
Virtual reality (VR), augmented reality (AR), and mixed reality (MR) environments can feel incredibly real due to the physically immersive experience. Adding a voice-based interface to your extended reality (XR) application can make it appear even more realistic.
Imagine using your voice to navigate through an environment or giving a verbal command and hearing a response back from a virtual entity.

The possibilities to harness speech AI in XR environments is fascinating. Speech AI skills, such as automatic speech recognition (ASR) and text-to-speech (TTS), make XR applications enjoyable, easy to use, and more accessible to users with speech impairments.
This post explains how speech recognition, also referred to as speech-to-text (STT), can be used in your XR app, what ASR customizations are available, and how to get started with running ASR services in your Windows applications.
Why add speech AI services to XR applications?
In most of today’s XR experiences, users don’t have access to a keyboard or mouse. The way VR game controllers typically interact with a virtual experience is clumsy and unintuitive, making navigation through menus difficult when you’re immersed in the environment.
When virtually immersed, we want our experience to feel natural, both in how we perceive it and in how we interact with it. Speech is one of the most common interactions that we use in the real world.
Adding speech AI-enabled voice commands and responses to your XR application makes interaction feel much more natural and dramatically simplifies the learning curve for users.
Examples of speech AI-enabled XR applications
Today, there are a wide array of wearable tech devices that enable people to experience immersive realities while using their voice:
- AR translation glasses can provide real-time translation in AR or just transcribe spoken audio in AR to help people with hearing impairments.
- Branded voices are customized and developed for digital avatars in the metaverse, making the experience more believable and realistic.
