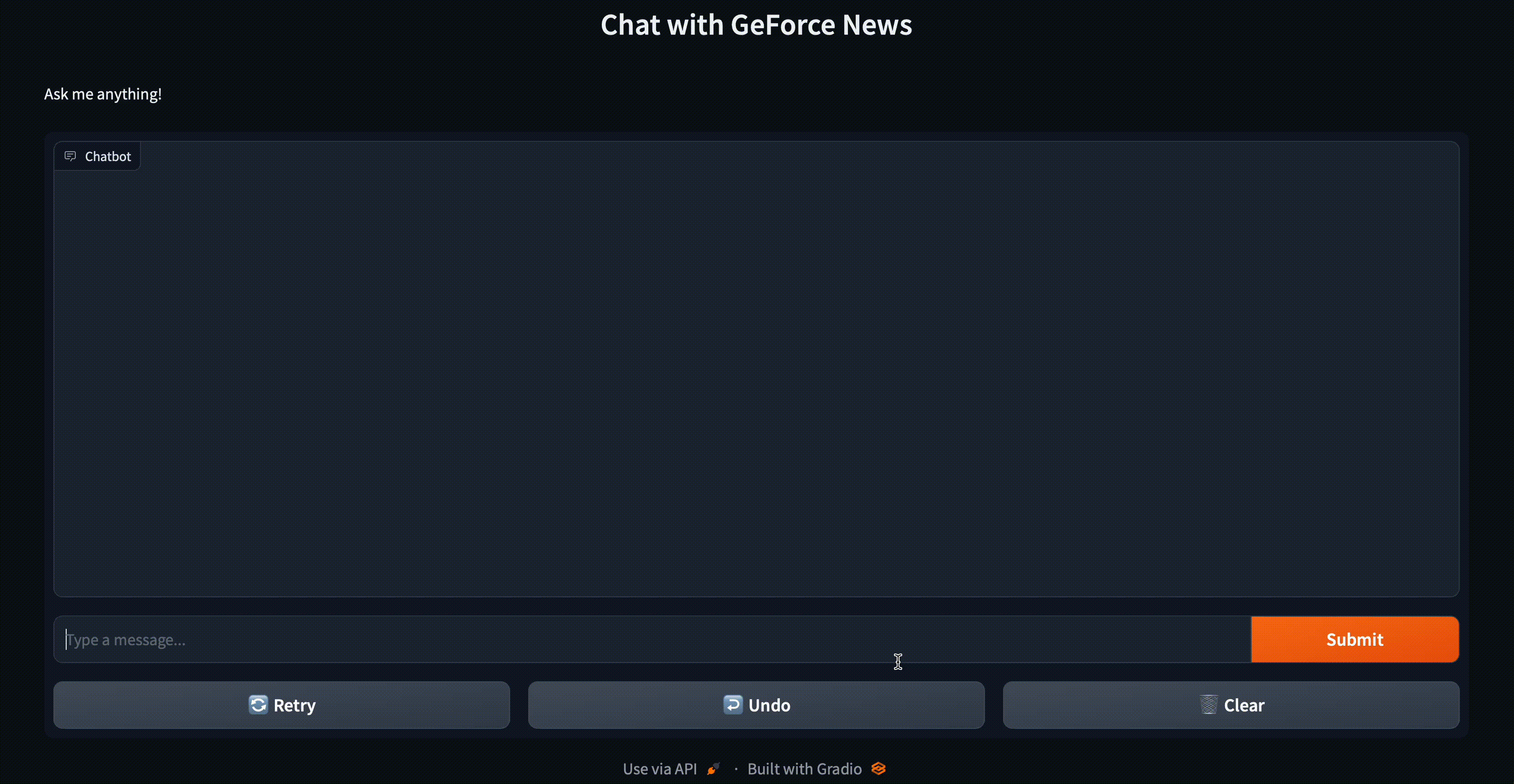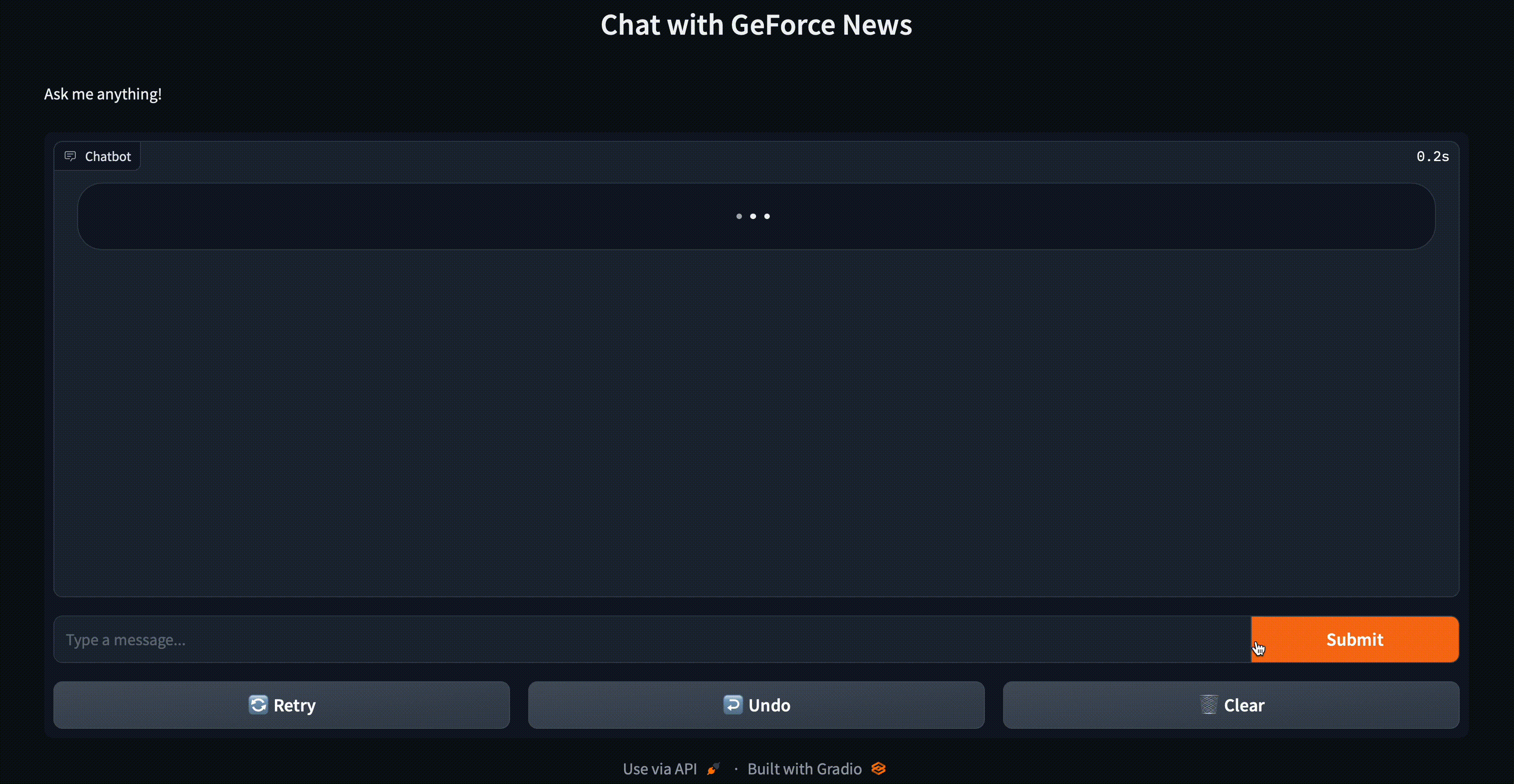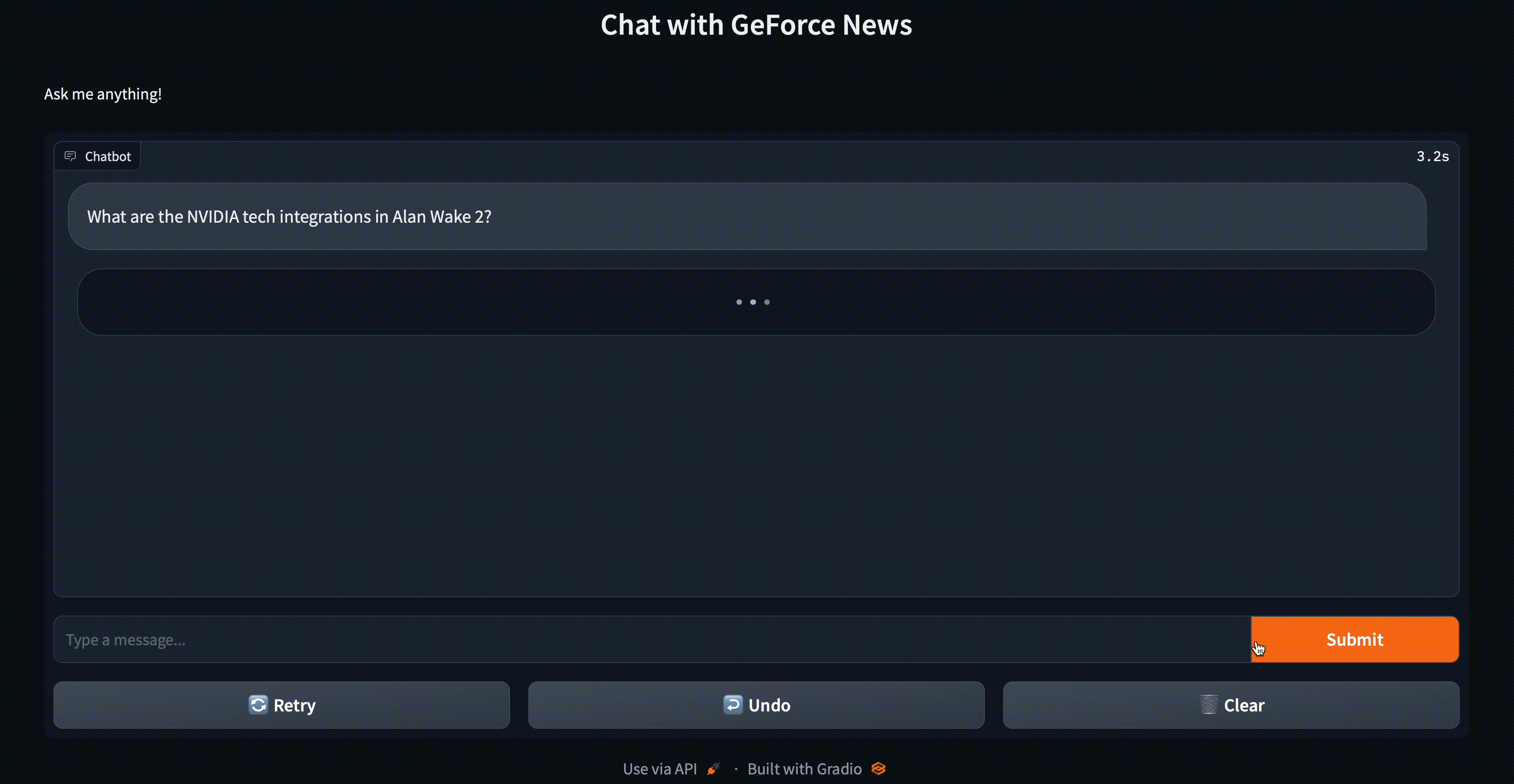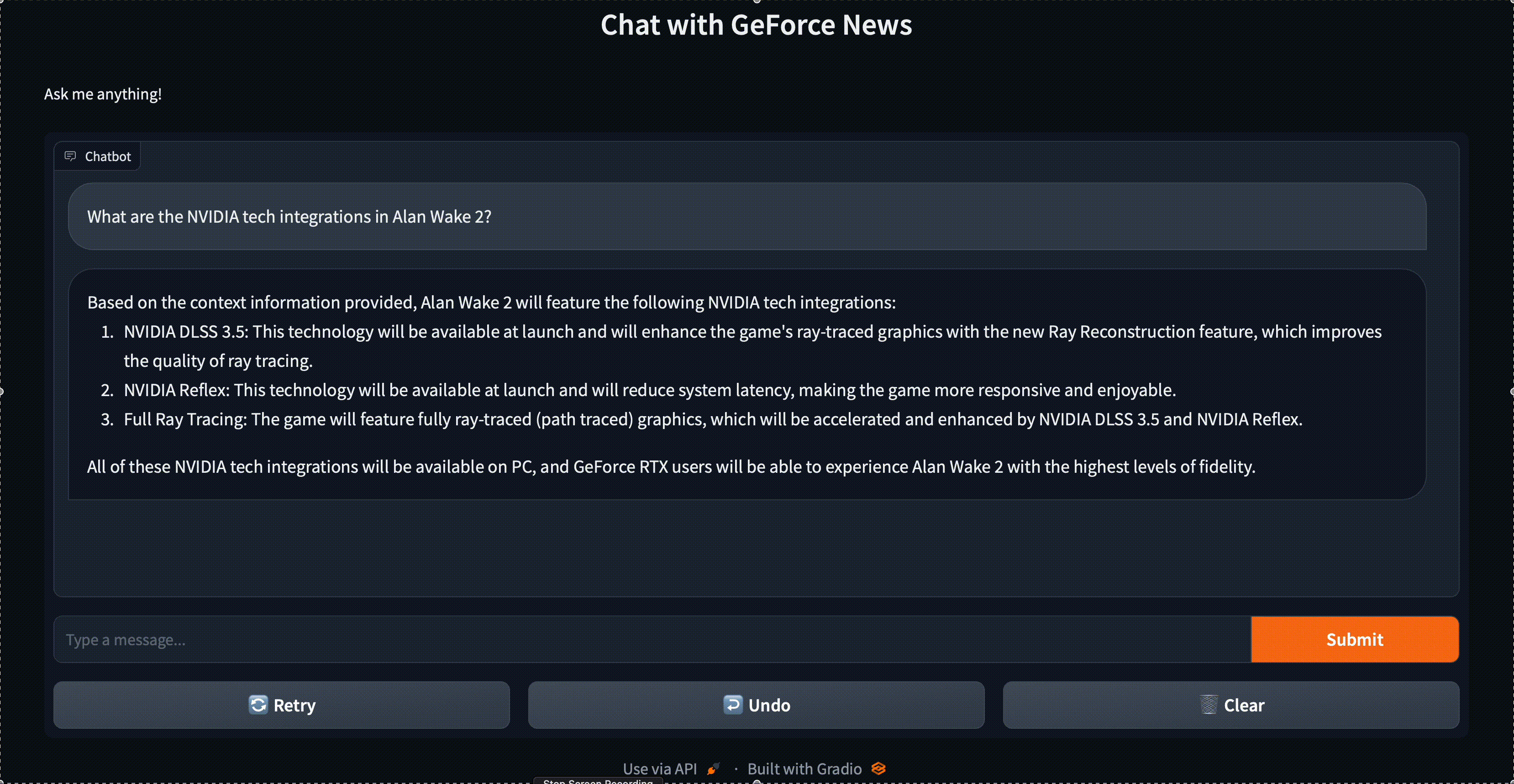
The RAG pipeline consists of the Llama-2 13B model, TensorRT-LLM, LlamaIndex, and the FAISS vector search library. You can now easily talk to your data with this reference application. Figure 1 shows a dataset that consists of NVIDIA GeForce News.
Get started with this application now.
Continue.dev Visual Studio Code extension on PC with CodeLlama-13B
Originally, the continue.dev plugin was designed to provide LLM-powered code assistance using ChatGPT in the cloud. It works natively with the Visual Studio Code integrated development environment. Using the OpenAI Chat API wrapper for TensorRT-LLM, with just one line of code change, this plugin now uses a Code Llama-13B model running locally on an NVIDIA RTX-enabled PC. This offers an easy path for fast, local LLM inferencing.
