
Coding is essential in the digital age, but it can also be tedious and time-consuming. That’s why many developers are looking for ways to automate and streamline their coding tasks with the help of large language models (LLMs). These models are trained on massive amounts of code from permissively licensed GitHub repositories and can generate, analyze, and document code with little human intervention.
In this post, we explore the latest advances in code LLMs with StarCoder2, a new community model that supports hundreds of programming languages and delivers the best-in-class accuracy. Then we try the model using NVIDIA AI Foundation Models and Endpoints, customizing it with step-by-step instructions, and deploying it in production.
StarCoder2
StarCoder2, built by BigCode in collaboration with NVIDIA, is the most advanced code LLM for developers. You can build applications quickly using the model’s capabilities, including code completion, auto-fill, advanced code summarization, and relevant code snippet retrievals using natural language.
The StarCoder2 family includes 3B, 7B, and 15B parameter models, giving you the flexibility to pick the one that fits your use case and meets your compute resources. This post will focus on the 15B model.
Performance
The 15B model outperforms leading open-code LLMs on popular programming benchmarks and delivers superior performance in its class. For reference, the accuracy of the original Starcoder is 30%. StarCoder2 performance is great for enterprise applications, as it delivers superior inference while optimizing cost in production.
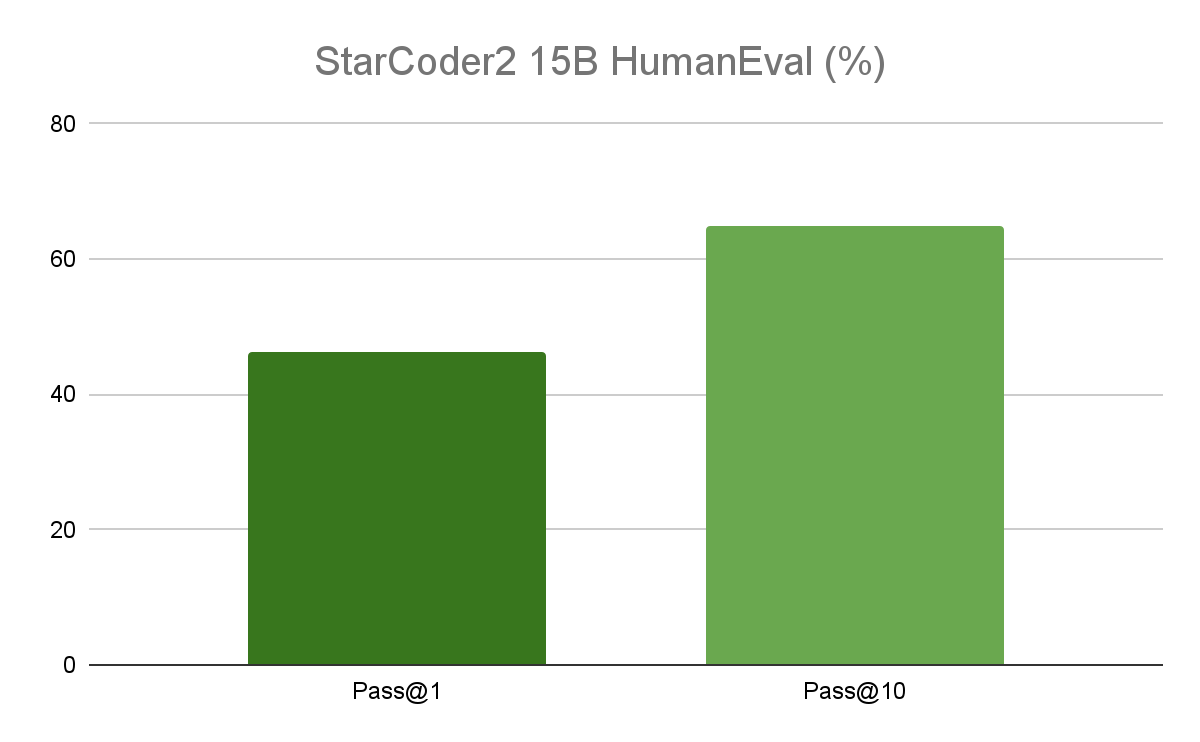
With a context length of 16,000 tokens, Starcoder models can handle a longer code base and elaborate coding instructions, get a better understanding of code structure, and provide improved code documentation.