- Social media platforms provide voice-activated AR filters for ease of search and usability. For instance, Snapchat users can search for their desired digital filter using a hands-free voice scan feature.
VR design review
VR can help businesses save costs by automating a number of tasks in the automotive industry, such as modeling cars, training assembly workers, and driving simulations.
An added speech AI component makes hands-free interactions possible. For example, users can leverage STT skills to give commands to VR apps, and apps can respond in a way that sounds human with TTS.
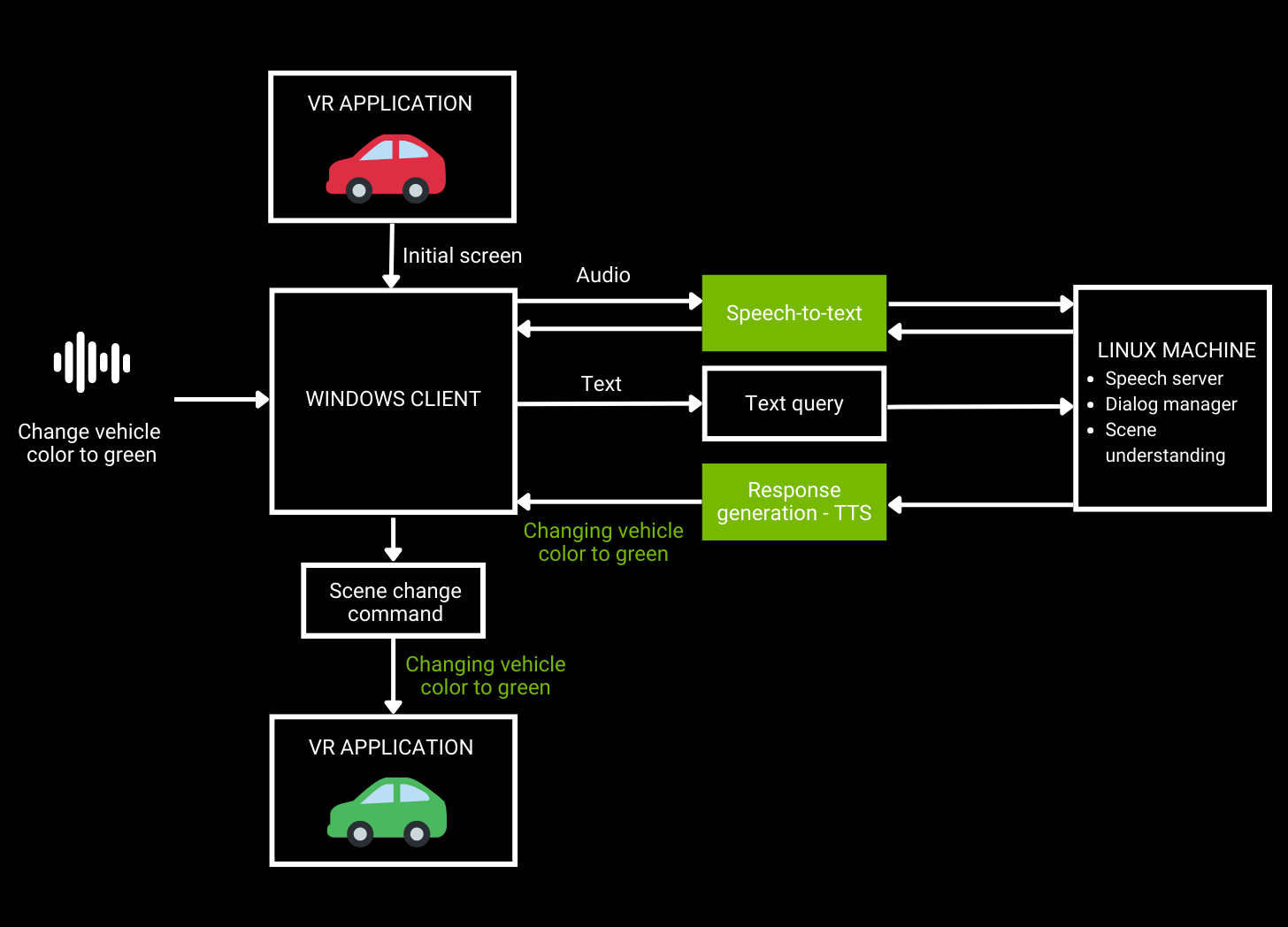
As shown in Figure 1, a user sends an audio request to a VR application that is then converted to text using ASR. Natural language understanding takes text as an input and generates a response, which is spoken back to the user using TTS.
Developing speech AI pipelines is not as easy as it sounds. Traditionally, there has always been a trade-off between accuracy and real-time response when building pipelines.
This post focuses solely on ASR, and we examine some of today’s available customizations for XR app developers. We also discuss using NVIDIA Riva, a GPU-accelerated speech AI SDK, for building applications customized for specific use cases while delivering real-time performance.
Solve domain– and language-specific challenges with ASR customizations
An ASR pipeline includes a feature extractor, acoustic model, decoder or language model, and punctuation and capitalization model (Figure 2).
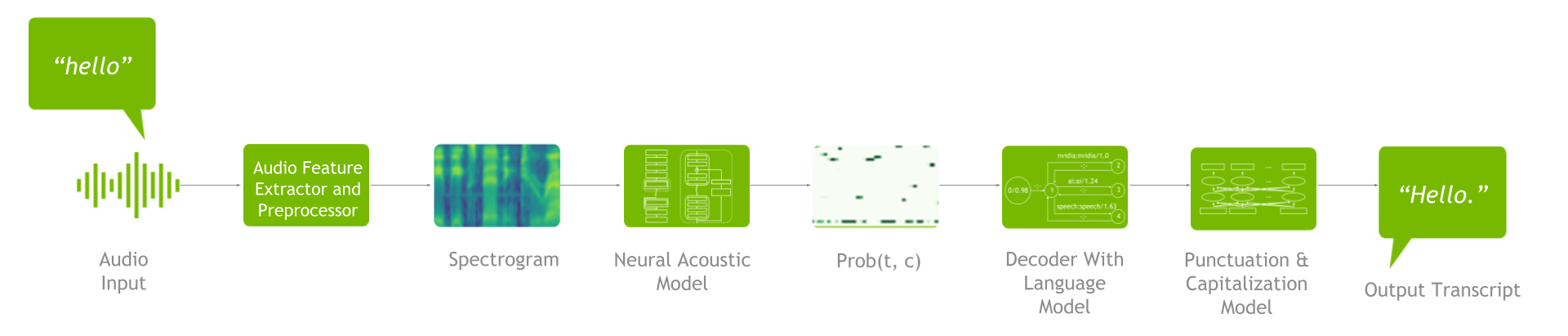
To understand the ASR customizations available, it’s important to grasp the end-to-end process. First, feature extraction takes place to turn raw audio waveforms into spectrograms / mel spectrograms. These spectrograms are then fed into an acoustic model that generates a matrix with probabilities for all the characters at each time step.