Try this reference project on GitHub now.
Benefits of running LLMs locally
Running LLMs locally on PCs offers several advantages:
- Cost: No cloud-hosted API or infrastructure costs for LLM inference. Directly access your compute resources.
- Always-on: Availability of LLM capabilities everywhere you go, without relying on high-bandwidth network connectivity.
- Performance: Latency is independent of network quality, offering lower latency as the entire model is running locally. This can be important for real-time use cases such as gaming or video conferencing. NVIDIA RTX offers the fastest PC accelerator with up to 1300 TOPS.
- Data privacy: Private and proprietary data can always stay on the device.
With over 100M systems shipped, NVIDIA RTX offers a large installed base of users for new LLM-powered applications.
Developer workflows for LLMs on NVIDIA RTX
You can now seamlessly run LLMs on NVIDIA RTX AI-ready PCs with the following options:
- Access pre-optimized models on HuggingFace, NGC, and NVIDIA AI Foundations.
- Train or customize models on custom data in NVIDIA DGX Cloud with NVIDIA NeMo Framework.
- Quantize and optimize the models for best performance on NVIDIA RTX with TensorRT-LLM.
This workflow is powered by the NVIDIA AI platform, alongside popular development tools such as NVIDIA AI Workbench to seamlessly migrate between cloud and PC.
AI Workbench provides you with the flexibility to collaborate on and migrate generative AI projects between GPU-enabled environments in just a few clicks. Projects can start locally on a PC or workstation and can then be scaled out anywhere for training: data center, public cloud, or NVIDIA DGX Cloud. You can then bring models back to a local NVIDIA RTX system for inference and lightweight customization with TensorRT-LLM.
AI Workbench will be released as a beta later this month.
Get started
With the latest updates, you can now use popular community models and frameworks in the same workflow to build applications that run either in the cloud or locally on Windows PC with NVIDIA RTX. Easily add LLM capabilities to applications powered by the existing 100M installed base of NVIDIA RTX PCs.
For more information about developing LLM-based applications and projects now, see Get Started with Generative AI Development on Windows PC with NVIDIA RTX Systems.
Have an idea for a generative AI-powered Windows app or plugin? Enter the NVIDIA Generative AI on NVIDIA RTX developer contest and you could win a GeForce RTX 4090 GPU, a full GTC in-person conference pass, and more.