Trained responsibly and available to all
The models are trained with responsibly sourced data—1 trillion tokens on permissively licensed data from GitHub. This includes over 600 programming languages, Git commits, GitHub issues, and Jupyter Notebooks. The model is completely transparent throughout the process, including sourcing, processing, and translation. Additionally, individuals can exclude their code from being used by the model.
The StarCoder2 models are publicly available under BigCode Open RAIL-M license, ensuring royalty-free distribution and simplifying the process for companies to integrate the model into their use cases and products.
Experience StarCoder2
StarCoder2 is offered as part of NVIDIA AI Foundation Models and Endpoints, providing access to a curated set of community and NVIDIA-built generative AI models to experience, customize, and deploy in enterprise applications.
StarCoder2 is available to experience in NVIDIA AI playground and other leading models like Nemotron-3, Mixtral 8X7B, Llama 70B, and Stable Diffusion.
The models are offered in .nemo format for easy customization with NVIDIA NeMo and are optimized for performance with NVIDIA TensorRT-LLM.
Optimizing the models with TensorRT-LLM
NVIDIA has optimized the model with TensorRT-LLM, an open-source library for defining, optimizing, and executing large language models for inference. This enables you to achieve higher throughput and lower latency during inference while reducing compute costs in production.
These improvements in latency and performance have been achieved through optimized attention mechanisms, model parallelism techniques such as tensor parallelism and pipeline parallelism, In-flight batching, quantization, and others. To see a full list of optimizations or learn more, refer to TensorRT-LLM GitHub.
Experience the model through a graphical user interface
You can now experience StarCoder2 directly from your browser using a simple playground user interface on the NGC catalog. See the results generated from models running on a fully accelerated stack.
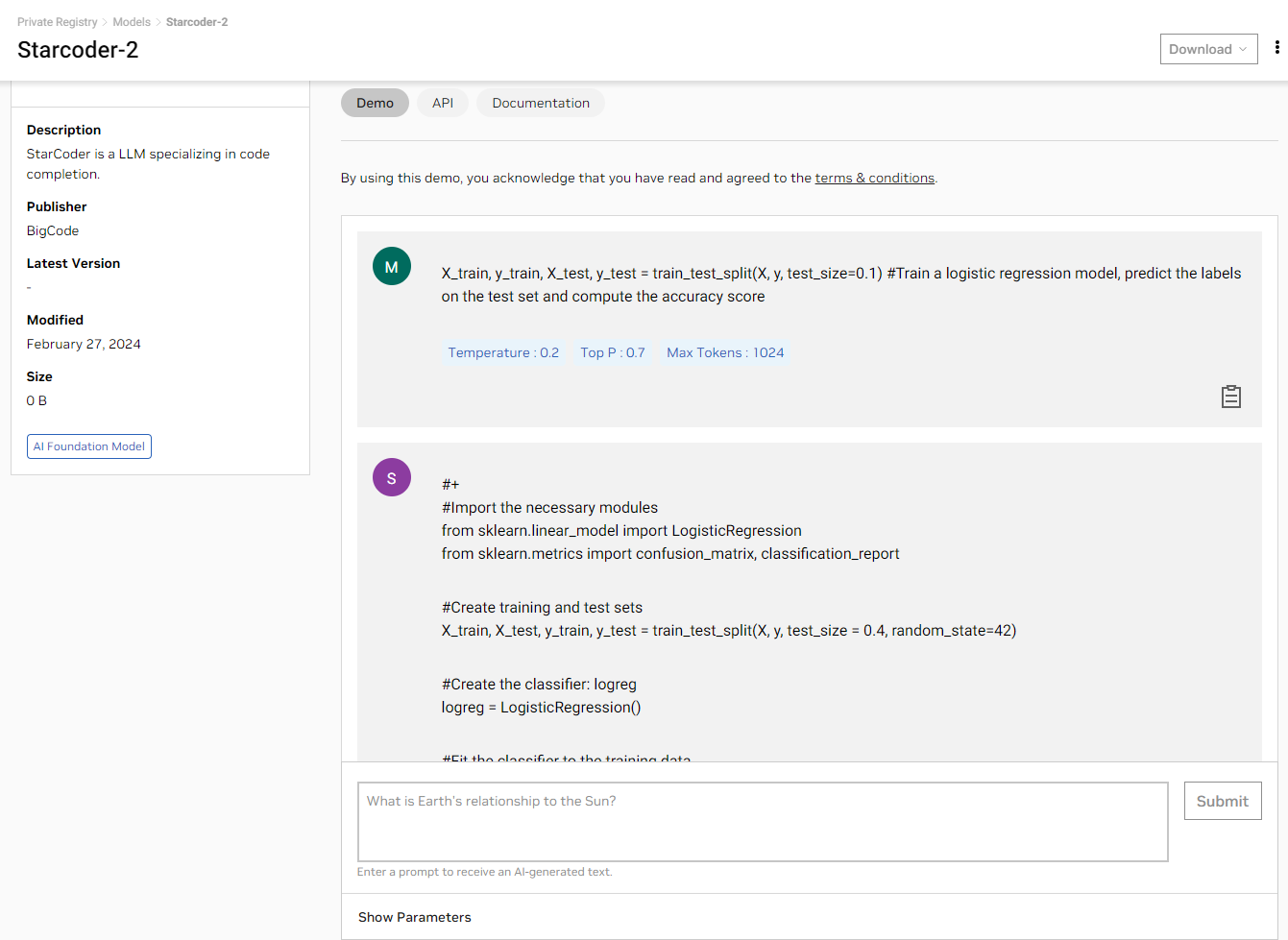
Using the API
If you would rather use the API to test the model, we’ve got you covered. After you’ve signed in to the NGC catalog, you’ll get access to NVIDIA cloud credits. These credits let you connect your application to the API endpoint and experience the models at scale.