Next, the decoder, in conjunction with the language model, uses that matrix as an input to produce a transcript. You can then run the resulting transcript through the punctuation and capitalization model to improve readability.
Advanced speech AI SDKs and workflows, such as Riva, support speech recognition pipeline customization. Customization helps you address several language-specific challenges, such as understanding one or more of the following:
- Multiple accents
- Word contextualization
- Domain-specific jargon
- Multiple dialects
- Multiple languages
- Users in noisy environments
Customizations in Riva can be applied in both the training and inference stages. Starting with training-level customizations, you can fine-tune acoustic models, decoder/language models, and punctuation and capitalization models. This ensures that your pipeline understands different language, dialects, accents, and industry-specific jargon, and is robust to noise.
When it comes to inference-level customizations, you can use word boosting. With word boosting, the ASR pipeline is more likely to recognize certain words of interest by giving them a higher score when decoding the output of the acoustic model.
Get started with integrating ASR services for XR development using NVIDIA Riva
Riva runs as a client-server model. To run Riva, you need access to a Linux server with an NVIDIA GPU, where you can install and run the Riva server (specifics and instructions are provided in this post).
The Riva client API is integrated into your Windows application. At runtime, the Windows client sends Riva requests over the network to the Riva server, and the Riva server sends back replies. A single Riva server can simultaneously support many Riva clients.
ASR services can be run in two different modes:
- Offline mode: A complete speech segment is captured, and when complete it is then sent to Riva to be converted to text.
- Streaming mode: The speech segment is being streamed to the Riva server in real time, and the text result is being streamed back in real time. Streaming mode is a bit more complicated, as it requires multiple threads.
Examples showing both modes are provided later in this post.
In this section, you learn several ways to integrate Riva into your Windows application:
- Python ASR offline client
- Python streaming ASR client
- C++ offline client using Docker
- C++ streaming client
First, here’s how to set up and run the Riva server.
Prerequisites
- Access to NGC. For step-by-step instructions, see the NGC Getting Started Guide
- Follow all steps to be able to run
ngccommands from a command-line interface (CLI).
- Follow all steps to be able to run
- Access to NVIDIA Volta, NVIDIA Turing, or an NVIDIA Ampere Architecture-based A100 GPU. Linux servers with NVIDIA GPUs are also available from the major CSPs. For more information, see the support matrix.
- Docker installation with support for NVIDIA GPUs. For more information about instructions, see the installation guide.
- Follow the instructions to install the NVIDIA Container Toolkit and then the
nvidia-dockerpackage.
- Follow the instructions to install the NVIDIA Container Toolkit and then the
Server setup
Download the scripts from NGC by running the following command:
ngc registry resource download-version nvidia/riva/riva_quickstart:2.4.0
Initialize the Riva server:
bash riva_init.sh
Start the Riva server:
bash riva_start.sh
For more information about the latest updates, see the NVIDIA Riva Quick Start Guide.
Running the Python ASR offline client
First, run the following command to install the riva client package. Make sure that you’re using Python version 3.7.
pip install nvidia-riva-client
The following code example runs ASR transcription in offline mode. You must change the server address, give the path to the audio file to be transcribed, and select the language code for your choice. Currently, Riva supports English, Spanish, German, Russian, and Mandarin.
import io
import IPython.display as ipd
import grpc
import riva.client
auth = riva.client.Auth(uri='server address:port number')
riva_asr = riva.client.ASRService(auth)
# Supports .wav file in LINEAR_PCM encoding, including .alaw, .mulaw, and .flac formats with single channel
# read in an audio file from local disk
path = "audio file path"
with io.open(path, 'rb') as fh:
content = fh.read()
ipd.Audio(path)
# Set up an offline/batch recognition request
config = riva.client.RecognitionConfig()
#req.config.encoding = ra.AudioEncoding.LINEAR_PCM # Audio encoding can be detected from wav
#req.config.sample_rate_hertz = 0 # Sample rate can be detected from wav and resampled if needed
config.language_code = "en-US" # Language code of the audio clip
config.max_alternatives = 1 # How many top-N hypotheses to return
config.enable_automatic_punctuation = True # Add punctuation when end of VAD detected
config.audio_channel_count = 1 # Mono channel
response = riva_asr.offline_recognize(content, config)
asr_best_transcript = response.results[0].alternatives[0].transcript
print("ASR Transcript:", asr_best_transcript)
print("\n\nFull Response Message:")
print(response)
Running the Python streaming ASR client
To run an ASR streaming client, clone the riva python-clients repository and run the file that comes with the repository.
To get the ASR streaming client to work on Windows, clone the repository by running the following command:
git clone https://github.com/nvidia-riva/python-clients.git
From the python-clients/scripts/asr folder, run the following command:
python transcribe_mic.py --server=server address:port number
Here’s the transcribe_mic.py:
import argparse
import riva.client
from riva.client.argparse_utils import add_asr_config_argparse_parameters, add_connection_argparse_parameters
import riva.client.audio_io
def parse_args() -> argparse.Namespace:
default_device_info = riva.client.audio_io.get_default_input_device_info()
default_device_index = None if default_device_info is None else default_device_info['index']
parser = argparse.ArgumentParser(
description="Streaming transcription from microphone via Riva AI Services",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
parser.add_argument("--input-device", type=int, default=default_device_index, help="An input audio device to use.")
parser.add_argument("--list-devices", action="store_true", help="List input audio device indices.")
parser = add_asr_config_argparse_parameters(parser, profanity_filter=True)
parser = add_connection_argparse_parameters(parser)
parser.add_argument(
"--sample-rate-hz",
type=int,
help="A number of frames per second in audio streamed from a microphone.",
default=16000,
)
parser.add_argument(
"--file-streaming-chunk",
type=int,
default=1600,
help="A maximum number of frames in a audio chunk sent to server.",
)
args = parser.parse_args()
return args
def main() -> None:
args = parse_args()
if args.list_devices:
riva.client.audio_io.list_input_devices()
return
auth = riva.client.Auth(args.ssl_cert, args.use_ssl, args.server)
asr_service = riva.client.ASRService(auth)
config = riva.client.StreamingRecognitionConfig(
config=riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
language_code=args.language_code,
max_alternatives=1,
profanity_filter=args.profanity_filter,
enable_automatic_punctuation=args.automatic_punctuation,
verbatim_transcripts=not args.no_verbatim_transcripts,
sample_rate_hertz=args.sample_rate_hz,
audio_channel_count=1,
),
interim_results=True,
)
riva.client.add_word_boosting_to_config(config, args.boosted_lm_words, args.boosted_lm_score)
with riva.client.audio_io.MicrophoneStream(
args.sample_rate_hz,
args.file_streaming_chunk,
device=args.input_device,
) as audio_chunk_iterator:
riva.client.print_streaming(
responses=asr_service.streaming_response_generator(
audio_chunks=audio_chunk_iterator,
streaming_config=config,
),
show_intermediate=True,
)
if __name__ == '__main__':
main()
Running the C++ ASR offline client using Docker
Here’s how to run a Riva ASR offline client using Docker in C++.
Clone the /cpp-clients GitHub repository by running the following command:
git clone https://github.com/nvidia-riva/cpp-clients.git
Build the Docker image:
DOCKER_BUILDKIT=1 docker build . –tag riva-client
Run the Docker image:
docker run -it --net=host riva-client
Start the Riva speech recognition client:
Riva_asr_client –riva_url server address:port number –audio_file audio_sample
Running the C++ ASR streaming client
To run the ASR streaming client riva_asr in C++, you must first compile the cpp sample. It is straightforward using CMake, after the following dependencies are met:
gflagsgloggrpcrtaudiorapidjsonprotobufgrpc_cpp_plugin
Create a folder /build within the root source folder. From the terminal, type cmake .. and then make. For more information, see the readme file included in the repository.
After the sample is compiled, run it by entering the following command:
riva_asr.exe --riva_uri={riva server url}:{riva server port} --audio_device={Input device name, e.g. "plughw:PCH,0"}
riva_uri: Theaddress:portvalue of therivaserver. By default, therivaserver listens to port 50051.audio_device: The input device (microphone) to be used.