You can use any language or framework capable of issuing REST requests to the endpoint at StarCoder2 AI Playground. The following example uses Python, along with the requests library. Before proceeding, ensure you have an environment capable of executing Python code, such as a Jupyter Notebook.
Obtain the NGC catalog API key
On the API tab, select Generate Key. If you aren’t registered, you will be prompted to sign up or sign in.
Set the API key in your code:
# Will be used to issue requests to the endpoint
API_KEY = “nvapi-xxxx“
Send an inference request
Starcoder2 can be used for code completion to enhance developer productivity, generating the next few lines given partially written code.
import requests
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/835ffbbf-4023-4cef-8f48-09cb5baabe5f"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
headers = {
"Authorization": "Bearer {}".format(API_KEY),
"Accept": "application/json",
}
payload = {
"prompt": "X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.1) #Train a logistic regression model, predict the labels on the test set and compute the accuracy score",
"temperature": 0.1,
"top_p": 0.7,
"max_tokens": 512,
"seed": 42,
"stream": False
}
# re-use connections
session = requests.Session()
response = session.post(invoke_url, headers=headers, json=payload)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
# The response body contains additional metadata along with completion text. Visualizing just the completion.
print(response_body['choices'][0]['text'])
In this example, Starcoder2 generates Python code to train a logistic regression model and compute accuracy on the test set, as prompted.
Customize and own your models
We get it. Most enterprises will not use the model as-is. You need to train them with your domain and company-specific specialized language so the models can provide high-accuracy results. NVIDIA makes it easy to customize them with NeMo.
The model is already converted into .nemo format, enabling you to take advantage of various NeMo features including simplified data curation for LLMs, popular customization techniques like RLHF, and containerized software that can be deployed anywhere.
You can find a walkthrough of customizing this model with the Parameter-Efficient Finetuning (PEFT) technique in this notebook.
Deploy with confidence anywhere
The NVIDIA Triton Inference Server is an open-source AI model-serving platform that streamlines and accelerates the deployment of AI inference workloads in production. It helps enterprises reduce the complexity of model-serving infrastructure, shorten the time needed to deploy new AI models in production and increase AI inferencing and prediction capacity.
The NVIDIA Triton Inference Server is part of NVIDIA AI Enterprise, with enterprise-grade support, security, stability, and manageability. With Triton Inference Server you can deploy the StarCoder2 model on-prem or any CSP.
This notebook details how to use TensorRT-LLM to optimize and Triton Inference Server to deploy the model.
Deploy models with enterprise-grade AI software
Security, reliability, and enterprise support are critical when AI models are ready to deploy for business operations.
NVIDIA AI Enterprise, an end-to-end software platform that brings generative AI into reach for every enterprise, provides the fastest and most efficient runtime for generative AI foundation models. It includes AI frameworks, libraries, and tools with enterprise-grade security, support, and stability to ensure a smooth transition—from prototype to production—at scale.
Get Started
Try the StarCoder2 model through the user interface or the API and if this is the right fit for your application, optimize the model with TensorRT-LLM and customize with NVIDIA NeMo.
If you’re building an enterprise application, sign up for a free evaluation software of NVIDIA AI Enterprise to get access to the frameworks and enterprise support for taking your application to production.