The sample implements essentially four steps. Only a few short examples are shown in this post. For more information, see the file streaming_recognize_client.cc.
Open the input stream using the input (microphone) device specified from the command line. In this case, you are using one channel at 16K samples per second and 16 bits per sample.
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
nr::AudioEncoding encoding = nr::LINEAR_PCM;
adc.setErrorCallback(rtErrorCallback);
RtAudio::StreamParameters parameters;
parameters.nChannels = 1;
parameters.firstChannel = 0;
unsigned int sampleRate = 16000;
unsigned int bufferFrames = 1600; // (0.1 sec of rec) sample frames
RtAudio::StreamOptions streamOptions;
streamOptions.flags = RTAUDIO_MINIMIZE_LATENCY;
…
RtAudioErrorType error = adc.openStream( nullptr, ¶meters, RTAUDIO_SINT16, sampleRate, &bufferFrames, &MicrophoneCallbackMain, static_cast<void*>(&uData), &streamOptions);
Open the grpc communication channel with the Riva server using the protocol api interface specified by the .proto files (in the source in the folder riva/proto):
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
…
std::shared_ptr<ClientCall> call = std::make_shared<ClientCall>(1, word_time_offsets_);
call->streamer = stub_->StreamingRecognize(&call->context);
// Send first request
nr_asr::StreamingRecognizeRequest request;
auto streaming_config = request.mutable_streaming_config();
streaming_config->set_interim_results(interim_results_);
auto config = streaming_config->mutable_config();
config->set_sample_rate_hertz(sampleRate);
config->set_language_code(language_code_);
config->set_encoding(encoding);
config->set_max_alternatives(max_alternatives_);
config->set_audio_channel_count(parameters.nChannels);
config->set_enable_word_time_offsets(word_time_offsets_);
config->set_enable_automatic_punctuation(automatic_punctuation_);
config->set_enable_separate_recognition_per_channel(separate_recognition_per_channel_);
config->set_verbatim_transcripts(verbatim_transcripts_);
if (model_name_ != "") {
config->set_model(model_name_);
}
call->streamer->Write(request);
Start sending audio data, received by the microphone to riva through grpc messages:
static int MicrophoneCallbackMain( void *outputBuffer, void *inputBuffer, unsigned int nBufferFrames, double streamTime, RtAudioStreamStatus status, void *userData )
Receive the transcribed audio through grpc answers from the server:
void
StreamingRecognizeClient::ReceiveResponses(std::shared_ptr<ClientCall> call, bool audio_device)
{
…
while (call->streamer->Read(&call->response)) { // Returns false when no m ore to read.
call->recv_times.push_back(std::chrono::steady_clock::now());
// Reset the partial transcript
call->latest_result_.partial_transcript = "";
call->latest_result_.partial_time_stamps.clear();
bool is_final = false;
for (int r = 0; r < call->response.results_size(); ++r) {
const auto& result = call->response.results(r);
if (result.is_final()) {
is_final = true;
}
…
call->latest_result_.audio_processed = result.audio_processed();
if (print_transcripts_) {
call->AppendResult(result);
}
}
if (call->response.results_size() && interim_results_ && print_transcripts_) {
std::cout << call->latest_result_.final_transcripts[0] +
call->latest_result_.partial_transcript
<< std::endl;
}
call->recv_final_flags.push_back(is_final);
}
Resources for developing speech AI applications
By recognizing your voice or carrying out a command, speech AI is expanding from empowering actual humans in contact centers to empowering digital humans in the metaverse.
Related resources
Access beginner and advanced scripts in the /nvidia-riva/tutorials GitHub repo to try out ASR and TTS augmentations such as ASR word boosting and adjusting TTS pitch, rate, and pronunciation settings.
The best way to gain expertise in speech AI is to experience it. For more information about how to build and deploy real-time speech AI pipelines for your conversational AI application, see the free Building Speech AI Applications ebook (registration required).
Explore how speech AI can be used in graphic-based XR applications with an on-demand video session, Powering the Next Generation of XR and Gaming Applications with Speech AI.
For more information about how businesses are deploying Riva in production to improve their services, see the customer stories in Solution Showcase.